
Petrovich12 - stock.adobe.com
Wie Interconnects die Storage-Leistung beeinflussen
Sollte InfiniBand oder RoCE als Speicherverbindung zum Einsatz kommen? Wir erklären die Auswirkungen jeder Technologie auf Leistungsmerkmale wie Latenz, IOPS und Durchsatz.

Die gemeinsame Nutzung von Speicher ist seit mehr als zwei Jahrzehnten ein wichtiger Aspekt der Speicherkostenkontrolle und Leistungsoptimierung. Das Ziel war es, die beste Leistung zu den niedrigsten Kosten aus dem gemeinsam genutzten Speicher (Shared Storage) herauszuholen.
Es gibt im Wesentlichen vier Arten von gemeinsam genutztem Speicher (Block-, Datei-, Objekt- und Paralleldatei-Storage), die in HPC-Umgebungen (High Performance Computing) häufig anzutreffen sind. Während jeder Ansatz mehrere Speicherengpässe lösen muss, um seine optimale Leistung zu erreichen, konzentriert sich dieser Artikel auf Probleme im Zusammenhang mit der externen Verbindungsleistung zu Client-Endpunkten.
Die Rolle von High Performance Interconnects beim Speicher
Der Markt ist derzeit vom Hype der NVMe-oF als Schlüssel zu Fragen der Hochleistungsverbindungen erfasst. NVMe-oF ist das NVMe-Blockprotokoll, das die Vorteile des RDMA (Remote Direct Memory Access) in den verschiedenen Interconnect-Technologien nutzt.
Der Hauptzweck von NVMe-oF besteht darin, Anwendungen mit einem Speichersystem so zu verbinden, als handele es sich um einen lokalen NVMe-Flash- oder einen persistenten Storage-Drive. RDMA reduziert die Latenz, indem sichergestellt wird, dass das empfangende Ziel über genügend freien Arbeitsspeicher für die zu übertragenden Daten verfügt. Die Latenzzeit am Frontend ist wichtig für Transaktionen.
Ein Beispiel für ein System, das die Vorteile von RDMA zwischen den Anwendungsservern und dem Zielspeicher nutzt, findet sich in der von Oracle entwickelten hyperschnellen Exadata-Datenbankanwendung. Es verwendet RDMA zwischen den Datenbankservern und den Speicherservern innerhalb der schlüsselfertigen Appliance. Ein weiteres Beispiel ist Excelero, das zwischen den Anwendungsservern und dem Zielspeicher läuft. In diesem Fall umgeht Excelero die Speicher-CPU und geht direkt zu den Laufwerken innerhalb des Speichersystems. Jedes dieser Beispiele zeigt den Wert der Verwendung von RDMA, aber nicht unbedingt von NVMe-oF. Pavilion Data verwendet NVMe-oF zwischen Anwendungsservern und seinem Speichersystem. Jeder dieser Ansätze bietet außergewöhnlich niedrige Latenzen. NVMe-oF unterstützt Ethernet, Fibre Channel (FC), InfiniBand und TCP/IP. Derzeit sind die niedrigsten Latenzen auf InfiniBand, Ethernet und FC. TCP/IP fügt einige Latenzzeiten hinzu.

Offensichtlich hat eine Ethernet-NIC (Network Interface Card) mit 100 GBit/s oder 200 GBit/s eine bessere Leistung als eine NIC mit 10 GBit/s. Sowohl InfiniBand als auch Ethernet können einen Durchsatz von bis zu 600 GBit/s (auf 12 Links) erreichen, und sie haben zukünftige Spezifikationen, die den fünffachen Durchsatz versprechen. Es ist jedoch wichtig zu verstehen, dass eine 200-GBit/s-NIC einen PCIe-Gen-4-Bus auslasten wird. Daher werden mehrere 200-GBit/s-NICs oder NIC-Ports die Leistung nicht verdoppeln, ebenso wenig wie eine 400-GBit/s-NIC.
Fibre Channel – der mit 32 GBit/s seinen Höchststand erreicht und in Zukunft 128 GBit/s erreichen wird – ist im Bereich der Bandbreiten-Hochleistungsspiele ins Hintertreffen geraten. Es gibt nur wenige neue FC-Kunden, aber die installierte Unternehmensbasis wird voraussichtlich noch einige Jahre lang wachsen. Nichtsdestotrotz wurde sie zu einer veralteten Interconnect-Verbindung degradiert.
Was eignet sich als Hochleistungsverbindung: InfiniBand oder RoCE?
In Zukunft konzentrieren sich die meisten Implementierungen von Hochleistungs-Interconnects auf InfiniBand oder RDMA over Converged Ethernet (RoCE). Wie verhalten sich also die beiden Protokolle im Vergleich?
Architektur
Die InfiniBand-Architektur spezifiziert, wie RDMA in einem InfiniBand-Netzwerk funktioniert, während RoCE dasselbe für Ethernet macht. InfiniBand RDMA befindet sich im Adapter-Chip. RoCE kann sich je nach Hersteller im Adapter- oder NIC-Chip befinden. Es gibt zwei offizielle RoCE-Versionen: RoCE v1 und RoCE v2. RoCE v1 verkapselt InfiniBand Transportpakete über Ethernet mit Ethernet-Frame-Beschränkungen von 1.500 Bytes oder 9.000 Bytes für Jumbo-Frames. RoCE v2 basiert auf dem Benutzer-Datagramm-Protokoll (UDP).
RoCE verwendete ursprünglich InfiniBand Verbs – Funktionen und Methoden, die von einem InfiniBand-API angeboten werden. Die neuesten Implementierungen nutzen auch die Vorteile von Libfabric, die von Amazon Web Services, Cisco Systems, Juniper Networks und Microsoft Azure verwendet wird.
Bandbreite
Sowohl InfiniBand als auch Ethernet unterstützen eine Bandbreite von bis zu 400 GBit/s. InfiniBand ist ein offener Standard, wird aber derzeit nur von Mellanox angeboten, die Nvidia vor kurzem übernommen hat. Ethernet, ein offener Standard des Ethernet Technology Consortium und wird von vielen Anbietern unterstützt, darunter Arista Networks, Atto Technology, Broadcom, Chelsio Communications, Cisco Systems, Dell Technologies, Hewlett Packard Enterprise (HPE), Huawei, Intel, Juniper Networks, Cavium der Marvell Technology Group, Mellanox Technologies und Siemens.
Mellanox ist ein Hauptakteur sowohl bei InfiniBand- als auch bei Ethernet-Hochleistungsverbindungen, nachdem das Unternehmen vor einigen Jahren erkannt hatte, dass es nicht auf eine potenzielle Nische beschränkt bleiben will.
Ethernet war schon immer ein Akteur in der Hochleistungsverbindungstechnologie, aber InfiniBand hat aufgrund seiner geringeren Latenzen und Kosten besser abgeschnitten. Ethernet hat jedoch begonnen, diese Vorteile zu untergraben. Es gibt nur wenige Speichersysteme mit einer externen InfiniBand-Schnittstelle – DataDirect Networks, HPE/Cray, IBM, Panasas, Pavilion Data Systems und WekaIO – und noch weniger, die InfiniBand als interne Verbindung verwenden.
Latenz
InfiniBand hat bei den Latenzen in der Vergangenheit gegenüber Ethernet den Vorteil gehabt, dass sowohl bei Adaptern als auch beim Switching Latenzzeiten auftreten. Der Grund dafür ist, dass viele Aspekte der InfiniBand-Vernetzung im InfiniBand-Chip ausgelagert wurden und nicht im Ethernet-Chip. Tatsächlich wird das Offloading in den InfiniBand-Spezifikationen genannt.
Ethernet-Anbieter haben diese Lücke in den letzten Jahren geschlossen, insbesondere in NICs, wo die meisten Latenzen auftreten. Anbieter wie Chelsio und in geringerem Maße auch Mellanox haben viel getan, um die Latenzlücke zu verringern.
InfiniBand hatte eine weitaus bessere, geringere Latenz als Ethernet-Switches. Diese Lücke hat sich jedoch bei Ethernet deutlich verringert, da die neuesten Hochleistungs-Switches von Anbietern wie Cisco und Juniper Networks diesen Vorteil um den Faktor fünf auf das Zweifache reduziert haben.
Basierend auf Bandbreite und Latenz scheint InfiniBand einen Vorteil gegenüber RoCE zu haben. Es gibt jedoch noch andere Faktoren, beispielsweise Überlastung und Routing, die sich auf Hochleistungsverbindungen auswirken.
Überlastungen
Überlastungen treten sowohl in Layer-2-Fabrics als auch in Layer-3-Verbindungsnetzen auf. In Layer-2-Fabrics – wie FC, InfiniBand und RoCE – wird die Überlastung als „Hot Spot“ bezeichnet, der dann auftritt, wenn über eine bestimmte Route oder einen bestimmten Port zu viel Verkehr herrscht. Ein Hot Spot kann die Leistung negativ beeinflussen, indem er den Verkehr blockiert oder verlangsamt. Bei einer Überlastung sind die Layer-2-Fabrics so konzipiert, dass sie keine Pakete verwerfen, während Layer-3-Netzwerke Pakete verwerfen.
InfiniBand kontrolliert Überlastungen mit Hilfe von zwei verschiedenen Frame-Relay-Nachrichten: Forward Explicit Congestion Notification (FECN) und Backward Explicit Congestion Notification (BECN). FECN benachrichtigt das empfangende Gerät, wenn eine Netzwerküberlastung vorliegt, während BECN das sendende Gerät benachrichtigt. InfiniBand kombiniert FECN und BECN mit einer adaptiven Markierungsrate, um Überlastungen zu reduzieren. Es bietet eine gewisse Kontrolle, da es alle von der Überlastung betroffenen Personen benachteiligt, nicht nur das betroffene System.
Die Überlastungskontrolle auf dem RoCE verwendet die Explicit Congestion Notification (ECN), eine Erweiterung von IP und TCP, die eine Benachrichtigung im Endpunktnetzwerk ermöglicht, ohne Pakete fallen zu lassen. ECN versieht den IP-Header mit einer Markierung, um den Sender über eine Überlastung zu informieren – als ob Pakete verworfen worden wären – anstatt die Pakete zu verwerfen.
Bei Nicht-ECN-Überlastungs-Kommunikation erfordern verworfene Pakete eine erneute Übertragung. ECN reduziert Paketverluste durch eine überlastete TCP-Verbindung und vermeidet so eine erneute Übertragung. Weniger erneute Übertragungen reduzieren Latenz und Jitter und sorgen so für eine bessere Transaktions- und Durchsatzleistung. ECN bietet jedoch auch eine generelle Überlastungskontrolle ohne offensichtliche Vorteile gegenüber InfiniBand.
Routing
Wenn Überlastungen oder Hot Spots in der Struktur oder im Netzwerk auftreten, teilt das adaptive Routing den Geräten alternative Routen zu, um Engpässe zu beseitigen und die Bereitstellung zu beschleunigen. Die neuesten Mellanox InfiniBand-Switches verwenden die adaptive Routing-Benachrichtigung und eine Technik, die Mellanox als selbstheilende Verbindungsverbesserung für intelligente Rechenzentren (Self-Healing Interconnect Enhancement for Intelligent Data Centers, kurz Shield) oder schnelle Fehlerbehebung bei Verbindungsfehlern (Fast Link Fault Recovery) bezeichnet.
Das adaptive InfiniBand-Routing ermöglicht dem InfiniBand-Switch die Auswahl eines Ausgangsports basierend auf der Auslastung des Ports, vorausgesetzt, es gibt keine Einschränkungen bei der Auswahl des Ausgangsports. Shield ermöglicht es dem Switch, einen alternativen Ausgangsport auszuwählen, falls der Ausgangsport in der linearen Weiterleitungstabelle nicht in einem aktiven Zustand ist und ausfällt.
RoCE v2 läuft zusätzlich zu IP. IP war jahrzehntelang mit fortschrittlichen Routing-Algorithmen Routing-fähig, und jetzt mit KI und Machine Learning lassen sich überlastete Routen vorhersagen und Pakete automatisch über schnellere Routen senden. Wenn es um Routing geht, haben Ethernet und RoCE v2 erhebliche Vorteile.
Allerdings tun weder InfiniBand noch RoCE viel für die Tail-Latenz, das ist die Latenz des letzten statt des ersten Pakets (Tail, zu deutsch Schwanz). Die Tail-Latenz ist für HPC-Messaging-Anwendungen zur Synchronisierung sehr wichtig, und einige Produktinnovationen beginnen, sich damit zu befassen.
Die Zukunft der High-Performance-InterconnectTechnologie
Es gibt mehrere Anbieter – HPE Cray, Fungible und ein Stealth-Start-up, das derzeit noch nicht genannt werden kann –, die an Hochleistungs-Verbindungsinnovationen der nächsten Generation arbeiten. Lassen Sie uns einige der Arbeiten untersuchen, die sie zur Verbesserung von Ethernet und RoCE durchführen.
HPE Cray
Ein Teil der Übernahme von Cray durch HPE im Jahr 2019 enthielt einen Hochleistungs-Interconnect, der auf Standard-Ethernet basiert und Slingshot genannt wird. HPE Cray entwickelte Slingshot, um eine bessere Leistung für seinen Shasta HPC-Supercomputer und den ClusterStor E1000, seinen auf Lustre basierenden Speicher, und die Verbindung zu Shasta bereitzustellen.
Slingshot verwendet standardisiertes RDMA über Ethernet und fügt ein Superset hinzu, das von HPE Cray als HPC-Ethernet bezeichnet wird. Dieses Superset ist für die Anforderungen des HPC-Verkehrs konzipiert und für die in HPC-Anwendungen verbreiteten Nachrichtenübermittlung in kleinen Paketen und das Nachrichtenschnittstellenprotokoll optimiert.
HPC-Ethernet läuft zusätzlich zu UDP/IP und gleichzeitig mit dem gesamten anderen Ethernet-Verkehr. HPE Cray bietet Switches, die auf einem einzigartigen Application-Specific Integrated Circuit (ASIC) basieren, der über hoch entwickeltes adaptives Routing und eine Überlastungskontrolle verfügt. Diese Kombination ermöglicht Hochleistungsnetzwerke, die auf mehr als 270.000 Endpunkte skaliert werden können, mit nicht mehr als drei Hops dazwischen. Slingshot unterstützt alle Switch-Netzwerktopologien, einschließlich Dragonfly.
Das Wichtigste bei Slingshot ist die außergewöhnliche Latenzleistung und insbesondere die Tail-Latenz unter Last. Dies wurde durch die Ergebnisse von Slingshot bei den standardisierten Global Performance and Congestion Network Tests (GPCNeT) bestätigt.
Slingshot zeigte keinen Unterschied in der durchschnittlichen unbelasteten Latenz und der durchschnittlichen Latenz, wobei die Überlastung (Congestion) bei etwa 1,8 Mikrosekunden (µs) lag. Beeindruckender war die Congestion bei der Tail-Latenz, wobei 99 Prozent der Pakete unter 8,7 µs lagen. Standard-RoCE und InfiniBand im gleichen GPCNeT-Test haben in der Regel durchschnittlich eine 10- bis 20-mal höhere Tail-Latenz, und die Latenz ist inkonsistenter.
Die Slingshot-Überlastungskontrolle und das adaptive Routing sind Switch-basiert. Dadurch kann Slingshot potenziell mit einer Vielzahl von Ethernet-NICs mit 100/200 GBit/s arbeiten. Aktuelle Implementierungen verwenden Nvidia Mellanox ConnectX-5 NICs. Das adaptive Routing ist granular und benachteiligt nur die Parteien, die die Überlastung verursachen, wobei keine Pakete verworfen werden. Leider ist Slingshot ab 2020 nur noch als Teil des HPE Cray Shasta HPC-Supercomputers und ClusterStor-Speichers erhältlich und verkauft. In ClusterStor nur dann, wenn der Speicher mit oder für einen Shasta-Supercomputer verkauft wird.
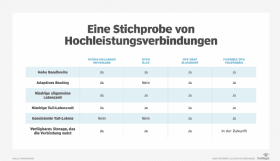
Fungibel
Fungibel ist ein gut finanziertes Start-up-Unternehmen mit mehr als 200 Mitarbeitern. Die Mitbegründer sind Pradeep Sindhu, ehemaliger Gründer von Juniper Networks, und Bertrand Serlet, ehemaliger Gründer von Upthere (von Western Digital übernommen) und zuvor Senior Vice President of Software Engineering bei Apple.
Fungible hat einen ASIC entwickelt, der so konzipiert ist, dass er CPU-Probleme mit datenintensiver Verarbeitung löst, wie sie in Hochleistungsnetzwerken und Speichern auftritt. Der Prozessor wird als Datenverarbeitungseinheit (DPU) bezeichnet.
Es handelt sich dabei nicht um eine Netzwerkauslagerung wie bei den NICs von Nvidia Mellanox und Chelsio, sondern soll die Verarbeitung und Bewegung von IP-Datenpaketen bei extrem hohen Geschwindigkeiten erleichtern und beschleunigen. DPU verfügt über eine endpunktbasierte Überlastungskontrolle und adaptives Routing, das mit jedem Standard-Ethernet-Hochleistungs-Switch funktioniert.
Wie Slingshot minimiert es fortlaufend Hops und Latenzzeiten. Im Gegensatz zu Slingshot müssen die ASICs auf den Initiator- und Ziel-NICs integriert sein. Fungible hat eine ASIC für Initiatoren und eine weitere mit mehr Durchsatz für Speicher entwickelt. Die Skalierbarkeit des Netzwerks wird auf Hunderttausende von Endpunkten prognostiziert.
Fungible hat auch eine Software, TrueFabric, entwickelt, die auf UDP/IP läuft und zu den DPUs passt. Fungible behauptet, dass die DPU und ihre TrueFabric-Software so konzipiert sind, dass sie Ressourcen in großem Maßstab zusammenfassen und die für eine extreme Speicherleistung erforderlichen Ressourcen, einschließlich der Anzahl der Switches und Speicherressourcen, reduzieren.
Das Unternehmen verspricht außerdem, dass die ASIC und die Software die Latenzzeit und die Tail-Latenzzeit zwischen den Knoten sowie zwischen den Knoten und dem Speicher reduzieren und gleichzeitig konsistente vorhersagbare Latenzen sowie eine erhöhte Zuverlässigkeit und Sicherheit bieten. Diese Aussagen basieren auf prädiktiven Algorithmen. Dennoch ein Wort der Vorsicht. Solange es keine Fungible DPU-Produkte mit wiederholbaren Benchmark-Tests gibt, sind diese Angaben faszinierend, aber nicht verifiziert.
Ein unbekanntes Start-up im Stealth-Modus
Es gibt noch eine weitere neue Firma auf dem Markt für Hochleistungs-Verbindungsleitungen, aber sie befindet sich derzeit im Stealth-Modus und ist nicht in der Lage, ihre Pläne öffentlich zu diskutieren. Das Unternehmen entwickelt einen Ansatz für Hochleistungs-Interconnects mit einer vollständig Switchless-Architektur, die sich auch auf Zehntausende bis Hunderttausende von Endpunkten skalieren lässt, mit Congestion Control und adaptivem Routing.
Was dies hochinteressant macht, ist die vollständige Eliminierung von Switches. Sie wird voraussichtlich in der ersten Hälfte des Jahres 2021 verfügbar sein.
Erfahren Sie mehr über Storage Performance
-
![]()
NVMe over TCP: Optionen, Vorteile und Herausforderungen
Von: Robert Sheldon
-
![]()
HPE bringt KI-Racks auf Basis von AMD Helios ab 2026
Von: Michael Eckert
-
![]()
Leistung optimieren: Vier Tipps für virtualisierten Speicher
Von: Ulrike Rieß-Marchive
-
![]()
Cisco Silicon One P200: Chip-Basis für KI-Rechenzentren
Von: Beth Pariseau



