Mustererkennung (Pattern Recognition)
Was ist Mustererkennung (Pattern Recognition)?
Mustererkennung (Pattern Recognition) ist die Fähigkeit, Anordnungen von Merkmalen in Daten zu erkennen, die Informationen über ein bestimmtes System oder einen bestimmten Datensatz liefern. Mustererkennung ist eine der Hauptfähigkeiten des maschinellen Lernens (ML), der Datenanalyse und der künstlichen Intelligenz (KI).
Im technologischen Kontext ist ein Muster eine wiederkehrende Sequenz oder ein Aspekt in Daten, der für Vorhersagen genutzt werden kann. Diese Muster können einfache Beziehungen zwischen Variablen sein oder komplexe, vielschichtige Beziehungen, die mehrere Variablen nutzen. Mustererkennung nutzt Computer und Algorithmen, um anhand der versteckten Beziehungen innerhalb von Daten Vorhersagen zu treffen.
Ein einfaches Beispiel für Mustererkennung ist ein Algorithmus, der versucht, das Geschlecht einer Person anhand ihres Einkaufsverhaltens zu bestimmen. Diese Vorhersage kann dann in ein anderes System eingespeist werden, um Empfehlungen für zukünftige Käufe zu geben.
Wenn der Prozess zu einer falschen Vorhersage führt oder etwas falsch klassifiziert, spricht man von einem Vorhersagefehler.
Wo wird Mustererkennung eingesetzt?
Mustererkennung ist eine der leistungsfähigsten Fertigkeiten der Mathematik und Computer. Sie findet in fast allen Bereichen der modernen Wissenschaft, Technologie und Industrie Anwendung.
Sie lässt sich einsetzen, um Trends vorherzusagen, bestimmte Merkmale in Bildern zu finden, die Objekte identifizieren, häufige Kombinationen von Wörtern und Phrasen für die natürliche Sprachverarbeitung (Natural Language Processing, NLP) zu erkennen oder bestimmte Verhaltenscluster in einem Netzwerk zu lokalisieren, die auf einen Angriff hindeuten können – neben unzähligen anderen Fähigkeiten.
Mustererkennung ist für viele sich überschneidende Bereiche der IT unverzichtbar, darunter Big-Data-Analytik, biometrische Authentifizierung, IT-Sicherheit und künstliche Intelligenz.
Einige Beispiele für Mustererkennung sind:
- Gesichtserkennungssoftware erfasst Daten zu den Merkmalen eines Gesichts und gleicht dieses spezifische Muster mithilfe eines Algorithmus mit einem individuellen Datensatz in einer Datenbank ab.
- Mustererkennungsalgorithmen in Wettervorhersagesoftware können wiederkehrende Zusammenhänge zwischen Wetterdaten erkennen, die sich zur Vorhersage wahrscheinlicher zukünftiger Wetterereignisse verwenden lassen.
- Intrusion-Detection-Systeme (IDS) und Threat-Intelligence-Software beschreiben Verhaltensmuster und Ereignisse, die auf unzulässigen Netzwerkverkehr hinweisen können.
- Maschinelles Sehen nutzt Mustererkennung, um die Aufnahmen einer Kamera zu klassifizieren. Ein einfaches System für den industriellen Einsatz kann für einen bestimmten Zweck trainiert werden, beispielsweise um festzustellen, ob ein Apfel reif ist oder nicht. Ein komplexeres System kann trainiert werden, um viele Objekte in einem Live-Videostream zu erkennen und zu klassifizieren.
- Buchhaltungs- und Finanzsysteme können Mustererkennung nutzen, um Verkaufsdaten oder Ausgaben zu prognostizieren. Andere Systeme können betrügerische Aktivitäten auf einem Konto erkennen.
- Large Language Models (LLM) basieren im Kern auf Mustererkennung. Sie verwenden sehr große Datensätze, um versteckte Beziehungen zwischen Wörtern zu finden, und nutzen diese, um auf der Grundlage einer bestimmten Eingabe eine Vorhersage darüber zu treffen, welches Wort als nächstes verwendet werden soll.
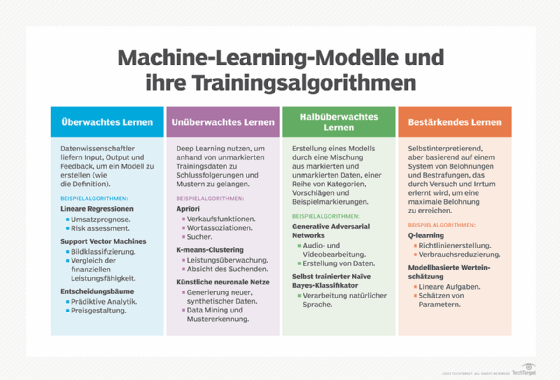
Wie funktioniert Mustererkennung?
Es gibt unzählige Methoden der Mustererkennung, die jedoch grob in überwachtes Lernen und unüberwachtes Lernen unterteilt werden.
Beim überwachten Lernen werden vorab gekennzeichnete und strukturierte Daten verwendet, um bestimmte Ergebnisse zu erzielen. Beim unüberwachten Lernen sind die Trainingsdaten unorganisiert und das System wird verwendet, um wichtige Merkmale zu identifizieren.
Einige Methoden verwenden Teile beider Ansätze, was als halbüberwachtes Lernen bezeichnet wird. Beim bestärkenden Lernen wird das Modell weiter verfeinert, indem es bei guten oder schlechten Ergebnissen Feedback vom Benutzer erhält.
Bei der Entwicklung eines Mustererkennungssystems werden in der Regel mehrere Schritte durchgeführt:
- Datenerfassung: Informationen werden gesammelt, sortiert und vorverarbeitet.
- Merkmalsextraktion: Wichtige Merkmale der Daten werden identifiziert und anschließend für Vorhersagen verwendet.
- Klassifizierung: Die extrahierten Merkmale werden analysiert, um die erforderlichen Beziehungen zu finden und Vorhersagen zu treffen.
Weitere Nachbearbeitungs- und Verfeinerungsstufen können angewendet werden.
Statistische Methoden verwenden Mathematik, um die Eingaben zu erkennen und zu klassifizieren. Bei numerischen Daten kann es sich um einfache lineare oder logistische Regression handeln. Andere Daten können in Vektoren umgewandelt werden, die sich mathematisch verarbeiten lassen.
Neuronale Netze führen Mustererkennung durch, indem sie einen neuronalen Pfad simulieren. Eine Entscheidung wird als Beziehung zwischen den Knoten im Netzwerk gespeichert.
Bei Clustering-Methoden werden Ähnlichkeiten in bestimmten Attributen gefunden, die zur Identifizierung von Untergruppen verwendet werden können.
Bei syntaktischen Methoden werden die Beziehungen und Hierarchien zwischen den Daten genutzt, was Regeln oder Entscheidungsbäume sein können. Dies ähnelt der Syntax einer Sprache, die beschreibt, wie Wörter gruppiert werden.
In Fuzzy-Systemen wird ein Grad an Unsicherheit im Prozess beibehalten. Die Ausgabe kann mehrere oder unvollständige Übereinstimmungen zulassen. Das kann in Situationen hilfreich sein, in denen die Daten unklar oder organischer Natur sind.
Die Template-Matching-Methode ist die einfachste Methode. Es werden Regeln entwickelt und angewendet, welche Attribute welcher Ausgabe entsprechen.
Erfahren Sie mehr über IT-Berufe und Weiterbildung
-
![]()
KI und die Einsatzbereiche in der IT-Sicherheit
Von: Pantelis Astenburg
-
![]()
Kann künstliche Intelligenz Naturkatastrophen vorhersagen?
Von: Damon Garn
-
![]()
Convolutional versus Recurrent Neural Networks: ein Vergleich
Von: David Petersson
-
![]()
Erkennung benannter Entitäten (Named Entity Recognition, NER)
Von: Nick Barney



