
sdecoret - stock.adobe.com
Die 18 wichtigsten Datenkatalog-Tools und Technologien
Für die Erstellung und Verwaltung von Datenkatalogen gibt es zahlreiche Tools auf dem Markt. Im Folgenden finden Sie die 18 bekanntesten Datenkatalog-Plattformen.

Viele Unternehmen sehen sich mit einer wachsenden Menge an Daten konfrontiert, die sich über verschiedene Datenbanken und andere Repositories in lokalen Systemen, Cloud-Diensten und IoT-Infrastrukturen verteilen. Das macht die Datenverwaltung schwieriger, und BI- und Datenanalyse-Initiativen sind weniger effektiv, wenn Data Scientists, Datenanalysten und Geschäftsanwender die relevanten Daten nicht finden und deren Bedeutung nicht verstehen können. „Unternehmen ertrinken in Daten und hungern nach Erkenntnissen“, sagt Priya Iragavarapu, Vice President of Data Science and Analytics beim Beratungsunternehmen AArete.
Datenkataloge können eine einheitliche Sicht auf alle Datenbestände in einem Unternehmen bieten. Die Idee eines Katalogs gibt es schon seit den Anfängen der relationalen Datenbanken, als IT-Teams den Überblick darüber behalten wollten, wie Datensätze über SQL-Tabellen hinweg verknüpft, verbunden und transformiert wurden. Moderne Datenkatalog-Tools inventarisieren Daten und sammeln Metadaten aus einer Vielzahl von Datenspeichern, darunter Data Lakes, Data Warehouses, NoSQL-Datenbanken und Cloud-Objektspeicher.
Sie werden auch häufig in Data-Governance-Software integriert, um Unternehmen dabei zu unterstützen, mit den sich ändernden Anforderungen an die Einhaltung von Vorschriften und anderen Aspekten von Governance-Programmen Schritt zu halten. Darüber hinaus entwickeln sich die Tools weiter, um die Vorteile von Abfragen in natürlicher Sprache, maschinellem Lernen und anderen KI-Funktionen zu nutzen. Aus diesem Grund bezeichnet das Beratungsunternehmen Gartner sie als erweiterte Datenkatalogisierungs- und Metadatenmanagementlösungen.
Frühere Datenkataloge erforderten benutzerdefinierte Skripte, um Daten zu crawlen und Metadaten zu erfassen. Neuere Tools können dies jedoch automatisch tun und Datenattribute, -typen und -profile dynamisch erfassen.
Im Folgenden finden Sie in alphabetischer Reihenfolge Informationen zu 18 gängigen Datenkatalog-Tools, mit denen Unternehmen die Herausforderungen der Metadatenverwaltung meistern und Daten für Endbenutzer leichter zugänglich und verständlich machen können.
1. Alation Data Catalog
Alation wurde 2012 gegründet und brachte 2015 seine ersten Produkte auf den Markt. Das Flaggschiff des Unternehmens, die Data-Catalog-Software, nutzt KI, maschinelles Lernen, Automatisierung und Techniken zur Verarbeitung natürlicher Sprache, um die Datenerkennung zu vereinfachen, automatisch Geschäftsglossare zu erstellen und die zentrale Behavioral Analysis Engine zu betreiben, die Datennutzungsmuster analysiert, um Datenverwaltung, Data Governance und Abfrageoptimierung zu rationalisieren. Die Engine indexiert verschiedene Datenquellen und nutzt die Mustererkennung, um Beliebtheitsrankings, Nutzungsempfehlungen und andere Erkenntnisse zu generieren.
Alation, das auch eine Data-Governance-Anwendung anbietet, bezeichnet seine Gesamtkombination von Funktionen als Data-Intelligence-Plattform. In diesem Sinne umfasst der Alation Data Catalog eine geführte Navigation und verschiedene Funktionen für die Zusammenarbeit. So können beispielsweise automatisch Datenmanager oder andere Fachexperten identifiziert werden, die Fragen zu Datensätzen beantworten können, und Benutzer können Wiki-Artikel und durchsuchbare Konversationen erstellen. Sie können sich auch anmelden, um automatisch benachrichtigt zu werden, wenn Datensätze oder Artikel aktualisiert werden. Vorgefertigte Analyse-Dashboards bieten anpassbare Berichte und der Alation Cloud Service bietet Data Intelligence as a Service.
Weitere wichtige Funktionen des Alation-Tools sind:
- Die Möglichkeit, Datenprobleme zu erkennen und Unternehmensrichtlinien für die Datenverwaltung zu definieren.
- Vorgefertigte Konnektoren zu verschiedenen Datenquellen sowie ein Open Connector Framework SDK zur Erstellung eigener Konnektoren.
- Ein integrierter SQL-Editor, der als Alternative zur natürlichen Sprachsuche verwendet werden kann.
2. Alex Augmented Data Catalog
Alex Solutions ist ein neuerer Anbieter von Datenkatalogen und Metadatenmanagement, der 2016 gegründet wurde. Das Unternehmen hat seine Datenkatalogsoftware so konzipiert, dass sie die Vorteile von KI und maschinellen Lerntechniken nutzt. Alex Augmented Data Catalog hilft dabei, den Prozess der Erkennung von Datenbeständen zu automatisieren und sie dann in einen konsolidierten Katalog zu bringen, der verschiedene Arten von strukturierten, semistrukturierten und unstrukturierten Daten unterstützt. Das Tool umfasst auch eine Reihe von Funktionen für die Zusammenarbeit, zum Beispiel für die gemeinsame Datennutzung und -kuratierung.
Darüber hinaus automatisiert Alex verschiedene Aspekte der Data Governance und der Datenqualität innerhalb des Datenkatalog-Tools. Beispielsweise können Data-Governance-Manager von einer zentralen Konsole aus Richtlinien erstellen, Data Stewards zuweisen und die Datenpipeline-Prozesse verfolgen.
Alex Augmented Data Catalog bietet außerdem folgende Funktionen:
- Google-ähnliche Such- und Abfragefunktionen in natürlicher Sprache.
- Einen Marktplatz mit Plug-and-Play-Metadatenkonnektoren für gängige Datenquellen.
- Integrierte Automatisierung für das Auffüllen und Anreichern von Metadaten in Datenkatalogen.
3. Ataccama Data Catalog
Das 2008 gegründete Unternehmen Ataccama bietet ein Datenkatalog-Tool als Kernkomponente von Ataccama One an, einer konsolidierten Plattform, die durch den Einsatz von KI automatisierte Data-Governance- und Management-Funktionen unterstützt. Der Ataccama Data Catalog kann Daten aus Datenbanken, Data Lakes, Dateisystemen und anderen Quellen katalogisieren und verfügt über Konnektoren für eine Vielzahl von gängigen On-Premises- und Cloud-Datenplattformen.
Der Datenkatalog umfasst Funktionen zur Automatisierung der Datenerkennung und Erkennung von Änderungen. Das Tool kann auch Datenqualitätsbewertungen automatisieren und Datenanomalien erkennen und kennzeichnen. Es kann in Geschäftsprozessmanagement-Workflows eingebunden werden, um die Durchsetzung von Datenrichtlinien zu automatisieren. Es unterstützt Workflows, die eine Vielzahl von Rollen in Unternehmen abdecken, darunter Datenverwalter, Dateningenieure, Geschäftsanwender, Datenanalysten und Systembesitzer.
Ataccama Data Catalog beinhaltet außerdem folgende Funktionen:
- Ein Fokus auf die Verbesserung der Datenqualität durch kontinuierliche Qualitätsüberwachung und Datenbereinigung.
- Integrierte Funktionen für die Erstellung von Datenprofilen, die Datenklassifizierung, die Datenabfolge, die Beobachtbarkeit von Daten, die Erkennung von Beziehungen und die Verwaltung von Metadaten.
- Funktionen zur Konfiguration von Workflows, Benutzerberechtigungen und benutzerdefinierten Metadaten.
4. Atlan Data Discovery & Catalog
Atlan ist einer der jüngsten Anbieter von Datenkatalogen und kam 2018 mit seinem Tool auf den Markt. Das Unternehmen positioniert sein Produkt als Datenkatalog der dritten Generation, der auf Designprinzipien von GitHub, Slack und anderen Endbenutzer-Tools basiert. Insbesondere ist Atlan Data Discovery & Catalog darauf ausgelegt, eine einfache Zusammenarbeit zu unterstützen und gemeinsame Daten-Workflows nahtlos zu integrieren.
So können Datenteams beispielsweise Probleme, die behoben werden müssen, direkt aus dem Datenkatalog-Tool heraus markieren. Es unterstützt kontextbezogene Diskussionen in Slack-Chats, die die Vorteile einer Reverse-Metadaten-Funktion nutzen können, und einzelne Benutzer können Jira-Anfragen erstellen, um Probleme bei der Erkundung von Datensätzen zu melden.
Die Software umfasst außerdem die folgenden Funktionen, um die Integration mit gängigen Datenquellen und Datenqualitätstools zu vereinfachen:
- Offene APIs, die eine vollständig anpassbare Aufnahme von Metadaten ermöglichen.
- Programmierbare Bots zur Automatisierung von Aufgaben durch benutzerdefinierte Algorithmen für maschinelles Lernen und Data Science.
- Ein Plug-in-Marktplatz mit Konnektoren zu verschiedenen Daten-Tools und Plattformen.
5. AWS Glue Data Catalog
AWS Glue Data Catalog ist der persistente Metadatenspeicher in AWS Glue, einem vollständig verwalteten ETL-Service, der von AWS angeboten wird. Der Datenkatalog ermöglicht es Datenverwaltungsteams, Metadaten für die Verwendung in ETL-Integrationsaufträgen zu speichern, mit Anmerkungen zu versehen und gemeinsam zu nutzen, wenn sie Data Warehouses oder Data Lakes auf der AWS-Cloud-Plattform erstellen. Er unterstützt ähnliche Funktionen und ist mit dem Metaspeicher-Repository in Apache Hive, einem beliebten Open Source Data Warehouse Tool, kompatibel. In einigen Fällen können Unternehmen auch den AWS-Datenkatalog als externen Metaspeicher für Hive-Daten integrieren.
Benutzer können den Zugriff auf den AWS Glue Data Catalog innerhalb eines Unternehmens mit ihren AWS Identity and Access Management (IAM) Anmeldeinformationen freigeben. Das Datenkatalog-Tool hilft bei der Durchsetzung von Data-Governance-Anforderungen, indem es Änderungen an Schemata und Datenzugriffskontrollen verfolgt. Darüber hinaus unterstützt es Datenprozesse, die verschiedene AWS-Services umfassen, darunter AWS Lake Formation, Amazon Athena, Amazon Redshift, Amazon EMR und andere. AWS Glue Data Catalog kann auch zum Auffüllen von Geschäftsdatenkatalogen in Amazon DataZone verwendet werden, einem separaten Datenmanagementdienst, der ab Ende 2023 allgemein verfügbar ist.
Zu den weiteren Funktionen der AWS-Software gehören:
- Die Möglichkeit, Skripte zu schreiben, um Repositories automatisch zu crawlen und Informationen über Schemata und Datentypen zu erfassen.
- Verbesserte Sichtbarkeit, Kontrolle und Steuerung von Datenbeständen über verschiedene AWS-Datenservices hinweg.
- Eine Einstellungsseite in der AWS Glue-Verwaltungskonsole zum Ändern von Berechtigungen und anderen Datenkatalogeigenschaften.
6. Boomi Data Catalog and Preparation
Boomi Data Catalog and Preparation ist Teil der AtomSphere-Plattform des Unternehmens, einem Portfolio von Tools, das auch Datenintegration, Stammdatenmanagement und andere Funktionen unterstützt. Es kombiniert einen Datenkatalog mit Datenaufbereitungsfunktionen. Unternehmen können mit dem Katalog ein konsolidiertes Geschäftsglossar mit Metadaten erstellen, um Datensätze, Verarbeitungsaufträge und Workflow-Zeitpläne zu verfolgen, und dann eine Datenaufbereitungs-Empfehlungsmaschine ausführen, um Daten automatisch zu bereinigen, anzureichern, zu normalisieren und umzuwandeln.
Das Katalog-Tool umfasst Konnektoren zu mehr als 1.000 Endpunkten, darunter mehr als 200 Anwendungen. IT- und Datenmanagementteams können auch Datenpipelines erstellen, um Workflows für Analysen, maschinelles Lernen und KI-Prozesse zu automatisieren. Eine Reihe von Data-Governance- und Sicherheitsfunktionen kann die Kontrolle über verschiedene Anwendungen und Geschäftsprozesse verbessern.
Boomi Data Catalog and Preparation umfasst außerdem folgende Funktionen:
- Unterstützung für natürlichsprachliche Abfragen und personalisierte Suchen.
- Die Möglichkeit, die Software in der Cloud, On-Premises oder in hybriden Umgebungen einzusetzen und auszuführen.
- Funktionen für die Zusammenarbeit, wie zum Beispiel die Möglichkeit, Daten zu bewerten und zu kommentieren und Datenverwalter um Zugriff auf benötigte Datensätze zu bitten.
7. Collibra Data Catalog
Collibra wurde 2008 gegründet und bietet eine Data-Intelligence-Cloud-Plattform an, deren Kernstück der Collibra Data Catalog ist. Die Funktionen des Datenkatalogs unterstützen ein umfangreiches Set an automatisierten Funktionen für die Erkennung und Klassifizierung von Daten mithilfe eines proprietären Algorithmus für maschinelles Lernen, die Kuratierung von Daten, die ebenfalls durch maschinelles Lernen unterstützt wird, und die Datenabfolge. Das Datenkatalog-Tool unterstützt außerdem graphenbasierte Metadaten-Management-Techniken, die den Nutzern Informationen über die Datenqualität und die Herkunft der Daten liefern.
Collibra Data Catalog enthält vorgefertigte Integrationen für die Aufnahme von Metadaten aus verschiedenen Datenspeichern sowie aus gängigen Geschäftsanwendungen, BI-Plattformen und Data Science Tools. Darüber hinaus bietet Collibra Data Catalog eingebettete Data-Governance-Funktionen, geführte Data-Stewardship-Funktionen und granulare Kontrollen zur Durchsetzung von Datensicherheit und Datenschutz – alles in einer einzigen Konsole.
Darüber hinaus bietet die Collibra-Software folgende Funktionen:
- Ein Geschäftsglossar zur Standardisierung der Terminologie sowie automatisierte Data Governance Workflows und Dashboards.
- Funktionen zur Zusammenarbeit, einschließlich Crowdsourced Feedback zu Datenbeständen durch Bewertungen, Rezensionen und Kommentare.
- Ein Dateneinkaufserlebnis, das es den Benutzern ermöglicht, nach relevanten Daten zu suchen, ohne dass eine SQL-Kodierung erforderlich ist.
8. Daten.world
Data.world ist ein Cloud-natives Datenkatalog-Tool, das als SaaS-Plattform von einem gleichnamigen Anbieter angeboten wird. Das 2015 gegründete Unternehmen veröffentlicht nach eigenen Angaben mehr als 1.000 einzelne Produkt-Updates pro Jahr. Es ist bekannt für einen Knowledge-Graph-Ansatz, der eine semantisch organisierte Ansicht der Unternehmensdaten und der zugehörigen Metadaten über verschiedene Systeme hinweg bietet. Dies soll es Geschäfts- und Analyseanwendern erleichtern, relevante Daten zu finden und deren Kontext zu verstehen.
Im Jahr 2022 fügte Data.world eine Reihe von Datenkatalogfunktionen hinzu, die auf Wissensgraphen basieren und die Nutzung der Plattform vereinfachen. Die Suite mit dem Namen Eureka umfasst eine Reihe von Automatisierungen, die bei der Bereitstellung und Verwaltung von Datenkatalogen unterstützen, ein Action Center Dashboard, das Metriken, Warnungen und Empfehlungen liefert, sowie weitere Funktionen. Im Jahr 2023 erhielt die Datenkatalogsoftware Funktionen, die durch generative KI unterstützt werden, um die Datenerkennung zu verbessern. KI-Bots können bei der Datensuche helfen, Forschungsfragen und Analysehypothesen vorschlagen, Fragen in natürlicher Sprache in SQL-Code umwandeln und automatisch Beschreibungen in natürlicher Sprache für Metadatenressourcen generieren.
Zu den weiteren bemerkenswerten Funktionen der Data.world-Software gehören:
- Funktionen zur Zusammenarbeit, um Arbeitsabläufe zu rationalisieren und den Wissensaustausch zwischen Datenproduzenten und -nutzern zu ermöglichen.
- Die Fähigkeit, Metadaten automatisch zu organisieren, zu aggregieren und in einem Format zu präsentieren, das die Nutzung und den Austausch zwischen Mitarbeitern erleichtert.
- Unterstützung von virtualisiertem und föderiertem Datenzugriff mit integrierten Data-Governance-Kontrollen.
9. Erwin Data Catalog
Die erste Erwin-Software wurde 1983 für die Datenmodellierung entwickelt; im Laufe der Jahre wurde die Produktlinie mehrfach aufgekauft und gehört jetzt Quest Software. Sie wurde weiterentwickelt, um zusätzliche Funktionen zu unterstützen, darunter dieses Datenkatalog-Tool, das als Teil einer breiteren Plattform entwickelt wurde, die 2017 zur Unterstützung verschiedener Aspekte der Data Governance eingeführt wurde.
Erwin Data Catalog by Quest, so der offizielle Name der Software, sammelt, katalogisiert und kuratiert Metadaten automatisch. Sie umfasst auch Komponenten für Datenmapping, Referenzdatenmanagement, Data Lifecycle Management (DLM), Datenqualitätsintegration, Datenabgleich und andere Funktionen. Standard-Datenkonnektoren können Daten aus gängigen Datenbanken aufnehmen, optionale Konnektoren können für Streaming-Daten, Cloud-Anwendungen, BI-Umgebungen und weitere Datenquellen hinzugefügt werden. Darüber hinaus kann die Datenkatalogsoftware zusammen mit den begleitenden Tools für Datenkompetenz und Datenqualität in Erwin Data Intelligence verwendet werden.
Erwin Data Catalog bietet außerdem folgende Funktionen:
- Ein Management-Dashboard, das zur Anzeige und Analyse von Datenkatalogattributen verwendet werden kann.
- Eine Auswirkungsanalysefunktion zur Bewertung der potenziellen Auswirkungen von Änderungen in einem Katalog.
- End-to-End-Datenverlaufsinformationen, die automatisch bis auf Spaltenebene generiert werden und Datenflüsse und -transformationen aufzeigen.
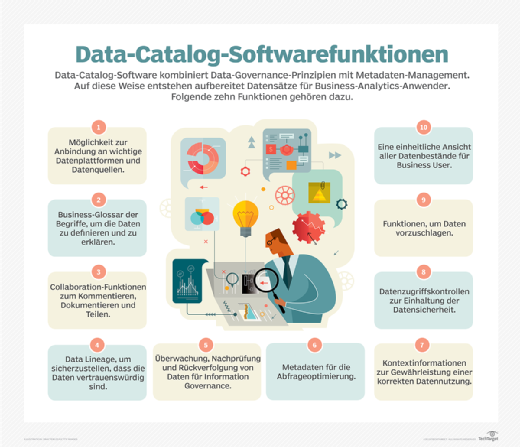
10. Google Cloud Data Catalog
Google Cloud Data Catalog ist ein vollständig verwalteter Datenermittlungs- und Metadatenverwaltungsdienst, der sowohl mit Cloud- als auch mit lokalen Datenquellen funktioniert. Er wurde entwickelt, um sowohl Datenexperten als auch Geschäftsanwendern die Möglichkeit zu geben, einen Katalog durch Abfragen in natürlicher Sprache zu durchsuchen und Daten in großem Umfang zu kennzeichnen. Das Tool verfügt über Integrationen mit den Google-Datendiensten BigQuery, Pub/Sub, Dataproc Metastore und Cloud Storage. Es ist außerdem in die IAM- und Cloud Data Loss Prevention Services des Unternehmens integriert, um die Datensicherheit und das Compliance-Management im Rahmen von Data-Governance-Initiativen zu unterstützen.
Die Datenkatalogsoftware wird als serverloser Dienst bereitgestellt, wodurch die Einrichtung der Infrastruktur und die Verwaltungsaspekte für die Benutzer entfallen. Sie unterstützt die Katalogisierung von Datenbeständen und den Zugriff auf andere Funktionen über die Benutzeroberfläche in Googles Dataplex Data Fabric, eine Befehlszeilenschnittstelle (CLI) sowie eine Reihe von APIs und Client-Bibliotheken. Das Tool kann sowohl technische Metadaten als auch geschäftliche Metadaten wie Tags und Tag-Vorlagen speichern. Auch Dateisatzschemata aus dem Cloud Storage Service und benutzerdefinierte Metadatentypen können gespeichert werden.
Die folgenden Funktionen sind ebenfalls in Google Cloud Data Catalog enthalten:
- Automatische Synchronisierung von technischen Metadaten.
- Unterstützung für die automatische Kennzeichnung von sensiblen Daten.
- Eine einheitliche Ansicht der Daten sowohl in der Cloud als auch in lokalen Systemen.
11. IBM Knowledge Catalog
IBM Knowledge Catalog ist ein Metadaten-Repository, das zur Unterstützung von KI, maschinellem Lernen und anderen Analyse-Workflows entwickelt wurde. Es arbeitet mit dem zugrunde liegenden InfoSphere Information Governance Catalog des Unternehmens zusammen, um Unternehmen dabei zu unterstützen, Daten über Cloud- und On-Premises-Quellen hinweg zu entdecken und zu verwalten. Das Tool kann verschiedene Daten- und Analysebestände katalogisieren, darunter Modelle für maschinelles Lernen sowie strukturierte, unstrukturierte und semistrukturierte Datentypen. Es unterstützt eine intelligente Katalogisierung und Datenerkennung, die durch automatische Suchempfehlungen gesteuert werden kann.
Die Datenkatalogsoftware bietet außerdem ein Self-Service-Portal und automatisierte Data-Governance-Funktionen, einschließlich aktiver Richtlinienverwaltung, rollenbasierter Zugriffskontrolle und dynamischer Maskierung sensibler Daten. Die Software kann in der Cloud, On-Premises oder als vollständig verwalteter Service auf der IBM Cloud Pak for Data Platform bereitgestellt werden. Die jüngste Version, die mit Cloud Pak for Data 4.8 im November 2023 veröffentlicht wurde, bietet neue Datenquellen für den Import von Metadaten, Beziehungsdiagramme zur Visualisierung komplexer Beziehungen zwischen Assets, neue Benutzerberechtigungen für Datenqualitätskontrollen, automatisches Mapping logischer Datenmodelle, Datenschutzverbesserungen und weitere Funktionen.
IBM Knowledge Catalog bietet außerdem folgende Funktionen:
- Die Möglichkeit, ein gemeinsames Geschäftsglossar als Grundlage für Data-Governance-Bemühungen zu erstellen.
- Eine Reihe von mehr als 30 Konnektoren zu IBM und externen Datenquellen.
- Nachverfolgung der Datenherkunft, der Datenqualitätsbewertungen und der Historie des Data-Governance-Workflows.
12. Informatica Enterprise Data Catalog
Informatica wurde 1993 gegründet, um sich auf Datenintegrations-Tools zu konzentrieren, und hat seitdem sein Produktportfolio erweitert, um eine breite Palette von Datenverwaltungstechnologien anzubieten, darunter auch dieses Datenkatalog-Tool. Mithilfe einer Engine, die auf Algorithmen des maschinellen Lernens basiert, kann Informatica Enterprise Data Catalog automatisch Daten aus Systemen innerhalb eines Unternehmens sowie aus Multi-Cloud-Plattformen, BI-Tools, ETL-Workflows und Metadatenkatalogen von Drittanbietern scannen, aufnehmen und klassifizieren.
Die Funktionen zur automatischen Datenkuratierung nutzen auch KI und maschinelles Lernen für die Erkennung von Bereichen, die Identifizierung von Ähnlichkeiten zwischen Datensätzen und die Zuordnung von Geschäftsbegriffen zu technischen Metadaten. Funktionen für die Datenabfolge verfolgen die Bewegung von Daten durch Systeme und Datenaufbereitungs- und -umwandlungspipelines und ermöglichen die Durchführung von Auswirkungsanalysen bei Änderungen an Datenbeständen. Vorgefertigte Berichte und Dashboards können auch zur Analyse der Datennutzung und -anreicherung sowie der Zusammenarbeit zwischen Benutzern verwendet werden.
Zu den weiteren Funktionen des Informatica Datenkatalog-Tools gehören:
- Funktionen zur Verfolgung der Datenqualität, um Datenprofilstatistiken und Datenqualitätsregeln, Scorecards und Metriken anzuzeigen.
- Eine Google-ähnliche semantische Suchfunktion zum Auffinden relevanter Datensätze in einem Katalog.
- Ein Wissensdiagramm, das Benutzern helfen soll, Beziehungen zwischen Datenbeständen zu erkennen.
13. Microsoft Purview Data Catalog
Dieses Tool ist Teil von Microsoft Purview, einem Cloud-Dienst für Data Governance, Compliance und Risikomanagement, der im April 2022 eingeführt wurde, als das Unternehmen eine Azure Purview-Produktlinie umbenannte und erweiterte. Offiziell ersetzt die Datenkatalogsoftware den Azure Data Catalog, eine ältere Technologie, die durch das Purview-Tool abgelöst wurde.
Microsoft Purview Data Catalog bietet ein Geschäftsglossar auf Unternehmensebene, das die Verwendung von Excel-basierten Datenwörterbüchern überflüssig macht. Benutzer können den Katalog nach Daten in vertrauten geschäftlichen und technischen Begriffen durchsuchen und interaktive Visualisierungen der Datenabfolge anzeigen. Das Datenkatalog-Tool läuft auf Microsoft Purview Data Map, einem begleitenden Metadaten-Management-Produkt, das Metadaten sammelt, sie in einer grafischen Struktur konfiguriert und die Datenklassifizierung und Kennzeichnung sensibler Daten übernimmt.
Zu den weiteren Funktionen von Microsoft Purview Data Catalog gehören:
- Funktionen zur Datenkuratierung, wie zum Beispiel Funktionen zur Verwaltung von Geschäftsglossaren und zur automatischen Kennzeichnung von Datenbeständen mit Glossarbegriffen.
- Ein Cloud-Dienst für die Registrierung von Datenquellen und die anschließende Speicherung und Indizierung ihrer Metadaten.
- Die Möglichkeit für Katalognutzer, die Metadaten durch das Hinzufügen von Beschreibungen, Tags und Anmerkungen anzureichern.
14. Oracle Cloud Infrastructure Data Catalog
Der Oracle Cloud Infrastructure Data Catalog, kurz OCI Data Catalog, wurde entwickelt, um das eigene Technologie-Ökosystem von Oracle zu ergänzen. Der Cloud-Service für das Metadatenmanagement erstellt ein Inventar von Datenbeständen und ein Geschäftsglossar für Benutzer. Er kann automatisch Metadaten aus Oracle-Datenspeichern und einer Reihe anderer gängiger Datenquellen sowohl in Cloud- als auch in On-Premises-Systemen abrufen, entweder nach Bedarf oder nach einem Zeitplan.
OCI Data Catalog verwendet auch Fuzzy-Matching-Algorithmen sowie KI- und maschinelle Lerntechniken, um Datenverwalter und andere Datenexperten bei der Kuratierung und Anreicherung von Metadaten zu unterstützen. Das Tool empfiehlt Verknüpfungen zwischen den Begriffen und Kategorien in einem Geschäftsglossar und den Datenentitäten und -attributen, um den Katalogbenutzern das Auffinden relevanter Daten zu erleichtern.
Die Oracle-Datenkatalogsoftware umfasst außerdem folgende Funktionen:
- Datenermittlungsfunktionen, mit denen Benutzer nach technischen Metadatennamen, Begriffen des Geschäftsglossars und Tags nach Daten suchen können.
- Integration mit dem Oracle Cloud Infrastructure Events Service zur Verteilung von Benachrichtigungen über den Status von Metadaten-Sammelprozessen.
- Die Möglichkeit, den Metastore des Datenkatalogs als zentrales Metadaten-Repository für Data Lakes im OCI Data Flow Service von Oracle zu nutzen, der Apache Spark-Workloads ausführt.
15. OvalEdge
OvalEdge wurde 2013 gegründet und bietet ein Datenkatalog-Tool mit konsolidierten Data-Governance-Funktionen. Das Unternehmen wirbt mit der Benutzerfreundlichkeit und Erschwinglichkeit seiner namensgebenden Software und behauptet, dass die Gesamtbetriebskosten im Vergleich zu anderen Datenkatalog-Tools im Durchschnitt 50 Prozent niedriger sind und 50 Prozent weniger Zeit für die Suche nach Daten in jeder Datenbank in einem Unternehmen benötigt wird. Das OvalEdge-Tool durchsucht verschiedene Datenbanken, Data-Lake-Plattformen, BI- und Analysesysteme sowie benutzerdefinierte Anwendungen, um Metadaten zu indizieren, und verwendet dann KI- und maschinelle Lernalgorithmen, um Daten auf der Grundlage von Tags, Nutzungsstatistiken und anderen Markern automatisch zu organisieren und zu katalogisieren.
Eine Datenprofilierungsfunktion erstellt automatisch statistische Zusammenfassungen von Datensätzen, und Datenbeziehungen können durch eingebettete Algorithmen oder manuelle Eingaben markiert werden. Die integrierten Data-Governance-Funktionen unterstützen gemeinsame Geschäftsglossar-Terminologie, Datenklassifizierung, Datenqualitätsregeln, Datenzugriffskontrollen und andere Maßnahmen. Im Jahr 2023 fügte OvalEdge verschiedene neue Funktionen hinzu, darunter KI-empfohlene Begriffe, verbesserte Datenqualitätsregeln, ein tiefgehendes Analysewerkzeug und mehr integrierte erweiterte Aufträge und Konfigurationen.
OvalEdge umfasst außerdem folgende Funktionen:
- Eine Reihe von Self-Service-Tools, die für verschiedene Benutzergruppen entwickelt wurden.
- Zusammenarbeit durch eine integrierte Chat-Funktion und die Möglichkeit, Links mit Details zu Daten über Slack oder E-Mail zu versenden.
- Warnmeldungen, um Endbenutzer über Datenänderungen zu informieren, wie zum Beispiel Änderungen der Metadaten oder eine Vergrößerung eines Datensatzes.
16. Pentaho Data Catalog
Dies ist die neueste Version des Datenkatalog-Tools von Hitachi Vantara, einer Hitachi-Tochtergesellschaft, die Software für Datenmanagement, Analyse, Speicherung und Infrastruktur entwickelt. Das Tool wurde ursprünglich von Waterline Data entwickelt, das die Vantara-Einheit im Jahr 2020 übernommen hat. Es wurde zunächst in Lumada Data Catalog umbenannt, bevor es Ende 2023 in Pentaho umbenannt wurde. Es enthält auch die Technologie von Io-Tahoe, einem anderen Anbieter von Datenkatalogen, den Hitachi Vantara im Jahr 2021 gekauft hat. Die Katalogsoftware erweitert die Funktionen zur Verwaltung von Metadaten, um Mainstream-Datenbanken, neue IoT-Dateninfrastrukturen und andere Datenquellen zu unterstützen.
Pentaho Data Catalog nutzt maschinelles Lernen und KI, um Datenkataloge automatisch zu füllen und Daten mit Tags zu versehen. Die KI-Technologie unterstützt auch die Self-Service-Datensuche durch eine metadatenbasierte Suchfunktion, die Dark Data identifiziert, die bei einer manuellen Kennzeichnung möglicherweise übersehen werden. Zur Unterstützung der Data Governance kann die Software auch automatisch sensible Daten identifizieren, kennzeichnen und sichern sowie Metadaten verfolgen, die für die Einhaltung gesetzlicher Vorschriften erforderlich sind.
Pentaho Data Catalog bietet außerdem folgende Funktionen:
- Ein Collaboration Hub, der es Teams ermöglicht, sich über Kommentare, Datenbewertungen und Unterhaltungen in Threads auszutauschen.
- Funktionen für die Datenabfolge, einschließlich der Möglichkeit, versteckte Verbindungen zwischen Datenbeständen zu finden.
- Eine damit verbundene Crowdsourcing-Funktion, die sicherstellt, dass Katalognutzer die besten Daten für ihre Bedürfnisse auswählen.
17. Qlik Catalog
Qlik wurde 1993 als BI- und Analyseanbieter gegründet. In den letzten Jahren hat das Unternehmen durch eine Reihe von Akquisitionen verschiedene Datenmanagement-Funktionen hinzugefügt, darunter 2018 die Übernahme von Podium Data, einem Start-up, das Datenaufbereitungs-, Datenqualitäts- und Datenkatalogfunktionen anbietet. Qlik hat die Datenmanagement-Technologien in Qlik Data Integration konsolidiert, einer Plattform, die Qlik Catalog und verschiedene andere Tools umfasst, die eine zuverlässige Datenbereitstellung für Analysezwecke unterstützen.
Qlik Catalog bietet ein Repository für den Zugriff auf Daten aus dem gesamten Unternehmen und intelligente Datenkatalogisierungsfunktionen, die Anwendern helfen, Daten zu finden und in BI- und Analyse-Workflows zu integrieren. Darüber hinaus enthält die Software Data-Governance-Funktionen, die Unternehmen bei der Einhaltung von Datenschutzgesetzen und internen Nutzungsrichtlinien unterstützen, wenn sie Self-Service-BI-Modelle für Fachanwender einführen. Darüber hinaus kann die Software Teams bei der Bewertung des Nutzens verschiedener Datenquellen für neue Analyseanwendungen unterstützen.
Die folgenden Funktionen sind ebenfalls in Qlik Catalog integriert:
- Eine browserbasiertes GUI, die den Zugriff auf die Funktionen des Tools sowie auf das Metadaten-Repository und die Services erleichtert.
- Metadatenmanagement für Rohdaten und nachfolgende Datentransformationen mit der Möglichkeit, die Metadaten mit anderen Datenkatalogen und Anwendungen auszutauschen.
- Die Fähigkeit, Geschäftsregeln zu erstellen und anzuwenden, während Daten aufgenommen werden – zum Beispiel, um automatisch personenbezogene Daten zu schützen, doppelte Daten zu finden oder Änderungen der Datenqualität zu erkennen.
18. Tableau Catalog
Tableau leistete nach seiner Gründung im Jahr 2003 Pionierarbeit auf dem Gebiet der Self-Service-BI und der interaktiven Datenanalyse. Wie Qlik expandierte es in den Bereich der Datenmanagement-Technologien, bevor es 2019 von Salesforce übernommen wurde. Tableau Catalog ist Teil von Tableau Data Management, einem Zusatzmodul für die Analyseplattform von Tableau. Das Katalog-Tool wurde entwickelt, um das Vertrauen in Daten zu stärken und die Datenerkennung in Unternehmen mit Tableau-Installationen zu verbessern.
Tableau Catalog nimmt automatisch Informationen über Tableau-Datensätze in ein zentralisiertes Repository auf. Das Tool enthält außerdem Funktionen zur Datenabfolge und Auswirkungsanalyse, die Tableau-Teams dabei unterstützen, Datenbeziehungen besser zu verstehen und zu erkennen, wie sich Änderungen an Datensätzen oder Pipelines auf Analyseprozesse auswirken. Darüber hinaus werden Funktionen wie Datenqualitätswarnungen und kontextbezogene Metadaten unterstützt, um Geschäftsanwendern die Informationen an die Hand zu geben, die sie zur Validierung von Datensätzen für Analysezwecke benötigen.
Zu den weiteren Funktionen von Tableau Catalog gehören:
- Eine Reihe von APIs zum Einlesen von Metadaten aus anderen Anwendungen für die Analyse in Tableau.
- Integration mit Unternehmensdatenkatalogen über Tableau APIs oder vorgefertigte Verbindungen von anderen Kataloganbietern.
- Die Möglichkeit, Endbenutzer direkt in den Analyseergebnissen zu warnen, wenn sich die Datenqualität ändert.
Open-Source-Software für Datenkataloge
Unternehmen können auch verschiedene Open-Source-Datenkatalog-Tools in Betracht ziehen. Viele von ihnen wurden von Unternehmen entwickelt, die eine effizientere und effektivere Technologie entwickeln wollten, um ihre eigenen Herausforderungen bei der Datenkatalogisierung zu bewältigen. Einige der besten Open-Source-Optionen sind die folgenden Tools:
- Amundsen. Diese Datenerkennungs- und Metadaten-Engine wurde von Lyft entwickelt, um die Produktivität von Datenwissenschaftlern und anderen Nutzern seiner komplexen Dateninfrastruktur zu steigern. Das Ride-Sharing-Unternehmen hat das Tool 2019 als Open-Source-Technologie veröffentlicht.
- Apache Atlas. Die Atlas-Software umfasst Datenkatalog-, Metadatenmanagement- und Data-Governance-Funktionen. Sie wurde vom ehemaligen Big-Data-Plattformanbieter Hortonworks zunächst für den Einsatz in Hadoop-Clustern entwickelt und 2015 an die Apache Software Foundation übergeben.
- DataHub. Das Datenteam von LinkedIn hat dieses Metadatensuch- und -entdeckungs-Tool entwickelt, um interne Nutzer dabei zu unterstützem, den Kontext von Daten zu verstehen, indem es ein früheres Tool namens WhereHows umgestaltet und erweitert hat. DataHub wurde 2020 als Open Source veröffentlicht.
- Metacat. Dieses föderierte Metadaten-Ermittlungs- und Explorations-Tool wurde von Netflix entwickelt, um die Datenermittlung, Datenaufbereitung und Data Science Workflows in seiner Big-Data-Umgebung zu vereinfachen. Die Technologie wurde 2018 als Open Source veröffentlicht.
- OpenMetadata. OpenMetadata, eine 2021 gegründete Open-Source-Plattform, ist eine End-to-End-Plattform für die Verwaltung von Metadaten, die Tools für Datenerkennung, Governance, Qualität, Beobachtbarkeit und Zusammenarbeit bietet. Sie hat ihre Version 1.0 im Mai 2023 veröffentlicht.
- OpenDataDiscovery. Die 2021 gegründete Plattform für Datenermittlung und Observability OpenDataDiscovery bietet integrierte Datenqualitätssicherung, Ingestion-to-Product-Lineage, Smart Alerts, einen föderierten Datenkatalog und Funktionen für die Zusammenarbeit.






