
pressmaster - stock.adobe.com
Die unterschiedlichen Speichertypen für Rechenzentren erklärt
Rechenzentren sollten alternative Speichervarianten für verschiedene Zwecke in Betracht ziehen, darunter hybride Speicher-Arrays, virtuelle Speicher, Cloud-Storage und On-Premises.
Die meisten Unternehmen haben mehrere Arten von Daten zu speichern. Datengröße, Zugriffsgeschwindigkeit und Anwendungspriorität bestimmen, welche Art von Speicher für die verschiedenen Daten benötigt wird. Daher verwenden viele Unternehmen im Rechenzentrum mehrere verschiedene Speichertypen und nicht nur einen einheitlichen Speichertyp.
Zwei wichtige Formen des Storage im Rechenzentrum sind das Storage Area Network (SAN) und Network-Attached Storage (NAS). Ein SAN verwendet eine Netzwerk-Fabric und Switches, um Server mit dem Speicher zu verbinden. SANs eignen sich gut für Block-I/Os und strukturierte Daten, wie relationale Datenbanken.
SANs erfordern entweder Fibre-Channel-Netzwerke oder Ethernet, zum Beispiel iSCSI. NAS hingegen greift über ein Protokoll auf Dateien zu und ist optimal für Remote File Serving geeignet. NAS arbeitet wie ein Server mit eigenem Dateiserver und bietet eine zentralisierte Datenverwaltung. Es ist am besten für unstrukturierte Daten geeignet.
Hybride Speicher-Arrays
Hybride Speicher-Arrays vereinen verschiedene Speichertypen, indem sie Flash, Festplattenlaufwerke (HDDs), Bänder sowie objekt- und Cloud-basierten Speicher in einer einzigen Speicherinfrastruktur vereinen. Datenformate wie Live-Daten, Dateiserverdaten, Streaming-Daten und virtuelle Systeme haben oft unterschiedliche Speicheranforderungen. Ein hybrides Speicher-Array kann die Geschwindigkeit und die geringe Latenz von Flash mitbringen, aber dennoch die Flexibilität und die niedrigeren Kosten von HDDs, Bändern und Clouds bieten. Ein hybrides Speichersystem ist jedoch komplexer als ein reines Flash- oder Festplattensystem.
Ein hybrides Storage-Array erfordert in der Regel eine Tiering-Software. Diese Software hilft bei der Einteilung der Daten in verschiedene Tiers (Ebenen) im Speichersystem auf der Grundlage von Faktoren wie Zugriffsaktivität, Durchsatzanforderungen und Redundanz und hilft somit bei der Festlegung, wo bestimmte Daten innerhalb des Systems gespeichert werden.
Storage-Virtualisierung
Der Prozess der Speichervirtualisierung kann Unternehmen dabei helfen, mehr als einen Speichersystemtyp zu hosten und die Speicherkosten besser vorherzusagen. Viele Anbieter bieten Software-Management-Tools an, die bei der Virtualisierung von Speicher helfen können, darunter Flexify.IO, Nutanix AOS, StarWind Virtual SAN und DataCore SANsymphony.
Verschiedene Speichervirtualisierungs-Tools können Speicher-Hardware virtualisieren, virtualisierten Speicher über hyperkonvergente Infrastrukturen erstellen oder sich auf Cloud-native Speicher spezialisieren. Darüber hinaus unterstützen einige Tools unterschiedliche Speichertypen; bestimmte Tools arbeiten nur mit Blockspeicher, andere wiederum auf Dateiebene. Berücksichtigen Sie den Speichertyp, die Verfügbarkeit und die Verwendung von Verwaltungs-Tools.
Wenn Sie verschiedene virtuelle Festplatten in Betracht ziehen, insbesondere VMware, wählen Sie zwischen Raw-, Thin- und Thick-Disks. Eine Raw Disk verbindet eine logische Speichereinheit direkt mit einer VM innerhalb eines SAN. Eine Raw-Disk speichert die Festplattendaten einer VM in einer kleinen Festplattendeskriptor-Datei im Arbeitsverzeichnis dieser VM und verbessert die I/O-Anwendungsleistung. Eine Thick-Disk kann dagegen die Leistung und Sicherheit erhöhen, indem sie Thick Provisioning zur Vorabzuweisung von physischem Speicher verwendet. Eine Thin Disk schließlich optimiert die Festplatteneffizienz, indem sie nur so viel Speicherplatz verbraucht, wie sie für ihre Funktion benötigt.
Data Lake vs. Data Warehouse und Cloud vs. On-Premises
Ein Data Lake ist ein großes Repository, in dem Rohdaten in ihrem nativen Format gespeichert werden. Im Gegensatz zu einem traditionellen Data Warehouse, das Daten in hierarchischen Ebenen speichert, speichert ein Data Lake Daten als Dateien oder Objekte in einer flachen Architektur.
Sowohl Data Lakes als auch Data Warehouses benötigen viel Speicherplatz, insbesondere in großen Unternehmen. Viele Speicherhersteller bieten spezialisierte Produkte für jede Speicherarchitektur an. So eignen sich beispielsweise die Elastic Data Platform von Dell EMC und Hitachi Vantara für groß angelegte, lokale Data-Lake-Implementierungen. Anbieter wie IBM, NetApp und HPE haben Angebote, die für beide Architekturen geeignet sind. Cloud-Anbieter wie AWS, Microsoft Azure und Google Cloud Platform offerieren Storage als Service für beide Architekturen an.
Speicher für Container
Aufgrund der inhärenten Agilität von Containern benötigen Anwendungsentwickler, die mit ihnen arbeiten, persistenten Speicher für die von ihnen bereitgestellten Container.
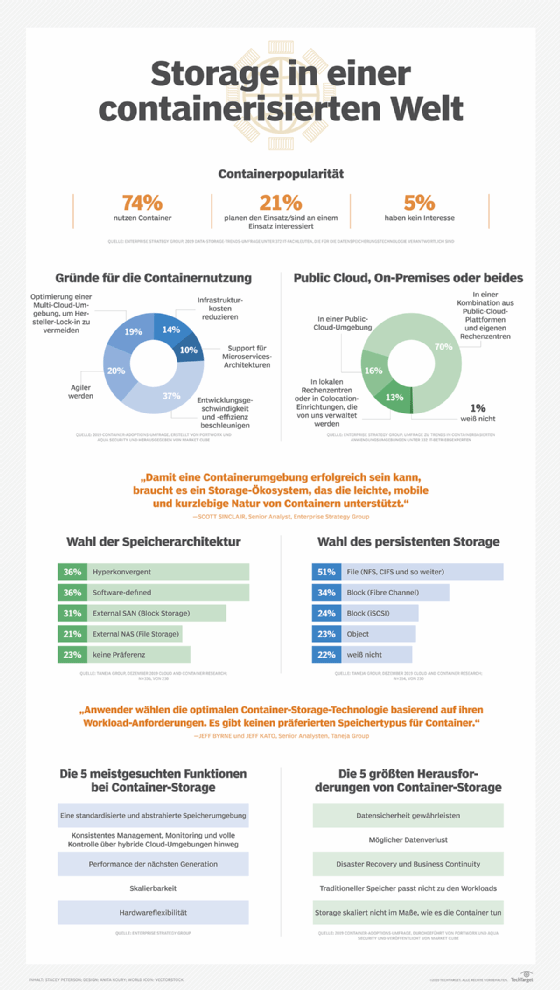
Container-Architekturen erfordern drei Arten von Speicher: Image-Speicher, einen Datenspeicher für die Container-Verwaltung und Container-Anwendungsspeicher. Rechenzentren können Images und Container-Verwaltungsdaten mit bestehenden Shared-Storage-Architekturen speichern. Für die Speicherung von Containeranwendungen ist jedoch ein spezielles System-Daten-Volume - oder persistentes Volume - im Namensraum des Containers erforderlich, um dem Container direkten Zugriff auf ein Verzeichnis oder eine Dateifreigabe des Hostsystems zu ermöglichen.





