Als sich die NVM Express Group entschloss, die Verbreitung von Non-Volative Memory Express über ein Netzwerk auszudehnen, entschied man sich klugerweise nicht für ein noch nicht fertig entwickeltes Protokoll wie zum Beispiel Omni-Path von Intel oder dem Weg von Fibre Channel zu folgen und ein komplett neues Netzwerk zu erfinden. Stattdessen hat man NVMe over Fabric in Module aufgeteilt. Dies ermöglichte es den Herstellern, Treiber zu entwickeln, mit denen das NVMe-oF-Modell über jedes gewünschte Transportprotokoll laufen kann. Außerdem schoben sie ihre Produkte durch diverse Standardisierungsprozesse hindurch.
Die Spezifikation von NVMe-oF 1.0 umfasst die Unterstützung von zwei Transportarten: Fibre Channel (FC) und Remote Direct Memory Access (RDMA). Beide können Daten vom Host zum Array und umgekehrt übertragen, ohne dass die Daten mehrfach zwischen den Memory Buffers und den I/O-Karten kopiert werden, wie dies bei den TCP/IP-Stacks üblich ist. Dieser „zero-copy“-Prozess – oder fast „zero-copy“ für FC – sollte die CPU-Last und die Latenzen beim Datentransport reduzieren. Dies bedeutet, dass jede NVMe Fabric, die man auswählt, die Speicher-Performance beschleunigen soll.
Betrachten wir nun die Optionen für NVMe Fabric etwas genauer. Zu RDMA gehören InfiniBand, RDMA over Converged Ethernet, RoCE v2 (routable RoCE) und Internet Wide Area RDMA Protocol (iWARP).
NVMe over FC
Um eine gleichmäßig niedrige Latenz zu erhalten, die NVMe-oF-Anwender von einem Netzwerk erwarten, müssen effiziente Mechanismen gegen eine Überlastung vorhanden sein. NVMe over FC stützt sich hier auf das bewährte Zwischenspeicher-Kontrollsystem von FC. Weil die Daten nicht verschickt werden, bevor der Absender vom Empfänger eine Zwischenspeicher-Zuweisung erhalten hat, stellt FC einen zuverlässigen und verlustfreien Transport zur Verfügung. Die Host Bus Adapter (HBAs) von FC haben schon immer das FC Protocol (FCP) benutzt, um Latenzen zu verringern und die CPU-Auslastung zu unterstützen.
Alle FC-Hersteller stehen hinter NVMe over FC, indem sie den Netzanteil des Datentransports vereinfachen. Und alle FC HBAs oder Switches mit 16 oder 32 Gbps unterstützen NVMe over FC, während sie weiterhin traditionelle Dienste für SCSI over FCP liefern.
Wenn man mit seiner bestehenden FC-Infrastruktur zufrieden ist, sollte auch der Einsatz von NVMe over FC gut funktionieren. Anders gesagt: Wenn das Storage-Team im Unternehmen keinen Zugang zu Ethernet bekommen hat, weil das Netzwerkteam nicht die Kontrolle über die Ethernet-Switches aus der Hand gibt, dann sollte man sich an FC für seine Netzwerkoption halten.
Die RDMA-Gruppe
Network Interface Cards (NICs), die Computer mit Netzwerken verbinden, ermöglichen einen direkten Memory-Zugang, um Daten unmittelbar im Host-Memory zu speichern – ohne sie in einen Puffer im NIC zu kopieren und dann weiterzuleiten. RDMA erweitert diese Fähigkeit auf Lese- und Schreibzugriffe auf Memory Locations in einem entfernten System. Diese Funktion erlaubt andere NVMe-Netzoptionen als mit FC.
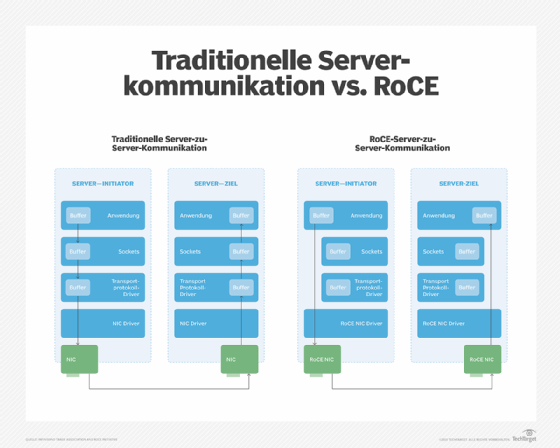
Abbildung 1: Traditionelle Serverkommunikation vs. RoCE
InfiniBand
RDMA tauchte zuerst in der Welt von High-Performance Computing auf und lief auf InfiniBand-Netzwerken, die das Rückgrat von eng miteinander verbundenen Compute-Clustern bilden. InfiniBand liefert RDMA-Funktionen wie zum Beispiel Natively Write Remote und benutzt ein FC-ähnliches Zuweisungssystem für Zwischenspeicher, um vorhersagbare Latenzen mit bescheidener Belastung sicherzustellen.
Trotz seiner großen Bandbreite und geringen Latenzen konnte sich InfiniBand kaum über die Grenzen von High-Performance Computing hinweg durchsetzen. Die einzigen Anwendungsfälle, in denen es eine gewisse Bedeutung gewann, waren dedizierte Backend-Netzwerke für Scale-out Speichersysteme wie zum Beispiel XtremIO und Isilon von Dell EMC.
NVMe over RDMA over Ethernet
Bob Metcalfe, einer der Erfinder des Internets, sagte einmal: „Ich weiß nicht, wie das Netzwerk der Zukunft aussehen wird, aber ich bin sicher, man wird es Ethernet nennen.“ Mit der Zeit hat sich das Ethernet sicher in immer mehr Speichersystemen etabliert. Und als die Performance des Ethernet zugenommen hatte, nahm die Idee von RDMA over Ethernet Gestalt an, selbst in der Welt des High-Performance Computing, in der InfiniBand die Herrschaft innehatte.
Um RDMA over Ethernet zu unterstützen, wurde eine neue Klasse von NICs geschaffen. Diese für RDMA geeigneten NICs – RNICs genannt – akzeptieren die RDMA-Funktionen, übertragen die in ein RDMA-over-Ethernet-Protokoll eingeschlossenen Daten über das Netzwerk und sorgen für das Lesen oder Schreiben der Daten zum und vom Memory des entfernten Systems. Genauso wie FC HBAs lagern sie das Protocol Handling von RDMA aus.
Das Problem besteht wie so oft darin, dass wir es nicht mit einem, sondern mit zwei Standardprotokollen für RDMA over Ethernet zu tun haben. Es gibt RoCE (Rocky ausgesprochen) und es gibt iWARP.
Während Storage over RDMA sich gut eignet für Anwendungen mit geringen Latenzen, haben frühere Versuche wie zum Beispiel iSER (iSCSI Extensions for RDMA) nicht genug Performance geliefert, so dass sich die notwendigen Netzwerkanpassungen nicht gelohnt hätten.
RoCE
Die ursprüngliche RoCE-Spezifikation der InfiniBand Trade Association versetzte die InfiniBand-ähnlichen RDMA-Versandfunktionen im Wesentlichen direkt in das Ethernet. Converged Ethernet in RoCE ist ein Netzwerk mit Data Center Bridging (DCB), das auf einem Satz von Kontrollfunktionen gegen Überlastung besteht, die zuerst entwickelt worden waren, um Ethernet verlustfrei zu machen. Daraus entstand dann FC over Ethernet.
Es gibt unterschiedliche Meinungen darüber, wie wirksam Ethernet mit DCB eigentlich ist. Jeder Ethernet-Switch in einem Rechenzentrum, der mit 10 Gbps oder schneller funktioniert, unterstützt DCB – also jeder Ethernet-Switch, den man für NVMe over RoCE benutzt. Den Converged-Ethernet-Teil von RoCE erhält man auf diese Weise leicht, auch wenn die Konfiguration etwas dauert.
Die neuere Version RoCE v2 verpackt die RDMA-Daten in Stücke von User Datagram Protocol. Das bedeutet, dass der Datenverkehr von RoCE v2 genauso wie der iWARP-Verkehr geroutet werden kann. RoCE v2 verlangt nicht einmal ein verlustloses Netzwerk.
Mellanox führt die RoCE-Bewegung an. Andere Hersteller verkaufen ebenfalls RNICs. Broadcom (sowohl mit den früheren Converged Network Adaptern von Emulex als auch mit den NIC- und LAN-on-Motherboards von Broadcom) und Cavium (vor kurzem von Marvell Technology gekauft) mit seinen FastLinQ-Karten (QLogic) unterstützen RoCE. Für Linux ist ebenfalls ein Soft-RoCE-Treiber verfügbar. Attala Systems, Hersteller von NVMe-oF-Chips, hat mit Mellanox RNIC eine Gesamtlatenz von etwa 100 Mikrosekunden demonstriert, und mit Soft-RoCE von 125 Mikrosekunden. Eingesetzt wurden dabei jeweils NVMe-SSDs, die von Attalas field-programmable Gate Array gesteuert werden.
Während NVMe over RoCE v2 nicht DCB erfordert, wird aber genau das in der öffentlichen Wahrnehmung so gesehen. Wir gehen davon aus, dass RoCE in den Umgebungen mit den höchsten Performance-Anforderungen das NVMe-Netz der Wahl sein wird.
iWARP
iWARP akzeptiert RDMA-Funktionen und überträgt sie über das Ethernet abgeschlossen in TCP-Paketen. Während TCP für den zuverlässigen Transport sorgt, ist iWARP fast ausschließlich in RNICs implementiert.
Weil iWARP TCP für die Lastkontrolle und zuverlässigen Transport nutzt, kann es auf jedem beliebigen IP-Transportweg laufen, einschließlich routed Netzwerken. Das macht es besser für große Implementierungen in Rechenzentren geeignet als RoCE, das Netzwerkunterstützung erfordert.
Abbildung 2: Optionen an Netzwerkkomponenten für NVMe-oF
Microsoft, Intel und RNIC-Hersteller Chelsio Communications führen das iWARP-Lager an. Intel bietet nur iWARP-Support in der X722 LAN-on-Motherboard-Komponente der Intel C620 Chipset-Serien (Purley) an. iWARP-Anwendern bleiben so Marvells FastLinQ NICs, die sowohl RoCE und iWARP unterstützen, als auch Chelsio für RNICs.
NVMe over TCP
Die letzte Alternative für ein NVMe-Netzwerk ist das gute alte TCP. TCP managt die Auslastung und schickt fast alles über das Ethernet und alles zum Internet. NVMe over TCP, zuerst angeboten von Solarflare und Lightbits Labs, gehört zu der Spezifikation von NVMe-oF 1.1, deren Verabschiedung bis Ende 2018 erwartet wurde.
Man hat NVMe over Fabric in Module aufgeteilt. Dies ermöglichte es den Herstellern, Treiber zu entwickeln, mit denen das NVMe-oF-Modell über jedes gewünschte Transportprotokoll laufen kann.
Weil es über Standard-TCP läuft, benutzt NVMe over TCP standardmäßige Ethernet-Leitungen und erfordert keine besonderen RNICs oder HBAs. Zusätzliche Datenkopien bedeuten in typischen TCP-Stacks, dass NVMe over TCP auf Standard-Hardware höhere Latenzen als NVMe over RoCE oder iWARP haben wird.
Wieviel Latenzen genau TCP über ein RDMA-Netzwerk hinzufügen wird, hängt davon ab, wie man NVMe over TCP implementiert. Der Array-Hersteller Pavilion Data hat Kunden, die NVMe over RoCE und NVMe over TCP auf dem gleichen Array laufen lassen. Sie berichten von einer Latenz von 100 Mikrosekunden für RoCE und 180 Mikrosekunden für TCP. Andere Kunden sprechen von 10 bis 20 Mikrosekunden an zusätzlicher Latenz.
Weil TCP den Systemprozessor zur Protokollverwaltung und zur Berechnung der Prüfsummen benutzt, wird NVMe over TCP auch die Prozessorauslastung etwas erhöhen. Viele Hersteller von NVMe-oF-Chips bauen auch TCP ein. Solarflare baut NVMe-TCP-Mechanismen in seine neuesten NICs ein.
Einige Analysten sehen in NVMe lediglich eine Lösung für jene Applikationen und Anwender, die maximale Performance benötigen. Sie zweifeln den Wert eines NVMe-Netzwerks an, das nicht für besonders niedrige Latenzen sorgt. Ich denke, dass das eine oberflächliche Sichtweise ist. NVMe over TCP füllt die Rolle aus, die iSCSI im letzten Jahrzehnt bei billigen und leicht zu verwaltenden Netzwerkaufgaben zugefallen war. Da es komplett routingfähig ist, unterstützt NVMe over TCP auch große skalierbare Installationen besser als RoCE.