Erkennung benannter Entitäten (Named Entity Recognition, NER)
Was ist die Erkennung benannter Entitäten (Named Entity Recognition, NER)?
Die Erkennung benannter Entitäten (Named Entity Recognition, NER) ist eine Methode des Natural Language Processings (NLP), die Informationen aus Text extrahiert. NER umfasst das Erkennen und Kategorisieren wichtiger Informationen in Text, die als benannte Entitäten (Named Entity) bezeichnet werden. Benannte Entitäten beziehen sich auf die Schlüsselthemen eines Textes, wie Namen, Orte, Unternehmen, Ereignisse und Produkte, sowie auf Themen, Inhalte, Zeiten, Geldwerte und Prozentsätze.
Die Erkennung benannter Entitäten wird auch als Entitätenextraktion, Chunking und Identifizierung bezeichnet. Es wird in vielen Bereichen der künstlichen Intelligenz (KI) eingesetzt, darunter maschinelles Lernen (ML), Deep Learning und neuronale Netze. NER ist eine Schlüsselkomponente von NLP-Systemen wie Chatbots, Tools zur Stimmungsanalyse und Suchmaschinen. Es wird im Gesundheitswesen, im Finanzwesen, im Personalwesen, im Kundendienst, im Hochschulwesen und in der Analyse sozialer Medien eingesetzt.

Was ist der Zweck der Erkennung benannter Entitäten?
Die Erkennung benannter Entitäten identifiziert, kategorisiert und extrahiert die wichtigsten Informationen aus unstrukturiertem Text, ohne dass eine zeitaufwendige menschliche Analyse erforderlich ist. Sie ist besonders nützlich, um schnell Schlüsselinformationen aus großen Datenmengen zu extrahieren, da sie den Extraktionsprozess automatisiert.
Die Erkennung benannter Entitäten liefert Organisationen wichtige Erkenntnisse über ihre Kunden, Produkte, den Wettbewerb und Markttrends. Unternehmen nutzen es beispielsweise, um zu erkennen, wann sie in Publikationen erwähnt werden. Gesundheitsdienstleister nutzen es, um wichtige medizinische Informationen aus Patientenakten zu extrahieren.
Da NER-Modelle ihre Fähigkeit verbessern, wichtige Informationen korrekt zu identifizieren, tragen sie zur Verbesserung von KI-Systemen im Allgemeinen bei. Diese Systeme verbessern die Sprachverständnisfähigkeiten von KI in Bereichen wie Zusammenfassungs- und Übersetzungssystemen sowie die Fähigkeit von KI-Systemen, Text zu analysieren.
Wie funktioniert die Erkennung benannter Entitäten?
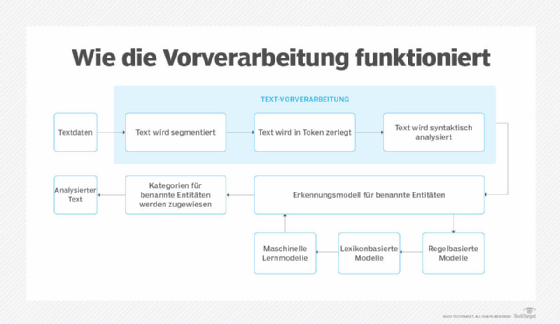
Die Erkennung benannter Entitäten verwendet Algorithmen, die auf Grammatik, statistischen NLP-Modellen und Vorhersagemodellen basieren. Diese Algorithmen werden anhand von Datensätzen trainiert, die mit vordefinierten Kategorien für benannte Entitäten wie Personen, Orte, Organisationen, Ausdrücke, Prozentsätze und Geldwerte gekennzeichnet sind. Kategorien werden mit Abkürzungen identifiziert; beispielsweise wird ORT für Ort, PER für Personen und ORG für Organisationen verwendet.
Nach dem Training mit Textdaten und Entitätstypen analysiert ein NER-Lernmodell automatisch neuen unstrukturierten Text und kategorisiert benannte Entitäten und semantische Bedeutungen auf der Grundlage seines Trainings. Wenn die Informationskategorie eines Textabschnitts erkannt wird, extrahiert ein Dienstprogramm zur Informationsextraktion die zugehörigen Informationen der benannten Entität und erstellt ein maschinenlesbares Dokument, das von anderen Tools verarbeitet werden kann, um die Bedeutung zu extrahieren.
Welche vier Arten der Erkennung benannter Entitäten gibt es?
Die vier am häufigsten verwendeten Arten von NER-Systemen sind:
- Überwachte Machine-Learning-Systeme verwenden Modelle, die auf Texten trainiert werden, die von Menschen mit Kategorien für benannte Entitäten vorgekennzeichnet wurden. Überwachte maschinelle Lernansätze verwenden Algorithmen wie bedingte Zufallsfelder und maximale Entropie, zwei komplexe statistische Sprachmodelle. Diese Methode ist effektiv für die Analyse semantischer Bedeutungen und anderer Komplexitäten, erfordert jedoch große Mengen an Trainingsdaten.
- Regelbasierte Systeme verwenden Regeln, um Informationen zu extrahieren. Regeln können Groß- und Kleinschreibung oder Titel wie Dr. enthalten. Diese Methode erfordert viel menschliches Eingreifen, um die Regeln einzugeben, zu überwachen und anzupassen, und es können Textvariationen übersehen werden, die nicht in den Trainingsanmerkungen enthalten sind. Es wird angenommen, dass regelbasierte Systeme Komplexität nicht so gut handhaben können wie maschinelle Lernmodelle.
- Wörterbuchbasierte Systeme verwenden ein Wörterbuch mit einem umfangreichen Vokabular und einer Synonymsammlung, um benannte Entitäten zu überprüfen und zu identifizieren. Diese Methode kann bei der Klassifizierung benannter Entitäten mit unterschiedlichen Schreibweisen Probleme bereiten.
- Deep-Learning-Systeme sind die genauesten der vier. Die Verwendung neuronaler Netze, wie zum Beispiel rekurrenter neuronaler Netze und Transformer-Architekturen, zur Untersuchung der Syntax und Semantik von Satzstrukturen. Dieser Ansatz gilt als Verbesserung gegenüber dem traditionellen maschinellen Lernen, da er große Textdatensätze besser verarbeiten und Merkmale und Attribute von Eingabedaten automatisch erlernen kann.
Methoden der Erkennung benannter Entitäten
Es gibt mehrere Methoden zur Implementierung von NER. Jede ist eine Art von Tool, das für die Ausführung bestimmter NER-Aufgaben trainiert wurde. Sie lassen sich am besten wie folgt beschreiben:
- Unüberwachte maschinelle Lernsysteme. Diese Modelle verwenden ML-Systeme, die nicht bereits auf gelabelte Textdaten vortrainiert sind. Unüberwachte Lernmodelle sollen in der Lage sein, komplexere NER-Aufgaben zu verarbeiten als überwachte Systeme.
- Bootstrapping-Systeme. Diese Systeme, die auch als selbstüberwachte Systeme bezeichnet werden, kategorisieren benannte Entitäten auf der Grundlage grammatikalischer Merkmale wie Großschreibung, Wortarten und anderer vorab trainierter und vordefinierter Kategorien. Eine Person nimmt dann eine Feinabstimmung des Bootstrap-Systems vor, indem sie dessen Vorhersagen als richtig oder falsch kennzeichnet und die richtigen Vorhersagen einem neuen Trainingssatz hinzufügt.
- Neuronale Netzwerksysteme. Diese erstellen ein NER-Modell unter Verwendung neuronaler Netze, bidirektionaler Architekturlernmodelle, wie zum Beispiel Bidirectional Encoder Representations from Transformers (BERT), und Kodierungstechniken. Dieser Ansatz minimiert die menschliche Interaktion.
- Statistische Systeme. Diese Systeme verwenden probabilistische Modelle, die auf Textmustern und -beziehungen trainiert sind, um benannte Entitäten in neuen Eingabetextdaten vorherzusagen.
- Semantische Rollenbezeichnungssysteme. Diese bereiten ein NER-Modell mit semantischen Lerntechniken vor, um ihm den Kontext und die Beziehungen zwischen den Kategorien beizubringen.
- Hybridsysteme. Diese nutzen Aspekte mehrerer Systeme in einem kombinierten Ansatz.

Wer nutzt die der Erkennung benannter Entitäten?
Die Erkennung benannter Entitäten wird in verschiedenen Branchen und Anwendungen auf unterschiedliche Weise eingesetzt. Jeder Anwendungsfall vereinfacht die Suche nach und die Extraktion wichtiger Informationen aus großen Datenmengen, sodass Menschen Zeit für wertvollere Aufgaben aufwenden können. Beispiele hierfür sind:
- Chatbots. Die generative KI von OpenAI, ChatGPT, Google Bard und andere Chatbots verwenden NER-Modelle, um relevante Entitäten zu identifizieren, die in Benutzeranfragen und -konversationen erwähnt werden. Dies hilft ihnen, den Kontext der Frage eines Benutzers zu verstehen und die Antworten des Chatbots zu verbessern.
- Kundendienst. NER organisiert Kundenfeedback und -beschwerden nach Produktnamen und identifiziert häufige oder trendige Beschwerden über bestimmte Produkte oder Filialen. Dies unterstützt das Kundendienstteams, sich auf eingehende Anfragen vorzubereiten, schneller zu reagieren und automatisierte Systeme einzurichten, die Kunden an die entsprechenden Support Desks und Abschnitte der FAQ-Seiten weiterleiten.
- Finanzen. NER extrahiert Zahlen aus Privatmärkten, Krediten und Gewinnberichten und erhöht so die Geschwindigkeit und Genauigkeit der Analyse von Rentabilität und Kreditrisiko. NER extrahiert auch Namen und Unternehmen, die in sozialen Medien und anderen Online-Beiträgen erwähnt werden, und hilft Finanzinstituten so, Trends und Entwicklungen zu überwachen, die sich auf die Aktienkurse auswirken könnten.
- Gesundheitswesen. NER-Tools extrahieren wichtige Informationen aus Laborberichten und elektronischen Patientenakten und helfen so Gesundheitsdienstleistern, Arbeitslasten zu reduzieren, Daten schneller und genauer zu analysieren und die Versorgung zu verbessern.
- Hochschulbildung. NER ermöglicht es Studierenden, Forschern und Professoren, große Mengen an Fachartikeln und Archivmaterial schnell zusammenzufassen und relevante Themen zu finden.
- Personalwesen. Diese Systeme optimieren die Personalbeschaffung und -einstellung, indem sie die Lebensläufe der Bewerber zusammenfassen und Informationen wie Qualifikationen, Ausbildung und Referenzen extrahieren. NER filtert auch Beschwerden und Anfragen von Mitarbeitern an die entsprechenden Abteilungen und hilft so bei der Organisation interner Arbeitsabläufe.
- Medien. Nachrichtenanbieter nutzen die Erkennung benannter Entitäten, um die vielen Artikel und Social-Media-Beiträge, die sie lesen müssen, zu analysieren und den Inhalt in wichtige Informationen und Trends zu kategorisieren. Dies hilft ihnen, Nachrichten und aktuelle Ereignisse schnell zu verstehen und darüber zu berichten.
- Empfehlungsmaschinen. Viele Unternehmen nutzen NER, um die Relevanz ihrer Empfehlungsmaschinen zu verbessern. Unternehmen wie Netflix nutzen NER beispielsweise, um die Suchanfragen und das Sehverhalten der Nutzer zu analysieren und personalisierte Empfehlungen bereitzustellen.
- Suchmaschinen. NER hilft Suchmaschinen dabei, Themen zu identifizieren und zu kategorisieren, die im Internet und bei Suchanfragen erwähnt werden. Dadurch können Suchplattformen die Relevanz von Themen für die Suche eines Benutzers verstehen und Benutzern genaue Ergebnisse liefern.
- Stimmungsanalyse. NER ist eine Schlüsselkomponente der Stimmungsanalyse. Sie extrahiert Produktnamen, Marken und andere Informationen, die in Kundenbewertungen, Social-Media-Beiträgen und anderen unstrukturierten Texten erwähnt werden. Das Stimmungsanalyse-Tool analysiert dann die Informationen, um die Gefühle des Autors zu einem Produkt, einem Unternehmen oder einem anderen Thema zu ermitteln. NER wird auch zur Analyse der Stimmung von Mitarbeitern in Umfrageantworten und Beschwerden eingesetzt.
Vorteile und Herausforderungen der Erkennung benannter Entitäten
Es gibt mehrere Vorteile und Herausforderungen im Zusammenhang mit NER.
Vorteile von NER
Die Erkennung benannter Entitäten bietet bei sachgemäßer Verwendung eine Reihe von Vorteilen:
- Automatisierung der Informationsextraktion großer Datenmengen.
- Analyse wichtiger Informationen in unstrukturiertem Text.
- Erleichterung der Analyse aufkommender Trends.
- Eliminierung menschlicher Fehler bei der Analyse.
- Einsatz in fast allen Branchen.
- Zeitersparnis für Mitarbeiter, die sich anderen Aufgaben widmen können.
- Verbesserung der Präzision von NLP-Aufgaben und -Prozessen.
Nachteile von NER
Die Erkennung benannter Entitäten bringt auch ihre eigenen Probleme mit sich:
- Schwierigkeiten bei der Analyse von lexikalischen Mehrdeutigkeiten, Semantik und sich entwickelnden Sprachgebräuchen in Texten.
- Probleme mit unterschiedlichen Schreibweisen.
- Kennt nicht alle Fremdwörter.
- Kann Probleme mit gesprochenem Text haben, zum Beispiel bei Telefongesprächen.
- Führt dazu, dass viele moderne NER-Modelle nur begrenzte Leistungskennzahlen aufweisen.
- Kann große Mengen an Trainingsdaten oder viele menschliche Eingriffe erfordern.
- Kann anfällig für verzerrte Ergebnisse sein, wenn der Machine-Learning-Algorithmus eine versteckte Verzerrung aufweist.
Best Practices
Unternehmen sollten beim Training, bei der Nutzung und bei der Wartung ihrer NER-Systeme eine Reihe von Best Practices befolgen. Zu diesen Praktiken gehören:
- Verwendung der richtigen Tools. Verschiedene Anbieter bieten Tools an, die auf NER-Aufgaben zugeschnitten sind. Dazu gehören Sprachmodelle und Bibliotheken wie BERT, Stanford NER Tagger, Natural Language Toolkit (NLTK) und SpaCy.
- Daten eindeutig kennzeichnen und mit Anmerkungen versehen. Es ist wichtig, Entitätstypen klar zu definieren und über ein Annotationsschema zu verfügen, an das sich NER-Modelle bei der Ausführung von Aufgaben halten. Dies ist bei der Vorbereitung der Daten erforderlich, die zum Trainieren von NER-Modellen verwendet werden.
- Feature-Engineering. Zur Feinabstimmung eines NER-Modells wird Feature Engineering eingesetzt, um wichtige Funktionen bereitzustellen, wie zum Beispiel Part-of-Speech-Tagging und Worteinbettung. Es übernimmt auch Aufgaben wie die Darstellung von Wörtern als numerische Werte, damit Computersysteme sie im Kontext verarbeiten und verstehen können.
- Kontinuierliche Modellbewertung. Nach der Implementierung ist eine kontinuierliche Neubewertung der NER-Modelle erforderlich. Beispielsweise werden durch die Analyse der Leistung im Laufe der Zeit zur Fehlererkennung verbesserungswürdige Bereiche ermittelt.
Natural Language Toolkit versus SpaCy
NLTK und SpaCy sind zwei NER-Programme mit einzigartigen Merkmalen. NLTK basiert auf der NLP-Bibliothek von Python und bietet mehrere Algorithmen. NLTK wird häufig für die Vermittlung von NLP an Anfänger sowie für Forscher verwendet, die Anwendungen von Grund auf neu entwickeln. Es verwendet Zeichenketten als Ein- und Ausgaben in der Vorverarbeitung. Es bietet Tokenisierung, Stemming, Part-of-Speech-Tagging und Parsing und kann mit benutzerdefinierten Daten trainiert werden.
SpaCy hingegen ist Open Source und verwendet einen einzigen Stemmer-Algorithmus, der für konkrete Aufgaben geeignet ist. Er wird häufig für die Erstellung professioneller NLP-Anwendungen verwendet und ist in der Vorverarbeitung objektorientiert. SpaCy ist auch in der Lage, große Datenmengen zu verarbeiten, Beziehungen zwischen Entitäten zu extrahieren und Unterstützung für Wortvektoren zu bieten. Er gilt als schneller als NLTK.






