
Sittipol - stock.adobe.com
Wie werden Redshift, Athena und EMR für Analysen eingesetzt?
Amazon Redshift, Athena und EMR sind zentrale Analyseservices von AWS. Sie unterscheiden sich in Kosten, Skalierbarkeit, Datenformaten und Anforderungen an die Infrastruktur.

Unternehmen nutzen häufig Cloud-Anwendungen, um große Datenmengen zu analysieren, darunter System- und Anwendungsprotokolle, Geschäftsmetriken, externe Datenquellen, öffentliche Datensätze und Eingabedaten für Machine-Learning-Modelle (ML).
AWS, der größte Anbieter von Public-Cloud-Lösungen, verfügt über ein breites Spektrum an Services für Big Data und Datenanalyse. Diese Services haben teilweise überlappende Funktionen, was die Auswahl erschweren kann.
Auch wenn diese drei AWS-Services für eine Vielzahl von Datenanalyseaufgaben geeignet sind, ist es vor der Auswahl eines bestimmten Services unerlässlich, die erforderlichen Integrationen mit relevanten Systemen und Datenquellen zu evaluieren. Berücksichtigen Sie außerdem das zu analysierende Datenvolumen, führen Sie Lasttests durch und bewerten Sie die Kosten entsprechend dem spezifischen Anwendungsfall in einer bestimmten Anwendung.
Sehen wir uns Amazon Redshift, Amazon Athena und Amazon EMR genauer an, um die richtige Lösung für Ihre Datenanalyseanforderungen zu finden.
Amazon Redshift
Amazon Redshift ist ein verwaltetes Data Warehouse, das Datenanalysen an einem zentralen Ort speichert und ausführt. Die Arbeit wird in einem Redshift-Cluster durchgeführt, der aus einem oder mehreren Rechenknoten besteht, die auch Daten speichern. Redshift unterstützt zwar die Analyse von Daten, die in Amazon S3 gespeichert sind, mithilfe von Amazon Redshift Spectrum, seine Hauptaufgabe liegt jedoch auf der Analyse von Daten, die im Cluster selbst gespeichert sind. Es unterstützt auch eine serverlose Konfiguration, die auf Daten zugreifen kann, die entweder im verwalteten Storage von Redshift oder extern gespeichert sind.
Redshift führt Daten aus verschiedenen Quellen zusammen und speichert sie in einem strukturierten Muster, das durch Datenbanken und Tabellen definiert ist. Dieser Service ist besonders empfehlenswert, wenn Sie komplexe Abfragen an umfangreichen Sammlungen strukturierter und halbstrukturierter Daten mit hoher Performance durchführen müssen. Redshift kann Daten aus folgenden Quellen automatisch aufnehmen:
- Amazon Relational Database Service (RDS)
- Amazon Aurora MySQL
- Amazon Kinesis
- Amazon Managed Streaming für Apache Kafka
Darüber hinaus können andere AWS-Services wie EMR, Glue und SageMaker auf die gespeicherten Daten zugreifen. Redshift kann auch ML-Trainings- und Vorhersageprozesse direkt auf den verfügbaren Daten ausführen.
Das Hauptmodell – bereitgestellte Cluster – macht es schwierig, die Größe eines Redshift-Clusters basierend auf Nutzungsmustern zu reduzieren, da die Daten direkt im Cluster gespeichert werden. Dies führt in der Regel zu hohen Kosten, da bereitgestellte Redshift-Cluster oft ständig in Betrieb sind. IT-Teams können dieses Problem mit Reserved Instances lösen, die zu ermäßigten Stundensätzen für einen Zeitraum von einem oder drei Jahren abgerechnet werden. Redshift Serverless ist ebenfalls eine kostensparende Option, die eine anpassbare Rechenkapazität basierend auf den Anwendungsanforderungen zuweist.
Redshift kann inzwischen direkt Machine-Learning-Modelle über Redshift ML trainieren und vorhersagen treffen, indem es eng mit Amazon SageMaker integriert ist, ganz ohne Datenverschiebung. Außerdem unterstützt Redshift automatische Aktualisierung materialisierter Sichten, was Analyseabfragen beschleunigt und die Performance optimiert.
Amazon Athena
Amazon Athena basiert auf den Open-Source-Engines Trino, Presto und Spark und ist ein serverloser Dienst für die Datenanalyse auf AWS. Er wird häufig zur Analyse von Protokolldaten verwendet, die für Dienste wie die folgenden in S3 exportiert und dort gespeichert werden:
- Application Load Balancer
- Amazon CloudFront
- AWS CloudTrail
- Amazon Data Firehose
Da es auch auf Daten zugreifen kann, die in einem AWS Glue Catalog definiert sind, unterstützt es Amazon DynamoDB, CloudWatch, Open Database Connectivity/Java Database Connectivity-Treiber und Redshift. Es lässt sich auch in ML-Inferenz-Endpunkte integrieren, um über in Athena definierte Abfragen auf verfügbare ML-Modelle zuzugreifen.
Dieser Service ist zwar die einfachste Möglichkeit, Einblick in die in S3 gespeicherten Daten zu erhalten, aber Services wie EMR oder Redshift können möglicherweise eine bessere Leistung bieten – wenn auch zu potenziell höheren Kosten –, da Entwickler die zugrunde liegende Infrastruktur kontrollieren können. Er lässt sich auch in Amazon QuickSight integrieren, um Daten und Abfrageergebnisse automatisiert zu visualisieren.
Datenanalysten verwenden Athena, um Abfragen mit SQL-Syntax auszuführen. Benutzer müssen die zugrunde liegende Recheninfrastruktur nicht explizit konfigurieren und zahlen in der Standardkonfiguration nur für die gescannten Daten, was Athena in den meisten Fällen zu einem kostengünstigen Tool macht. Bei Anwendungsfällen mit einem konstant hohen Transaktionsvolumen können die Kosten jedoch höher ausfallen. Athena ermöglicht SQL-Abfragen über verschiedene externe Datenquellen hinweg, wie PostgreSQL, MySQL oder Google Cloud Storage, was es ideal für heterogene Umgebungen macht.
Athena eignet sich gut für seltene oder ad hoc auftretende Datenanalyseanforderungen, da Benutzer keine Infrastruktur starten müssen und der Dienst jederzeit für Abfragen bereitsteht. Entwickler können auch die Funktion Athena Provisioned Capacity in Betracht ziehen, um eine Mindestmenge an Rechenkapazität zuzuweisen, was für vorhersehbare Workloads nützlich ist.
Weil Athena jetzt Apache Iceberg unterstützt – ein Tabellenformat für große Datasets mit ACID-Transaktionen – ist es auch für moderne Data-Lakehouse-Architekturen nützlich.
Amazon EMR
Amazon EMR, ein Big-Data-Angebot, bietet verwaltete Bereitstellungen beliebter Datenanalyseplattformen wie Presto, Apache Spark, Apache Hadoop, Apache Hive, Apache Hudi und Apache HBase. EMR automatisiert den Start von Rechen- und Storage-Knoten, die von Amazon EC2-Instanzen, AWS Fargate, einer von AWS Outposts verwalteten lokalen Infrastruktur und auch serverlos betrieben werden.
Während Daten mit dem Hadoop Distributed File System (HDFS) in EC2-Instanzen gespeichert werden können, unterstützt der Service auch die Abfrage von Daten, die in Quellen außerhalb des Clusters gespeichert sind, wie S3, DynamoDB oder relationale Datenbanken, die von RDS verwaltet werden. Auf von EMR verwaltete Daten kann auch von SageMaker für ML-Trainingsaufgaben zugegriffen werden.
EMR ermöglicht es, die Cluster-Größe an die Nutzungsanforderungen anzupassen und so die Kosten zu optimieren. Außerdem werden Reserved Instances und Savings Plans for EC2-Cluster sowie Savings Plans for Fargate unterstützt, was zur Kostensenkung beiträgt.
EMR eignet sich gut für vorhersehbare Datenanalyseaufgaben, typischerweise auf Clustern, die über längere Zeiträume verfügbar sein müssen. Dazu gehören Datenlasten, bei denen die Kontrolle über die zugrunde liegende Infrastruktur – also EC2-Instanzen – die Leistung optimiert und den zusätzlichen Aufwand rechtfertigt.
Durch den Betrieb von EMR auf Amazon EKS (EMR on EKS) können bereits bestehende Kubernetes-Umgebunen nahtlos für Big-Data-Verarbeitung genutzt werden.
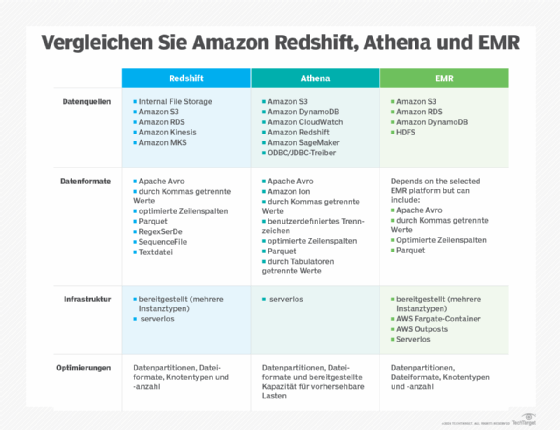
Athena, EMR und Redshift auf einen Blick
Amazon Redshift eignet sich besonders für strukturierte Daten und komplexe Analysen mit hohen Performance-Anforderungen. Amazon Athena ist ideal für Ad-hoc-Abfragen über S3-Daten und punktet mit einfacher Handhabung und geringen Einstiegskosten. Amazon EMR ist die flexibelste Lösung für Big-Data-Projekte, erfordert aber mehr Infrastruktur-Know-how und Management.







