Persistenten Speicher für Container in der Cloud einrichten
Alle großen Cloud-Anbieter bieten Container als Service an. Es gibt verschiedene Möglichkeiten für IT-Administratoren, persistenten Speicher für diese flexiblen Umgebungen zu aktivieren.
Container-Instanzen sind ephemer; sobald ein einzelner Container zerstört wird, hinterlässt er nichts mehr. Folglich müssen Workloads, die Persistenz benötigen - sei es durch das Speichern von Status und Arbeitsprodukten oder den Zugriff auf eine gemeinsame Datenbank - eine Schnittstelle zu externen Systemen haben.
Um diesem Bedarf gerecht zu werden, bieten Verwaltungsplattformen wie Docker und Kubernetes sowie Cloud-Container-Verwaltungsdienste von AWS, Azure und Google Mechanismen zur Verbindung mit Speicher-Volumes, Netzwerkdateisystemen und Datenbanken.
Da es viele Möglichkeiten gibt, persistenten Speicher für Container in der Cloud zu implementieren, müssen Administratoren die Option wählen, die am besten für ihre individuellen Speicheranforderungen geeignet ist.
Hintergrund zu CaaS und Kubernetes
Container as a Service (CaaS)-Angebote sind aufgrund ihrer Bequemlichkeit, Portabilität, Sicherheit, Skalierbarkeit, Leistung und Flexibilität zu immer beliebteren Alternativen zu selbstverwalteten Kubernetes-Installationen geworden. Die Vielseitigkeit von in der Cloud gehosteten Containern, die eine Vielzahl von nativen Diensten der Cloud-Anbieter nutzen können, ist ein wesentlicher Anreiz für Unternehmen, die Online-Dienste einer privaten Container-Infrastruktur vorziehen.
Kubernetes hat sich zur bevorzugten Cluster-Management-Plattform entwickelt. Sie ist über Angebote wie Amazon Elastic Kubernetes Service (EKS), Azure Kubernetes Service (AKS) und Google Kubernetes Engine (GKE) verfügbar. Nichtsdestotrotz haben Cloud-Benutzer immer noch mehrere Möglichkeiten, Cluster-Knoten bereitzustellen, entweder über dedizierte Recheninstanzen wie Amazon Elastic Compute Cloud oder On-Demand-Container-Instanzen über Dienste wie AWS Fargate, Azure Container Instances oder GKE Node Auto-Provisioning.
Unabhängig davon, wie Admins Cluster-Knoten bereitstellen, bietet die Kubernetes-Kontrollebene mehrere Möglichkeiten, sich mit persistenten Volumes und File Shares zu verbinden, einschließlich solcher, die von Cloud-Speicherdiensten erstellt wurden.
Kubernetes-Speicheroptionen
Die Speichernutzung in Kubernetes kann aufgrund der Flexibilität der Plattform und der Unterstützung für so viele Speicherplattformen verwirrend sein. In Wirklichkeit ist Kubernetes-Speicher konzeptionell einfach und läuft darauf hinaus, einen Pod - einen oder mehrere Container, die sich einen Namespace, Volumes und andere Einstellungen teilen - mit einem externen Volume zu verbinden. Volumes können sein:
Eine logische Festplatte und ein Mount Point
Blockspeicherdienste wie Amazon Elastic Block Store (EBS) oder Azure Disk
eine Netzwerk-File-Share, von einem Speicher-Array mit NFS, Ceph (CephFS) oder Cloud-Dateidienste wie Amazon Elastic File System (EFS) oder Google Cloud Filestore
Laut der Kubernetes-Dokumentation ist ein Volume einfach ein Verzeichnis, möglicherweise mit einigen Daten darin, auf das die Container in einem Pod zugreifen können. Der jeweilige Volume-Typ, den ein Administrator verwendet, bestimmt, wie dieses Verzeichnis zustande kommt, das Medium, das es unterstützt, und seinen Inhalt.
Admins verwenden persistente Volumes häufig mit einer Kubernetes-Funktion namens StatefulSets, einer API, die die Bereitstellung und Skalierung eines Satzes von Pods verwaltet.
Die Flexibilität, mehrere Speichertypen zu unterstützen, ergibt sich aus dem Container Storage Interface (CSI), einem Standard für die Offenlegung von Block- und Dateispeicher für Container-Orchestratoren wie Cloud Foundry, Kubernetes, Mesos und Nomad. Pods verwenden die Konfiguration in einer .spec.volumes-Datei, um Volumes zu mounten, aber Administratoren können keine Volumes verschachteln. Ein Volume kann nicht gemountet werden oder symbolische Links zu anderen Volumes haben. Jeder unterstützte Volume-Typ hat ein eigenes Schlüsselwort, wie in der Kubernetes-Dokumentation angegeben; zum Beispiel awsElasticBlockStore für EBS, azureFile für Azure-Dateien oder iscsi für ein SAN-iSCSI-Volume.
Admins verwenden persistente Volumes oft mit einer Kubernetes-Funktion namens StatefulSets, einer API, die das Deployment und die Skalierung einer Gruppe von Pods verwaltet. Sie bietet eindeutige, dauerhafte Identitäten, permanente Host-Namen und geordnete, automatisierte rollierende Code-Updates. Laut Kubernetes-Dokumentation können einzelne Pods in einem StatefulSet ausfallen, aber die dauerhaften Pod-Identifikatoren helfen dabei, bestehende Volumes den neuen Pods zuzuordnen, die diejenigen ersetzen, die ausfallen.
Anwendungen, die in einem Container laufen, können sich auch über IP mit externen Datenbanken verbinden, indem sie Open Database Connectivity-Treiber verwenden, die für die meisten Sprachen verfügbar sind. Einige Cloud-Dienste wie Azure bieten Anweisungen zur Maximierung der Netzwerkleistung und Minimierung des Datenbank-Overheads, wenn Administratoren AKS mit Azure Database for PostgreSQL verbinden.
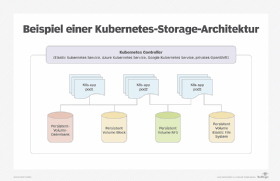
Abbildung 1 zeigt eine Beispielarchitektur für Kubernetes-Speicher.
Andere Cloud-Datenbankdienste verwenden einen Sidecar-Proxy, um Verbindungsmethoden zu unterstützen. Zum Beispiel ist der Google Cloud SQL Proxy eine sichere und zuverlässige Methode, um GKE-Anwendungen mit Cloud SQL-Instanzen zu verbinden. Google bietet Best Practices, um externe Dienste auf Kubernetes abzubilden, zum Beispiel die Erstellung von Service-Endpunkten für externe Datenbanken und die Verwendung von Uniform Resource Identifiers mit Port-Mapping für gehostete Datenbankdienste.
Da CaaS-Produkte vorhandene Speicherschnittstellen nutzen und es CSI-Treiber für Cloud-Block- und -Dateidienste gibt, können Pod-Implementierungen zwischen privaten, selbst verwalteten Speicher-Volumes und Freigaben oder Cloud-Ressourcen wählen.
Zu den beliebtesten CSI-Treiberoptionen gehören:
Amazon EKS EBS CSI-Treiber
Amazon EKS EFS CSI-Treiber
Azure Disk CSI-Treiber
Azure Files AKS CSI-Treiber
GCP GKE Persistent Disk CSI-Treiber
GCP GKE Filestore Verbindungen
GCP Cloud SQL Proxy für GKE
Ebenso können sich Kubernetes-Pods über NFS CSI-Treiber mit privaten NAS verbinden. Mehrere Enterprise-Storage-Anbieter bieten CSI- und Storage-Software an, die für Kubernetes entwickelt wurde, zum Beispiel Dell EMC CSI Plug-ins, NetApp Trident und Pure Storage Portworx.