Speichervirtualisierung (Storage-Virtualisierung)
Was ist Speichervirtualisierung (Storage-Virtualisierung)?
Speichervirtualisierung bezeichnet die Abstraktion physischer Speicherressourcen mehrerer Speichergeräte zu einem einzigen logischen Speicherpool oder virtuellen Gerät. Diese Technologie bündelt physische Speicher in einem zentral verwalteten Pool, um Kapazität, Leistung und Nutzung zu optimieren. Die Verwaltung erfolgt über eine zentrale Konsole, häufig als Single Pane of Glass bezeichnet.
Das Ziel der Speichervirtualisierung ist es, physische Laufwerke und Speichersysteme so zu abstrahieren, dass sie für Anwendungen, Server oder virtuelle Maschinen (VMs) als eine einheitliche logische Ressource erscheinen. Dadurch wird die Speicherverwaltung vereinfacht, da Administratoren Kapazitäten flexibel zuweisen, Daten effizient migrieren und Speicherressourcen dynamisch skalieren können.
Die Virtualisierung verdeckt die zugrunde liegende Komplexität von Speicherarchitekturen wie Storage Area Networks (SANs) oder Network-Attached Storage (NAS). Dadurch werden Aufgaben wie Datensicherung, Replikation, Wiederherstellung und Archivierung deutlich vereinfacht und automatisierbar.
Die Virtualisierungs- und Zentralisierungsfunktionen unterscheiden den Gesamtansatz von Bare-Metal-Speichersystemen, bei denen physische Speichergeräte direkt angesprochen werden müssen. Aus diesem Grund bietet die Virtualisierung auch betriebliche Effizienzvorteile gegenüber der Bare-Metal-Bereitstellung von Speicher. Darüber hinaus kann die Speichervirtualisierung die Leistung von Speicherumgebungen verbessern und Kompatibilitäts- und Sicherheitsprobleme minimieren, da IT-Teams nur ein einziges Gerät anstelle vieler Geräte adressieren müssen.
So funktioniert Speichervirtualisierung
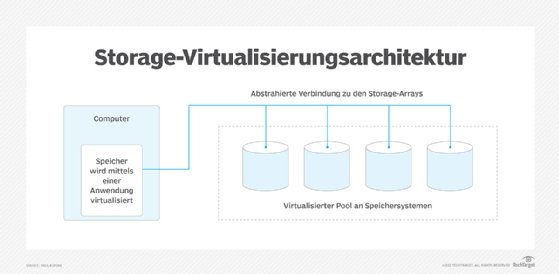
Bei der Speichervirtualisierung werden mehrere physische Speichergeräte logisch zu einem gemeinsamen Speicherpool zusammengefasst. Eine Softwareschicht verwaltet die Zuordnung der logischen zu den physischen Speicherblöcken und lenkt den I/O-Datenverkehr entsprechend um. Diese Schicht trennt die Speicherhardware von den logischen Volumes, sodass Betriebssysteme und Anwendungen unabhängig von der tatsächlichen Speicherarchitektur auf die Daten zugreifen können.
Die Speichervirtualisierungs-Technologie nutzt Software, um die verfügbare Speicherkapazität physischer Geräte zu ermitteln, eine Barriere zwischen den physischen und virtuellen Speichergeräten zu schaffen und anschließend die verfügbare Kapazität zu einem Speicherpool zusammenzufassen, der von Servern mit herkömmlicher Architektur oder in einer virtuellen Umgebung von VMs genutzt werden kann. Die Software ermittelt und fasst nicht nur die verfügbare Speicherkapazität zusammen, sondern stellt diese Kapazität auch verschiedenen Anwendungen zur Verfügung.
Die Virtualisierungssoftware erstellt und pflegt Metadaten über die Zuordnung zwischen logischen und physischen Speicherorten. Moderne Systeme nutzen intelligente Caching-Mechanismen, Thin Provisioning, Deduplizierung und automatische Tiering-Funktionen, um Leistung und Effizienz zu verbessern.
Vorteile und Einsatzmöglichkeiten der Speichervirtualisierung
Die Speichervirtualisierung bietet zahlreiche Vorteile, die sowohl den Betrieb als auch die Wirtschaftlichkeit von IT-Infrastrukturen verbessern. Zu den wichtigsten Vorteilen gehören:
- Zentrale Verwaltung: Eine einheitliche Konsole ermöglicht es, heterogene Speicherressourcen verschiedener Hersteller zentral zu überwachen und zu verwalten.
- Bessere Ressourcenauslastung: Durch Pooling und dynamische Kapazitätszuweisung lässt sich Speicher effizienter nutzen als in isolierten Systemen.
- Kosteneffizienz und Skalierbarkeit: Unternehmen können bestehende Systeme länger nutzen, neue Geräte flexibel einbinden und Hardwarekosten senken.
- Höhere Verfügbarkeit und Fehlertoleranz: Virtualisierte Speicherumgebungen unterstützen Datenreplikation, Snapshots und Live-Migrationen mit minimaler Downtime.
- Performance-Optimierung: Automatisches Tiering und Caching verbessern die I/O-Leistung und stellen wichtige Daten auf schnellen Speichermedien bereit.
- Erweiterte Funktionen: Virtualisierungsschichten ermöglichen standardisierte Implementierungen von Funktionen wie Replikation, QoS (Quality of Service), Deduplizierung und Kompression.
- Integration heterogener Systeme: Alte und neue Speichersysteme, HDDs und SSDs lassen sich gemeinsam betreiben, was Investitionen schützt.
- Cloud- und Edge-Integration: In modernen Umgebungen wird Speichervirtualisierung mit Cloud-Speicher, hyperkonvergenten Infrastrukturen (HCI) und Edge Computing kombiniert.
Nachteile und Herausforderungen
Trotz ihrer zahlreichen Vorteile bringt Storage-Virtualisierung auch einige Herausforderungen mit sich. Viele frühe Probleme wie Performance-Overhead und mangelnde Kompatibilität wurden zwar behoben, dennoch bleiben folgende Punkte relevant:
- Komplexität und Integrationsaufwand: Die Einbindung in bestehende IT-Landschaften kann anspruchsvoll sein.
- Leistungsabhängigkeit von Hardware: Latenzzeiten und Durchsatz hängen stark von Controllerleistung, Netzwerkbandbreite und Caching-Strategien ab.
- Sicherheitsanforderungen: Datenverschlüsselung im Ruhezustand (Data at Rest) und bei der Übertragung (Data in Flight) sowie starke Zugriffskontrollen sind unerlässlich.
- Lizenz- und Verwaltungsaufwand: Kommerzielle Virtualisierungslösungen können zusätzliche Lizenzkosten und Verwaltungsaufwand verursachen.
Arten der Speichervirtualisierung: Block- vs. Datei-basiert
Die Speichervirtualisierung kann auf zwei grundlegend unterschiedliche Arten erfolgen – blockbasiert und dateibasiert:
Dateibasierte Speichervirtualisierung:
- Wird vor allem in NAS-Umgebungen eingesetzt. Sie abstrahiert den Speicherort von Dateien über Protokolle wie SMB (Windows) oder NFS (Linux). Dadurch können Dateien transparent zwischen Geräten migriert werden, ohne dass Nutzer oder Anwendungen davon betroffen sind.
Blockbasierte Speichervirtualisierung:
- In SAN-Umgebungen werden Speicherblöcke über Fibre Channel (FC) oder iSCSI bereitgestellt. Die Virtualisierungssoftware abstrahiert logische Blöcke (LUNs) von den physischen Speichergeräten. Blockbasierte Systeme bieten in der Regel geringeren Overhead und höhere Performance und werden häufig in Rechenzentren eingesetzt.

In-Band- vs. Out-of-Band-Virtualisierung
Je nach Architektur der Datenverarbeitung unterscheidet man zwischen zwei Ansätzen:
- In-Band-Virtualisierung (symmetrisch): Daten- und Steuerinformationen laufen über denselben Pfad. Dadurch können zusätzliche Dienste wie Caching und Replikation direkt integriert werden. Geeignet für kleinere bis mittlere Umgebungen.
- Out-of-Band-Virtualisierung (asymmetrisch): Steuerbefehle und Datenflüsse sind getrennt. Die Datenübertragung erfolgt direkt zwischen Hosts und Speichergeräten, was Engpässe minimiert. Ideal für große Umgebungen mit hohen Leistungsanforderungen.
Virtualisierungsmethoden
Es existieren verschiedene Implementierungsansätze für die Speichervirtualisierung, die sich nach der Ebene unterscheiden, auf der die Virtualisierung stattfindet:
- Host-basierte Virtualisierung: Softwarebasierte Umsetzung in hyperkonvergenten Infrastrukturen oder Cloud-Systemen. Beispiele: VMware vSAN, Microsoft Storage Spaces, Red Hat Ceph Storage.
- Array-basierte Virtualisierung: Ein Speicher-Array übernimmt die Rolle des Controllers, der Kapazitäten mehrerer Arrays zusammenfasst und als logischen Pool bereitstellt.
- Netzwerkbasierte Virtualisierung: Häufigster Ansatz in Unternehmen. Appliances oder intelligente Switches schaffen über Fibre Channel oder iSCSI virtuelle Speicherpools.
Bandmedien und Speichervirtualisierung
Auch wenn Bandmedien im Primärspeicher an Bedeutung verloren haben, spielen sie in der Archivierung weiterhin eine Rolle. Das Linear Tape File System (LTFS) erlaubt den Zugriff auf Bänder über ein Dateisystem ähnlich einem NAS, was die Verwaltung und Wiederherstellung vereinfacht. Durch die Verwendung eines Verzeichnisses auf Dateiebene für den Inhalt des Bandes lassen sich Daten auf dem Band viel einfacher finden und wiederherstellen.
Geschichte und Entwicklung
Die Wurzeln der Speichervirtualisierung reichen in die 1960er-Jahre zurück, als IBM die Idee der Virtualisierung im Großrechnerumfeld einführte. In den 2000er-Jahren etablierten sich blockbasierte Virtualisierungs-Appliances wie der IBM SAN Volume Controller und die Hitachi TagmaStore-Reihe.
Heute ist Speichervirtualisierung eng mit Software-defined Storage (SDS), Cloud Computing, Hyperkonvergenz und Container-Technologien verbunden. Sie ist ein zentrales Element moderner Edge- und Multi-Cloud-Architekturen und bildet die Grundlage für effizientes Storage as a Service (STaaS).
Das Wichtigste auf einen Blick: Speichervirtualisierung
Speichervirtualisierung fasst physische Speicherressourcen zu einem zentral verwalteten, virtuellen Pool zusammen. Dadurch wird der Speicher effizienter genutzt, einfacher verwaltet und flexibler bereitgestellt. Moderne Virtualisierungslösungen bieten hohe Verfügbarkeit, Fehlertoleranz und Skalierbarkeit – wichtige Voraussetzungen für hybride Cloud-, Container- und Edge-Umgebungen.
Unternehmen profitieren vor allem durch:
- Zentrale Verwaltung: Vereinfachte Überwachung und Administration über eine gemeinsame Konsole.
- Bessere Ressourcenauslastung: Dynamische und flexible Zuweisung von Speicherplatz.
- Kosteneffizienz: Weniger Hardwarebedarf, geringerer Wartungsaufwand.
- Hohe Verfügbarkeit & Ausfallsicherheit: Automatisierte Replikation und Migration von Daten.
- Integration mit modernen IT-Architekturen: Unterstützung von Cloud, HCI und Edge-Computing.
Insgesamt bleibt die Speichervirtualisierung eine Schlüsseltechnologie für effiziente, agile und zukunftssichere IT-Infrastrukturen – sowohl im eigenen Rechenzentrum als auch in der Cloud.







