BERT (Bidirectional Encoder Representations from Transformers)
Was ist BERT?
BERT ist ein Open-Source-Framework für maschinelles Lernen zur Verarbeitung natürlicher Sprache (Natural Language Processing, NLP). BERT wurde entwickelt, um Computer zu unterstützen, die Bedeutung mehrdeutiger Sprache in Texten zu verstehen, indem der umgebende Text verwendet wird, den Kontext herzustellen. Das BERT-Framework wurde mit Text aus Wikipedia trainiert und kann mit Frage- und Antwort-Datensätzen feinabgestimmt werden.
BERT steht für Bidirectional Encoder Representations from Transformers und basiert auf Transformer, einem Deep-Learning-Modell, bei dem jedes Ausgabeelement mit jedem Eingabeelement verbunden ist und die Gewichtung zwischen ihnen dynamisch auf der Grundlage ihrer Verbindung berechnet wird.
In der Vergangenheit konnten Sprachmodelle Texteingaben nur sequenziell lesen – entweder von links nach rechts oder von rechts nach links – aber nicht beides gleichzeitig. BERT ist hingegen darauf ausgelegt, in beide Richtungen gleichzeitig zu lesen. Diese Fähigkeit, die durch die Einführung der Transformer ermöglicht wurde, wird als Bidirektional bezeichnet.
Mit der bidirektionalen Fähigkeit wird BERT auf zwei verschiedene, aber verwandte NLP-Aufgaben trainiert: maskierte Sprachmodellierung (Masked Language Modeling, MLM) und Vorhersage des nächsten Satzes (Next Sentence Prediction, NSP).
Das Ziel maskierter Sprachmodellierung ist es, ein Wort in einem Satz zu verstecken und dann das Programm auf der Grundlage des Kontexts des versteckten Worts vorhersagen zu lassen, welches Wort versteckt (maskiert) wurde. Das Ziel des Trainings für die Vorhersage des nächsten Satzes ist es, das Programm vorhersagen zu lassen, ob zwei gegebene Sätze eine logische, sequenzielle Verbindung haben oder ob ihre Beziehung zufällig ist.
Hintergrund und Geschichte von BERT
Transformer wurden 2017 von Google eingeführt. Zuvor verwendeten Sprachmodelle hauptsächlich rekurrente neuronale Netze (Recurrent Neural Network, RNN) und faltende neuronale Netze (Convolutional Neural Network, CNN), um NLP-Aufgaben zu bewältigen.
CNNs und RNNs sind gute Modelle, erfordern jedoch, dass Datenfolgen in einer festgelegten Reihenfolge verarbeitet werden. Transformer-Modelle gelten als bedeutende Verbesserung, da sie keine Datenfolgen in einer festgelegten Reihenfolge erfordern.
Da Transformer Daten in beliebiger Reihenfolge verarbeiten können, ermöglichen sie das Training mit größeren Datenmengen als vor ihrer Existenz. Dies erleichterte die Erstellung vorab trainierter Modelle wie BERT, das vor seiner Veröffentlichung mit riesigen Mengen an Sprachdaten trainiert wurde.
Im Jahr 2018 veröffentlichte Google BERT und stellte es als Open Source zur Verfügung. In seiner Forschungsphase erzielte das Framework bahnbrechende Ergebnisse bei elf Aufgaben zum Verständnis natürlicher Sprache (Natural Language Understanding, NLU), darunter Stimmungsanalyse, semantische Rollenbeschriftung, Satzklassifizierung und Disambiguierung von polysemen Wörtern, also Wörtern mit mehreren Bedeutungen.
Durch die Erfüllung dieser Aufgaben unterscheidet sich BERT von früheren Sprachmodellen wie word2vec und GloVe. Diese Modelle waren bei der Interpretation von Kontext und mehrdeutigen Wörtern oder Wörtern mit mehreren Bedeutungen eingeschränkt. BERT geht effektiv mit Mehrdeutigkeiten um, die auf diesem Gebiet die größte Herausforderung für die NLU darstellen. Es ist in der Lage, Sprache mit einem relativ menschenähnlichen Verstand zu analysieren.
Im Oktober 2019 kündigte Google an, dass es damit beginnen werde, BERT auf seine in den USA ansässigen Produktionssuchalgorithmen anzuwenden.
Es wird geschätzt, dass BERT das Verständnis von Google für etwa 10 % der englischsprachigen Google-Suchanfragen in den USA verbessert. Google empfiehlt Organisationen, keine Versuche zur Optimierung von Inhalten für BERT zu unternehmen, da BERT darauf abzielt, ein natürliches Sucherlebnis zu bieten. Nutzern wird empfohlen, Suchanfragen und Inhalte auf das natürliche Thema und die natürliche Nutzererfahrung zu konzentrieren.
Bis Dezember 2019 wurde BERT auf mehr als 70 verschiedene Sprachen angewendet. Das Modell hatte einen großen Einfluss auf die Sprachsuche sowie auf die textbasierte Suche, die vor 2018 mit den NLP-Techniken von Google fehleranfällig war. Nachdem BERT auf viele Sprachen angewendet wurde, verbesserte es die Suchmaschinenoptimierung. Seine Fähigkeit, Zusammenhänge zu verstehen, hilft ihm, Muster zu interpretieren, die verschiedene Sprachen gemeinsam haben, ohne die Sprache vollständig verstehen zu müssen.
BERT hat viele KI-Systeme (künstliche Intelligenz) beeinflusst. Verschiedene einfachere Versionen von BERT und ähnliche Trainingsmethoden wurden auf Modelle von GPT-2 bis ChatGPT angewendet.
Wie BERT funktioniert
Das Ziel jeder NLP-Technik ist es, die menschliche Sprache so zu verstehen, wie sie natürlich gesprochen wird. Im Fall von BERT bedeutet dies in der Regel, ein Wort in einer Leerstelle vorherzusagen. Um dies zu erreichen, müssen die Modelle in der Regel mit einem großen Bestand an speziellen, gelabelten Trainingsdaten trainiert werden. Dies erfordert eine mühsame manuelle Datenkennzeichnung durch Teams von Linguisten.
BERT wurde jedoch nur mit einem nicht gelabelten, reinen Textkorpus trainiert: mit der gesamten englischen Wikipedia und dem Brown Corpus. Es lernt weiterhin unüberwacht aus dem ungelabelten Text und verbessert sich selbst dann, wenn es in praktischen Anwendungen eingesetzt wird (zum Beispiel bei der Google-Suche). Sein Vortraining dient als Basisschicht für das Wissen, auf dem es aufbauen kann. Von dort aus kann sich BERT an die ständig wachsende Menge an durchsuchbaren Inhalten und Abfragen anpassen und auf die Spezifikationen des Benutzers abgestimmt werden. Dieser Prozess wird als Transferlernen bezeichnet.
Das Pre-Training von BERT dient als Basiswissen, auf dem die Antworten aufbauen können. Von dort aus kann sich BERT an die ständig wachsende Menge an durchsuchbaren Inhalten und Abfragen anpassen und auf die Vorgaben eines Benutzers abgestimmt werden. Dieser Prozess wird als Transferlernen bezeichnet. Abgesehen von diesem Pre-Training-Prozess verfügt BERT über mehrere andere Aspekte, auf die es angewiesen ist, um wie vorgesehen zu funktionieren, darunter:
Transformer
Googles Arbeit an den Transformers hat BERT erst möglich gemacht. Der Transformer ist der Teil des Modells, der BERT seine erhöhte Fähigkeit verleiht, Kontext und Mehrdeutigkeit in der Sprache zu verstehen. Der Transformer verarbeitet jedes beliebige Wort in Bezug auf alle anderen Wörter in einem Satz, anstatt sie einzeln zu verarbeiten. Durch die Betrachtung aller umgebenden Wörter ermöglicht der Transformer BERT, den vollständigen Kontext des Wortes zu verstehen und somit die Absicht des Suchenden besser zu verstehen.
Dies steht im Gegensatz zur traditionellen Methode der Sprachverarbeitung, die als Worteinbettung bekannt ist. Dieser Ansatz wurde in Modellen wie GloVe und word2vec verwendet. Dabei wurde jedes einzelne Wort einem Vektor zugeordnet, der nur eine Dimension der Bedeutung dieses Wortes darstellte.
Maskierte Sprachmodellierung
Modelle zur Worteinbettung erfordern große Datensätze strukturierter Daten. Sie sind zwar für viele allgemeine NLP-Aufgaben geeignet, scheitern jedoch an der kontextlastigen, prädiktiven Natur der Beantwortung von Fragen, da alle Wörter in gewisser Weise an einen Vektor oder eine Bedeutung gebunden sind.
BERT verwendet eine Methode der maskierten Sprachmodellierung, um das Wort im Fokus zu halten, damit es sich nicht selbst sieht oder eine feste Bedeutung unabhängig von seinem Kontext hat. BERT ist gezwungen, das maskierte Wort allein anhand des Kontexts zu identifizieren. In BERT werden Wörter durch ihre Umgebung definiert, nicht durch eine vorangestellte Identität.
Selbstaufmerksamkeit
BERT stützt sich auch auf einen Selbstaufmerksamkeitsmechanismus, der die Beziehungen zwischen Wörtern in einem Satz erfasst und versteht. Die bidirektionalen Transformer im Zentrum des BERT-Designs machen dies möglich. Dies ist von Bedeutung, da ein Wort im Verlauf eines Satzes oft seine Bedeutung ändern kann. Jedes hinzugefügte Wort erweitert die Gesamtbedeutung des Wortes, auf das sich der NLP-Algorithmus konzentriert. Je mehr Wörter in einem Satz oder einer Phrase vorhanden sind, desto mehrdeutiger wird das fokussierte Wort. BERT berücksichtigt die erweiterte Bedeutung, indem es bidirektional liest, die Auswirkungen aller anderen Wörter in einem Satz auf das Fokuswort berücksichtigt und die Links-nach-rechts-Dynamik eliminiert, die Wörter im Verlauf eines Satzes auf eine bestimmte Bedeutung festlegt.
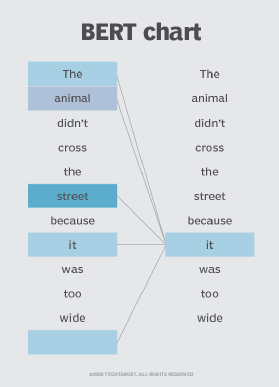
Wie in Abbildung 1 zu sehen, bestimmt BERT beispielsweise, auf welches vorhergehende Wort im Satz sich das Wort it bezieht, und verwendet dann den Selbstaufmerksamkeitsmechanismus, um die Optionen abzuwägen. Das Wort mit der höchsten berechneten Punktzahl gilt als die richtige Assoziation. In diesem Beispiel bezieht sich it auf animal und nicht auf street. Wenn dieser Satz eine Suchanfrage wäre, würden die Ergebnisse dieses subtilere, präzisere Verständnis widerspiegeln, das BERT erreicht hat.
Vorhersage des nächsten Satzes
Die Vorhersage des nächsten Satzes ist eine Trainingstechnik, die BERT lehrt, vorherzusagen, ob ein bestimmter Satz auf einen vorherigen Satz folgt, um sein Wissen über die Beziehungen zwischen Sätzen zu testen. Konkret werden BERT sowohl korrekt als auch falsch gepaarte Satzpaare vorgelegt, damit es den Unterschied besser verstehen lernt. Mit der Zeit wird BERT immer besser darin, die nächsten Sätze genau vorherzusagen. In der Regel werden sowohl NSP- als auch MLM-Techniken gleichzeitig eingesetzt.
Wofür wird BERT verwendet?
BERT wird derzeit bei Google eingesetzt, um die Interpretation von Suchanfragen der Nutzer zu optimieren. BERT zeichnet sich durch mehrere Funktionen aus, die dies möglich machen, darunter:
- Sequenz-zu-Sequenz-Spracherzeugungsaufgaben wie zum Beispiel:
- Beantwortung von Fragen
- Zusammenfassungen
- Vorhersage von Sätzen
- Generierung von Konversationsantworten
- Aufgaben zum Verstehen natürlicher Sprache wie zum Beispiel:
- Auflösung von Polysemie und Koreferenz (Wörter, die gleich klingen oder gleich aussehen, aber unterschiedliche Bedeutungen haben)
- Disambiguierung der Wortbedeutung
- Inferenz natürlicher Sprache
- Sentiment-Klassifizierung
BERT ist Open Source, das heißt jeder kann es nutzen. Google gibt an, dass Nutzer ein hochmodernes Frage-und-Antwort-System in nur 30 Minuten auf einer Tensor Processing Unit (TPU) und in wenigen Stunden auf einer GPU trainieren können. Viele andere Organisationen, Forschungsgruppen und separate Google-Abteilungen optimieren die Architektur des Modells durch überwachtes Training, um es entweder für mehr Effizienz zu optimieren oder es durch Vortraining von BERT mit bestimmten kontextbezogenen Darstellungen auf bestimmte Aufgaben zu spezialisieren. Beispiele hierfür sind:
- PatentBERT. Dieses BERT-Modell ist für die Durchführung von Patentklassifizierungsaufgaben optimiert.
- DocBERT. Dieses Modell ist für Aufgaben der Dokumentenklassifizierung optimiert.
- BioBERT. Dieses Modell zur Darstellung biomedizinischer Sprache dient dem biomedizinischen Text Mining.
- VideoBERT. Dieses gemeinsame visuell-linguistische Modell wird beim unüberwachten Lernen von nicht gelabelten Daten auf YouTube verwendet.
- SciBERT. Dieses Modell ist für wissenschaftliche Texte gedacht.
- G-BERT. Dieses vorab trainierte BERT-Modell verwendet medizinische Codes mit hierarchischen Darstellungen durch neuronale Netze und wird dann für die Abgabe medizinischer Empfehlungen feinabgestimmt.
- TinyBERT by Huawei. Dieses kleinere Schüler-BERT lernt vom ursprünglichen Lehrer-BERT und führt eine Transformer-Destillation durch, um die Effizienz zu verbessern. TinyBERT erzielte im Vergleich zu BERT-base vielversprechende Ergebnisse, während es 7,5-mal kleiner und 9,4-mal schneller bei der Inferenz ist.
- DistilBERT by Hugging Face. Diese kleinere, schnellere und günstigere Version von BERT wird von BERT trainiert, dann werden bestimmte architektonische Aspekte entfernt, um die Effizienz zu verbessern.
- ALBERT. Diese leichtgewichtige Version von BERT senkt den Speicherverbrauch und erhöht die Geschwindigkeit, mit der das Modell trainiert wird.
- SpanBERT. Dieses Modell verbesserte die Fähigkeit von BERT, Textabschnitte vorherzusagen.
- RoBERTa. Durch fortschrittlichere Trainingsmethoden wurde dieses Modell über einen längeren Zeitraum mit einem größeren Datensatz trainiert, um die Leistung zu verbessern.
- ELECTRA. Diese Version wurde darauf zugeschnitten, hochwertige Textdarstellungen zu generieren.
BERT versus GPT
Obwohl BERT- und GPT-Modelle zu den besten Sprachmodellen gehören, gibt es sie aus unterschiedlichen Gründen. Das ursprüngliche GPT-3-Modell und die nachfolgenden, weiterentwickelten GPT-Modelle von OpenAI sind ebenfalls Sprachmodelle, die auf riesigen Datensätzen trainiert wurden. Obwohl sie dies mit BERT gemeinsam haben, unterscheidet sich BERT in mehrfacher Hinsicht.
BERT
Google hat BERT als bidirektionales Transformer-Modell entwickelt, das Wörter in Texten sowohl im Links-nach-rechts- als auch im Rechts-nach-links-Kontext untersucht. Es hilft Computersystemen, Text zu verstehen, anstatt Text zu erstellen, wofür GPT-Modelle entwickelt wurden. BERT ist hervorragend für NLU-Aufgaben sowie für die Durchführung von Stimmungsanalysen geeignet. Es ist ideal für Google-Suchen und Kundenfeedback.
GPT
GPT-Modelle unterscheiden sich von BERT sowohl in ihren Zielen als auch in ihren Anwendungsfällen. GPT-Modelle sind Formen der generativen KI, die Originaltexte und andere Formen von Inhalten generieren. Sie eignen sich auch gut für die Zusammenfassung langer Textstücke und schwer zu interpretierender Texte.






