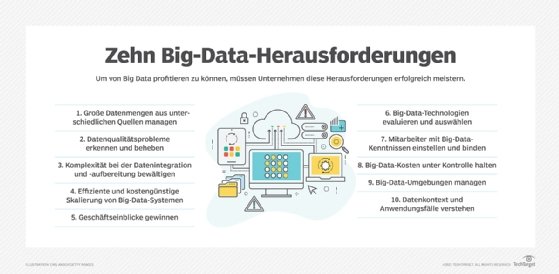
Zehn Big-Data-Herausforderungen und wie man sie bewältigt
Die Umsetzung einer Big-Data-Initiative erfordert eine Reihe von Fähigkeiten und Best Practices. Hier sind zehn Herausforderungen, auf die sich Unternehmen vorbereiten müssen.

Eine gut umgesetzte Big-Data-Strategie kann die Betriebskosten senken, die Markteinführungszeit verkürzen und neue Produkte ermöglichen. Unternehmen stehen jedoch vor einer Reihe von Herausforderungen, wenn es darum geht, Big-Data-Initiativen von den Diskussionen in der Vorstandsetage in die Praxis umzusetzen.
IT- und Datenexperten müssen die physische Infrastruktur für die Übertragung von Daten aus verschiedenen Quellen und zwischen mehreren Anwendungen aufbauen. Außerdem müssen sie die Anforderungen an Leistung, Skalierbarkeit, Aktualität, Sicherheit und Data Governance erfüllen. Darüber hinaus müssen die Implementierungskosten im Vorfeld berücksichtigt werden, da sie schnell außer Kontrolle geraten können.
Am wichtigsten ist aber, dass Unternehmen herausfinden müssen, wie und warum Big Data für ihr Unternehmen überhaupt wichtig ist.
„Eine der größten Herausforderungen bei Big-Data-Projekten besteht darin, die gewonnenen Erkenntnisse erfolgreich anzuwenden“, sagt Bill Szybillo, Business Intelligence Manager beim ERP-Softwareanbieter VAI.
Viele Anwendungen und Systeme erfassen Daten, aber Unternehmen tun sich oft schwer damit, zu verstehen, was wertvoll ist, und diese Erkenntnisse dann auch sinnvoll einzusetzen.
Im Folgenden werden zehn Big-Data-Herausforderungen vorgestellt, die Unternehmen kennen sollten, sowie einige Tipps, wie sie diese bewältigen.
1. Große Datensätze managen
Big Data ist per definitionem mit großen Datenmengen verbunden, die in unterschiedlichen Systemen und Plattformen gespeichert sind. Laut Szybillo besteht die erste Herausforderung für Unternehmen darin, die großen Datensätze, die sie aus CRM- und ERP-Systemen und anderen Datenquellen extrahieren, in einer einheitlichen und verwaltbaren Big-Data-Architektur zu konsolidieren.
„Sobald man einen Überblick über die gesammelten Daten hat, wird es einfacher, die Erkenntnisse durch kleine Anpassungen einzugrenzen“, sagt er. Planen Sie daher eine Infrastruktur, die schrittweise Änderungen zulässt. Der Versuch, große Änderungen vorzunehmen, kann am Ende nur zu neuen Problemen führen.
2. Datenqualitätsproblemen erkennen und beheben
Die auf Big Data aufbauenden Analysealgorithmen und KI-Anwendungen können zu schlechten Ergebnissen führen, wenn sich Probleme mit der Datenqualität in Big-Data-Systeme einschleichen. Diese Probleme können in dem Maße an Bedeutung gewinnen und schwieriger zu überprüfen sein, wie Datenmanagement- und Analyseteams versuchen, mehr und andere Datentypen zu erfassen.
Bunddler, ein Online-Marktplatz für die Vermittlung von Web-Shopping-Assistenten, die den Kunden beim Kauf von Produkten und bei der Organisation des Versands unterstützen, hat diese Probleme am eigenen Leib erfahren, als das Unternehmen auf 500.000 Kunden anwuchs. Ein wichtiger Wachstumstreiber für das Unternehmen war die Nutzung von Big Data, um eine hochgradig personalisierte Erfahrung zu bieten, Upselling-Möglichkeiten aufzudecken und neue Trends zu überwachen. Ein effektives Datenqualitätsmanagement war ein zentrales Anliegen.
„Probleme mit der Datenqualität müssen ständig überwacht und behoben werden“, erklärt Pavel Kovalenko, CEO von Bunddler. Doppelte Einträge und Tippfehler seien keine Seltenheit, vor allem wenn die Daten aus verschiedenen Quellen stammen. Um die Qualität der gesammelten Daten zu gewährleisten, hat Kovalenkos Team einen intelligenten Datenidentifikator entwickelt, der Duplikate mit geringfügigen Datenabweichungen vergleicht und mögliche Tippfehler meldet. Dies hat die Genauigkeit, der durch die Analyse der Daten gewonnenen Geschäftseinblicke, verbessert.
3. Komplexe Datenintegration und -aufbereitung bewältigen
Big-Data-Plattformen lösen das Problem der Erfassung und Speicherung großer Datenmengen mit unterschiedlichen Datenformaten – und des schnellen Abrufs von Daten, die für Analysezwecke benötigt werden. „Der Prozess der Datenerfassung kann jedoch immer noch schwierig sein“, sagt Rosaria Silipo, Principal Data Scientist beim Open-Source-Analyseplattform-Anbieter Knime.
Die Integrität der gesammelten Datenspeicher eines Unternehmens hängt davon ab, dass sie ständig aktualisiert werden. Dies erfordert den Zugriff auf eine Vielzahl von Datenquellen und spezielle Strategien zur Integration von Big Data.
Einige Unternehmen nutzen einen Data Lake als Sammelbecken für Big-Data-Sätze aus verschiedenen Quellen, ohne sich Gedanken darüber zu machen, wie die unterschiedlichen Daten integriert werden sollen. Verschiedene Geschäftsbereiche produzieren beispielsweise Daten, die für gemeinsame Analysen wichtig sind, aber diese Daten haben oft eine unterschiedliche zugrunde liegende Semantik, die disambiguiert werden muss. Silipo warnt vor einer Ad-hoc-Integration für Projekte, die mit viel Nacharbeit verbunden sein kann. Um einen optimalen ROI für Big-Data-Projekte zu erzielen, ist es im Allgemeinen besser, einen strategischen Ansatz für die Datenintegration zu entwickeln.
4. Effiziente und kosteneffektive Skalierung von Big-Data-Systemen
Unternehmen können viel Geld für die Speicherung von Big Data verschwenden, wenn sie keine Strategie für die Nutzung der Daten haben. „Unternehmen müssen verstehen, dass Big-Data-Analysen bereits bei der Datenaufnahme beginnen“, sagt George Kobakhidze, Head of Enterprise Solutions beim Technologie- und Dienstleistungsanbieter ZL Tech. Die Kuratierung von Unternehmensdatenspeichern erfordert auch konsistente Aufbewahrungsrichtlinien, um alte Informationen aus dem Verkehr zu ziehen, insbesondere jetzt, da Daten aus der Zeit vor der COVID-19-Pandemie auf dem heutigen Markt oft nicht mehr korrekt sind.
Daher sollten die Datenmanagementteams vor dem Einsatz von Big-Data-Systemen die Arten, Schemata und Verwendungszwecke der Daten planen. „Doch das ist leichter gesagt als getan“, sagt Travis Rehl, Vice President of Product beim Cloud-Management-Plattformanbieter CloudCheckr. „Oftmals beginnt man mit einem Datenmodell und erweitert es, stellt aber schnell fest, dass das Modell nicht zu den neuen Datenpunkten passt und man plötzlich technische Schulden hat, die man beseitigen muss.“
Ein generischer Data Lake mit der passenden Datenstruktur kann die effiziente und kostengünstige Wiederverwendung von Daten erleichtern. So bieten beispielsweise Parquet-Dateien oft ein besseres Kosten-Leistungsverhältnis als CSV-Dumps innerhalb eines Data Lakes.
5. Big-Data-Technologien evaluieren und auswählen
Datenmanagementteams können aus einer breiten Palette von Big-Data-Technologien wählen, und die verschiedenen Tools überschneiden sich häufig in ihren Funktionen.
Lenley Hensarling, Chief Strategy Officer beim NoSQL-Datenbankunternehmen Aerospike, empfiehlt Teams, zunächst den aktuellen und künftigen Bedarf an Daten aus Streaming- und Batch-Quellen wie Mainframes, Cloud-Anwendungen und Datendiensten von Drittanbietern zu prüfen. Als Streaming-Plattformen für Unternehmen kommen beispielsweise Apache Kafka, Apache Pulsar, Amazon Kinesis und Google Pub/Sub in Frage, die alle eine nahtlose Übertragung von Daten zwischen Cloud-, On-Premises- und Hybrid-Cloud-Systemen ermöglichen.
Als Nächstes sollten die Teams mit der Bewertung der komplexen Datenaufbereitungsfunktionen beginnen, die für die Einspeisung von KI, maschinellem Lernen und anderen fortschrittlichen Analysesystemen erforderlich sind. Es ist auch wichtig, zu planen, wo die Daten verarbeitet werden. In Fällen, in denen Latenzzeiten ein Problem darstellen, müssen Teams überlegen, wie sie Analyse- und KI-Modelle auf Edge-Servern ausführen und wie sie die Aktualisierung der Modelle vereinfachen können.
Diese Möglichkeiten müssen gegen die Kosten für die Bereitstellung und Verwaltung der Geräte und Anwendungen abgewogen werden, die On-Premises, in der Cloud oder an der Edge ausgeführt werden.
6. Geschäftseinblicke gewinnen
Es ist für Datenteams verlockend, sich auf die Big-Data-Technologie zu konzentrieren, anstatt auf die Ergebnisse. In vielen Fällen hat Silipo festgestellt, dass der Frage, was mit den Daten geschehen soll, viel weniger Aufmerksamkeit geschenkt wird.
Um aus Big-Data-Anwendungen in Unternehmen wertvolle Geschäftseinblicke zu gewinnen, müssen Szenarien wie die Erstellung von KPI-basierten Berichten, die Identifizierung nützlicher Vorhersagen oder die Erstellung verschiedener Arten von Empfehlungen in Betracht gezogen werden.
Diese Bemühungen erfordern eine Mischung aus Fachleuten für Unternehmensanalysen, Statistikern und Datenwissenschaftlern mit Fachkenntnissen im Bereich maschinelles Lernen. Die Kombination dieser Gruppe mit dem Big-Data-Engineering-Team kann den ROI für die Einrichtung einer Big-Data-Umgebung erheblich steigern.
7. Mitarbeiter mit Big-Data-Kenntnissen einstellen und binden
„Eine der größten Herausforderungen bei der Entwicklung von Big-Data-Software ist es, Mitarbeiter mit Big-Data-Kenntnissen zu finden und zu halten“, sagt Mike O'Malley, Senior Vice President of Strategy bei SenecaGlobal, einem Unternehmen für Softwareentwicklung und IT-Outsourcing.
Dieser spezielle Big-Data-Trend wird wahrscheinlich nicht so bald verschwinden. Einem Bericht von S&P Global zufolge gehören Cloud-Architekten und Datenwissenschaftler zu den am stärksten nachgefragten Positionen im Jahr 2021. Eine Strategie zur Besetzung dieser Stellen ist die Zusammenarbeit mit Softwareentwicklungsdienstleistern, die bereits einen Talentpool aufgebaut haben.
„Eine andere Strategie besteht darin, mit der Personalabteilung zusammenzuarbeiten, um etwaige Lücken bei den vorhandenen Big-Data-Talenten zu ermitteln und zu schließen“, sagt Pablo Listingart, Gründer und Eigentümer von ComIT, einer gemeinnützigen Organisation, die kostenlose IT-Schulungen anbietet. „Viele Big-Data-Initiativen scheitern aufgrund falscher Erwartungen und fehlerhafter Schätzungen, die sich vom Anfang bis zum Ende des Projekts fortsetzen.“
Das richtige Team wird in der Lage sein, Risiken abzuschätzen, den Schweregrad zu bewerten und eine Vielzahl von Big-Data-Herausforderungen zu lösen. Es ist auch wichtig, eine Kultur zu etablieren, die es ermöglicht, die richtigen Talente zu gewinnen und zu halten.
Vojtech Kurka, CTO beim Anbieter von Kundendatenplattformen Meiro, sagt, er habe sich anfangs vorgestellt, dass er jedes Datenproblem mit ein paar SQL- und Python-Skripten an der richtigen Stelle lösen könne. Im Laufe der Zeit erkannte er, dass er viel mehr erreichen konnte, wenn er die richtigen Mitarbeiter einstellte und eine sichere Unternehmenskultur förderte, in der die Mitarbeiter zufrieden und motiviert sind.
8. Die Kosten nicht aus dem Ruder laufen lassen
Eine weitere häufige Big-Data-Herausforderung ist das, was David Mariani, Gründer und CTO des Datenintegrationsunternehmens AtScale, als „Cloud-Rechnung-Herzinfarkt“ bezeichnet. Viele Unternehmen verwenden bestehende Datenverbrauchsmetriken, um die Kosten ihrer neuen Big-Data-Infrastruktur abzuschätzen – doch das ist ein Fehler.
Ein Problem besteht darin, dass Unternehmen den schieren Bedarf an Rechenressourcen unterschätzen, der durch den erweiterten Zugriff auf umfangreichere Datensätze entsteht. Vor allem die Cloud erleichtert es Big-Data-Plattformen, umfangreichere und detailliertere Daten zu veröffentlichen, eine Fähigkeit, die die Kosten in die Höhe treiben kann, da Cloud-Systeme elastisch skaliert werden können, um der Benutzernachfrage gerecht zu werden.
Die Verwendung eines On-Demand-Preismodells kann ebenfalls die Kosten erhöhen. Eine Best Practice ist die Entscheidung für feste Ressourcenpreise, aber das löst das Problem nicht vollständig. Auch wenn der Zähler bei einem festen Betrag stehen bleibt, können schlecht geschriebene Anwendungen immer noch Ressourcen verbrauchen, die sich auf andere Benutzer und Workloads auswirken. Eine weitere Best Practice ist daher die Implementierung fein abgestufter Kontrollen für Abfragen. „Ich habe mehrere Kunden erlebt, bei denen Benutzer schlecht konzipierte SQL-Abfragen im Wert von 10.000 Dollar geschrieben haben“, sagt Mariani.
Rehl von CloudCheckr empfiehlt außerdem, dass Datenmanagementteams die Kostenfrage in ihren Gesprächen mit Geschäfts- und Datentechnikteams über Big-Data-Implementierungen im Vorfeld ansprechen. Die Softwareentwickler sollten für die Bereitstellung der Daten in einem effizienten Format verantwortlich sein, und DevOps ist dafür zuständig, dass die richtigen Archivierungsrichtlinien und Wachstumsraten überwacht und verwaltet werden.
9. Big-Data-Umgebungen managen
Fragen des Datenmanagements sind umso schwieriger zu lösen, je mehr Big-Data-Anwendungen auf immer mehr Systemen eingesetzt werden. Dieses Problem wird noch dadurch verschärft, dass neue Cloud-Architekturen es Unternehmen ermöglichen, alle gesammelten Daten in ihrer unaggregierten Form zu erfassen und zu speichern. Geschützte Informationsfelder können sich versehentlich in eine Vielzahl von Anwendungen einschleichen.
„Ohne eine Data-Governance-Strategie und Kontrollen kann meiner Erfahrung nach ein Großteil der Vorteile eines breiteren und tieferen Datenzugriffs verloren gehen“, sagt Mariani.
Eine Best Practice ist es, Daten wie ein Produkt zu behandeln, mit eingebauten Governance-Regeln, die von Anfang an eingeführt werden. Wenn man im Vorfeld mehr Zeit in Identifizierung und Management von Big-Data-Governance-Problemen investiert, ist es einfacher, einen Self-Service-Zugang bereitzustellen, der nicht für jeden neuen Anwendungsfall überwacht werden muss.
10. Sicherstellen, dass der Datenkontext und die Anwendungsfälle verstanden werden
Unternehmen neigen auch dazu, der Technologie zu viel Bedeutung beizumessen, ohne den Kontext der Daten und ihren Nutzen für das Unternehmen zu verstehen.
„Es wird oft viel Aufwand betrieben, um über Big-Data-Speicherarchitekturen, Sicherheits-Frameworks und Ingestion nachzudenken, aber es wird sehr wenig über das Onboarding von Nutzern und Anwendungsfällen nachgedacht“, sagt Adam Wilson, CEO des Anbieters von Data Wrangling Tools Trifacta.
Die Teams müssen sich Gedanken darüber machen, wer die Daten veredeln wird und wie. Diejenigen, die sich am besten mit den geschäftlichen Problemen auskennen, müssen mit denjenigen zusammenarbeiten, die sich am besten mit der Technologie auskennen, um die Risiken zu managen und die richtige Abstimmung zu gewährleisten. Dazu gehört auch, dass man darüber nachdenkt, wie man das Data Engineering demokratisieren kann. Es ist auch hilfreich, einige einfache End-to-End-Anwendungsfälle zu entwickeln, um erste Erfolge zu erzielen, die Grenzen zu verstehen und die Benutzer einzubinden.







