4 Gründe für Storage-Latenzen und wie PMem Abhilfe schafft
Storage-Controller, Speichersoftware sowie externe und interne Verbindungen sorgen für Latenz in Storage-Systemen. Technologien wie Persistent Memory können dem entgegenwirken.
In dem Maße, wie sich SSDs in den Rechenzentren durchsetzen, gehen viele IT-Professionelle davon aus, dass Probleme mit der Speicher-Performance der Vergangenheit angehören. Dem ist jedoch nicht so.
Warum entspricht eigentlich nicht der gesamte IOPS-Wert eines Speichersystems oder Software-defined Storage (SDS) der Summe der eingesetzten SSDs? Flash-SSDs sind nun einmal nur ein Teil des Performance-Geheimnis eines Speichersystems oder von SDS. Und sie sind nicht einmal der größte Teil. Denn es gibt noch vier andere Ursachen von Speicherlatenz, die die Performance von Speichersystemen beeinflussen können. Zu ihnen gehören:
Storage-Controller
Komponenten der Speicher-Software
externe Verbindungen
interne Verbindungen
In diesem Artikel betrachten wir den Einfluss, den jeder dieser Faktoren auf die Performance hat. Zusätzlich überprüfen wir, was aus der Verbreitung von Persistent Memory (PMem) folgt und wie diese Technologie die Ursachen von Speicherlatenz und -Performance tangieren wird.
Was sind Storage-Latenzzeiten?
Storage Performance wird gemessen als First Byte Latency, Wartezeit (Tail Latency), Lese-IOPS, Schreib-IOPS, Random IOPS (Mischung aus Lesen und Schreiben, gewöhnlich mit einer Aufteilung von 70/30), sequentieller Lese- und sequentieller Schreibdurchsatz.
Storage-IOPS werden in der Regel als 4 KB IOPS gemessen, auch wenn viele Anwendungen 8 KB, 32 KB und sogar 64 KB aufweisen. Der Storage-Durchsatz wird in Megabytes per Sekunde oder Gigabytes per Sekunde festgelegt und oft durch die Multiplikation der IOPS-Nutzlast mit der Anzahl der IOPS berechnet.
Storage-Latenz ist ein wichtiger Aspekt von Storage-Performance. IOPS ohne die Messungen von Latenzzeiten sind bedeutungslos. Latenzzeiten diktieren die individuelle Reaktionsfähigkeit von I/O-Operationen. Man nehme zum Beispiel ein Speichersystem oder ein SDS, das 250.000 IOPS und eine Millisekunde an durchschnittlicher Latenz erzeugt. Das entspricht einer mittelmäßigen Performance. Wenn die erforderte durchschnittliche Latenz näher bei 200 Mikrosekunden liegt, wäre dieses Speichersystem nur in der Lage, 50.000 IOPS zu liefern.
Die beste Methode zur Messung von Speicherlatenz besteht darin, von dem Augenblick an zu beginnen, an dem eine Datenanfrage an den Storage-Layer geliefert wird, und sie zu beenden, wenn die angeforderten Daten eintreffen oder wenn es eine Bestätigung gibt, dass die Daten auf dem Laufwerk gespeichert sind. Die First Byte Latency ist die Latenz des ersten Byte der angeforderten Daten. Die Auswirkung der Wartezeit (Tail Latency) – die Zeit, die es dauert, bis das letzte Byte angekommen ist – ist wichtiger für die sendenden Anwendungen, die eine Synchronisation brauchen. Dies ist üblich beim High Performance Computing mit Multipath-I/O-Anwendungen.
Ein Speichersystem oder SDS, das es nicht schafft, alle zuvor erwähnten Technologien unter einen Hut zu bringen, wird keine optimierte Performance liefern. Eine vertiefte Untersuchung wird dazu weitere Details liefern können. Und weil die Latenz einen bedeutenden Einfluss auf IOPS und Durchsatz hat, ist sie ein guter Startpunkt. Im Folgenden ein näherer Blick auf vier Ursachen von Latenz in modernen Speichersystemen.
1. Storage-Controller
Latenz ist ein anderer Ausdruck für Verspätung oder Verzögerung. Es geht um den Zeitraum, in dem etwas geschieht. An jedem Punkt auf dem Weg zwischen der Anwendung und dem Speichermedium gibt es viele Möglichkeiten für eine Latenz.
Zu ihnen gehören der Applikationsserver mit seiner CPU, das Memory, das File System, der PCIe-Controller, der PCIe-Bus, die Netzwerk-Interface-Card (NIC) und andere Komponenten zu der Ziel-NIC oder dem Adapter des Speichersystems, das wiederum seine eigenen Komponenten zur Auslösung von Latenz besitzt. Jeder Schritt fügt eine mögliche Verzögerung oder Latenz hinzu, und diese Latenz niedrig zu halten oder auszuschalten erfordert Optimierungen an jedem Wegpunkt.
Speichersysteme besitzen einen speziell angefertigten oder universellen Storage-Controller oder mehrere Controller. Die am meisten verbreiteten Speichersysteme haben zwei Active-Active-Storage-Controller. SDS-Systeme haben eventuell dedizierte Storage-Controller. Diese Systeme sind oft Teil einer hyperkonvergenten Infrastructure (HCI) oder sie verfügen über dedizierte Storage-Controller. Ein Storage-Controller ist eigentlich ein Server und er hat einen enormen Einfluss auf Latenzzeiten, Lese- und Schreibvorgänge, IOPS und Durchsatz.
Die CPU des Controllers selbst fügt Speicherlatenz hinzu. Die Menge an Latenz variiert je nach CPU. Es gibt derzeit vier hauptsächliche Arten von Server-CPUs: Intel Xeon, AMD, IBM Power und Arm. Nicht alle CPUs sind gleich.
Manche besitzen mehr Cores als andere. IBM Power hat mehr Cache der Typen L2, L3 und L4 und ist RISC-basiert. Intel Xeon, AMD und Arm sind CISC-basiert. Arm verbraucht im allgemeinen weniger Energie, während Intel einige Varianten mit weniger Energieverbrauch im Angebot hat. Intel kann außerdem alleine seine 3D-XPoint-Variante benutzen: Sie erzielt niedrigere Latenz mit Persistent Non-Volatile Memory in einem DIMM-Einschub.
2. Komponenten der Speichersoftware
Software-defined Storage (SDS) in einer HCI-Umgebung teilt sich die CPU mit dem Hypervisor, den virtuellen Maschinen (VMs), Containern und Anwendungen. Deshalb stehen weniger CPU und Memory für den eigentlichen Storage-Bereich und Read/Write-I/Os zur Verfügung. Dies führt zu manchen Zugangskonflikten und zusätzlicher Latenz.
Alle diese Services verbrauchen CPU- und Memory-Ressourcen. Wenn ein bestimmter CPU-intensiver Speicherservice in der CPU läuft – wie zum Beispiel ein Wiederaufbau eines RAID-Laufwerks, ein Snapshot oder einfaches Erasure Coding –, kann er der CPU signifikante Read/Write-Latenz hinzufügen. Die meisten Komponenten der Speichersoftware wurden nicht mit dem Augenmerk auf CPU- und Memory-Leistungsfähigkeit entwickelt.
Diese fünf Technologien - Speicher-Controller, der Speicher-Software-Stack, externe und interne Verbindungen sowie PMem - sind gute Stellen, auf die man achten sollte, wenn man Ursachen für Speicherlatenz beseitigen will.
Effizienz oder Leistungsfähigkeit solcher Bereiche wurden im Allgemeinen als unwichtig betrachtet, solange man von der Gültigkeit des Moore’schen Gesetzes ausging. „Moore’s Law“ legte fest, dass sich die CPU-Performance alle zwei Jahre verdoppeln würde – und ursprünglich passierte das sogar alle 18 Monate.
Diese Verdopplung der Performance erklärte die Verbesserung der Softwareeffizienz zu einer Zeitverschwendung. Das gilt jedoch nicht mehr. Die CPUs erreichen diesen Maßstab von Moore’s Law nicht mehr. Die CPU-Zugewinne haben sich deutlich verlangsamt. Dies hat umgekehrt die Hersteller von Speichersystemen und SDS dazu gezwungen, ihre Architekturen kreativer zu gestalten, um mehr Performance aus ihnen herauszuholen.
StorOne ist ein Hersteller mit dem Fokus auf Effizienz des Software-Stacks. Leistungsfähigere Software stellt mehr CPU-Zyklen für Read/Write-Prozesse zur Verfügung. Die Umsetzung dieses Ansatzes ist nicht trivial und erfordert viel Zeit und Arbeit.
Ein paar andere Hersteller, zum Beispiel Hitachi Vantara, nutzen FPGAs (Field-Programmable Gate Arrays). Die Unternehmen Fungible und Mellanox Technologies verwenden ASICs, die für die Ausgliederung von einigen Elementen des Software-Stacks entwickelt wurden, um Verarbeitungszyklen freizustellen. Mehrere Hersteller, darunter Dell EMC, Hewlett Packard Enterprise, IBM und NetApp, implementieren Architekturen für Scale-out Storage, die dem System zusätzliche Controller, CPUs, Cores und Zyklen zur Verfügung stellen – außerdem unter anderem mehr Rack-Platz, Verkabelung und Switches.
Fungible verbindet die Auslagerung mit Scale-Out. Dagegen setzt Pavilion Data Systems auf Scale-In, indem mehr Controller und CPUs hinzugefügt werden, die die Softwareaufgaben intern per hoch-performantem PCIe-Switching verteilen. Man muss darauf achten, wie ein Speichersystem für Scale-Out sorgt. Das kann im Einzelfall bedeuten, nicht so wichtige Rückmeldungen an jeden zusätzlichen Controller zu verringern, indem die maximale Anzahl beschränkt wird. Wie wirksam ein Speicherhersteller die CPU-Probleme löst, hängt stark von dem Umgang mit der Read/Write-Latenz ab.
3. Externe Verbindungen
Die jeweilige externe Verbindung kann eine weitere größere Ursache von Storage-Latenz darstellen. Viele Speicherexperten befassen sich eher mit der Netzwerkbandbreite als mit Latenz. Die Bandbreite ist keineswegs unwichtig: Sie stellt besonders für Anwendungen auf Basis paralleler File-Systeme einen entscheidenden Faktor dar.
Die NICs, Adapter, PCIe-Version, Port-Anbindung und Switches haben alle eine Auswirkung auf die Bandbreite. Die Bandbreite von PCIe Gen 3 bietet 128 Gbps bei 16 Spuren: Sie kann tatsächlich 200 bis 400 Gb/s-Ports unterstützen. PCIe Gen 4 besitzt die zweifache Bandbreite von Gen 3, während PCIe Gen 5 auf das Doppelte von Gen 4 kommt.
Aber Speicherlatenzzeiten sind das bei weitem allgegenwärtige und generell zutreffende Performance-Problem. Standard TCP/IP Ethernet, das für NFS, SMB und iSCSI genutzt wird, zeigt die höchste Netzwerk-Latenz. Fibre Channel (FC) weist die danach höchste Latenz auf. Netzwerke mit Remote Direct Memory Access – wie zum Beispiel InfiniBand, RDMA over converged Ethernet (RoCE) und NVMe-oF auf InfiniBand, Ethernet, FC und TCP/IP Ethernet – weisen die niedrigste Netzwerklatenz auf. RDMA reduziert weitgehend externe Latenz zwischen den Anwendungsservern und dem Speichersystem oder SDS – an der CPU vorbei und direkt zum Memory gehend.
Die Latenz von RDMA entsprechen denen von internem Direct-Attached Storage (DAS). Die Menge an Memory in jedem Controller wird zur entscheidenden Größe, um die Latenz zu verkleinern und die Performance zu vergrößern.
Manche Beobachter der Szene verweisen darauf, dass die externen Verbindungen zwischen Applikationen und SDS bei HCI-Umgebungen irrelevant sind, aber das ist nicht richtig. Es gibt mehrere Knoten in den meisten HCI-Clustern. Die tatsächliche Latenz zwischen einer Anwendung in einem Knoten und dem Speichersystem in einem anderen hängt vor allem von der externen Verbindung zwischen beiden ab – genauso wie es der Fall ist bei Speichersystemen und unabhängigen SDS.
4. Interne Verbindungen
Die nächste Ursache für Storage-Latenz findet sich bei der internen Verbindung. NVMe ist heute die Flash-SSD-Schnittstelle mit der niedrigsten Latenz und der höchsten Performance. Diese Technologie benutzt auch eine PCIe-Bus-Verbindung.
Die meisten CPUs verfügen nur über eine begrenzte Anzahl von PCIe-Einschüben. Einige von ihnen sind für externe Verbindungen erforderlich. Einige werden eventuell für GPUs oder für andere Aufgaben verwendet. Es gibt auf jeden Fall eine klare Begrenzung bei der Anzahl der NVMe-Laufwerke, die mit einem bestimmten Storage-Controller verbunden werden können. Um diese Anzahl zu erhöhen, braucht man in jedem Fall mehr Interconnect-Controller, einen PCIe-Switch oder beides.
Abbildung 1: Unterschiedliche Memory-Klassen bieten verschiedene Leistungsklassen und Latenz.
Die meisten All-Flash-Arrays (AFA) haben bisher SAS/SATA-Flash-SSDs genutzt. Die SAS/SATA-Controller fügen einen weiteren Latenz-Sprung nach vorne hinzu. Außerdem ist die Bandbreite eines SATA-Laufwerks auf 6 Gb/s begrenzt, während die Bandbreite eines SAS-Laufwerks bis zu 24 Gb/s reicht. Diese Verbindungen besitzen weniger Bandbreite und deutlich mehr Latenz.
Wie Persistent Memory die Storage Performance optimieren kann
Und dann gibt es noch die neuesten nichtflüchtigen Medien mit Namen „3D XPoint“ (Intel vermarktet sie als „Optane“). 3D XPoint ist schneller und besitzt eine höhere Haltbarkeit als NAND-Flash, aber es ist langsamer als Dynamic RAM (DRAM). Es ist verfügbar als NVMe-Laufwerk, genannt Storage Class Memory (SCM), und als DIMM, genannt PMem (Persistent Memory).
SCM-Laufwerke gibt es von Intel und Micron. PMem ist nur bei Intel verfügbar. SCM ist ungefähr dreimal schneller als NVMe-NAND-Flash-Laufwerke. Unglücklicherweise stellt die Rechtfertigung seiner Kosten das Problem dar – SCM-Laufwerke kosten auf einer Gigabyte-Basis beträchtlich mehr als dreimal soviel. Sogar dann, wenn Dell EMC, StorOne und Vast Data SCM-Laufwerke als eine Hoch-Performance-Schicht in ihren Architekturen anbieten.
PMem ist eine andere Geschichte. PMem könnte einen direkteren Weg zur Ausschaltung von Storage-Latenz eröffnen. Es verbindet sich via DIMM-Einschub mit dem Memory-Bus. Die Kapazitäten sind doppelt so hoch wie jene von DRAM DIMMs – bis zu 512 Gigabyte oder ungefähr drei Terabyte an PMem pro Server. Aber jedes PMem-Modul muss mit einem DRAM-Modul gekoppelt werden. Die Latenz von PMem ist etwa 25 mal höher als die von DRAM, aber mehr als 80 mal niedriger als die von NVMe-Flash.
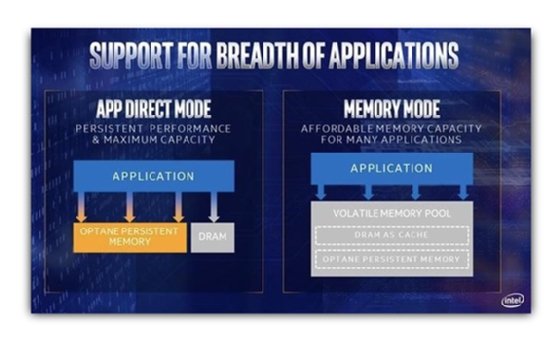
Abbildung 2: Persistent Memory von Intel kann in zwei Modi genutzt werden, was die Latenz optimieren soll.
PMem von Intel besitzt zwei Betriebsmodi – Memory Mode und App Direct Mode. Memory Mode versetzt PMem in den Zustand eines flüchtigen (volatile) Memory, weil PMem als DRAM-Cache verwendet, um es gegenüber den Anwendungen transparent zu machen. Der Modus App Direct besitzt vier Varianten. Alle von ihnen erfordern Modifikationen auf der Seite der Anwendungen, um PMem als eine extrem hoch-performante Speicherschicht zu verwenden.
Im Moment hat nur Oracle PMem in den Speicher seines Exadata-Systems eingebaut. Es nutzt 100-Gb/s-RoCE, um die Exadata Datenbank-Server mit den Storage-Servern zu verbinden. Das System erlaubt allen Exadata Datenbank-Servern Zugang zu allen PMem-Bereichen in den Storage-Servern. Oracle kann bis zu 1,5 Terabyte an PMem pro Storage-System zur Verfügung stellen, 27 Terabyte pro Rack und fast ein halbes Petabyte pro System. Man kann davon ausgehen, dass andere Speicherhersteller bald diesen Ansatz auch umsetzen.
Insgesamt betrachtet haben alle diese Technologien – Storage Controller, der Software-Stack, externe und interne Verbindungen sowie PMem – einen besonders großen Einfluss auf Speichersysteme und SDS, was Latenz, IOPS, Durchsatz und Bandbreite betrifft. Auf diese Bereiche sollte man gut aufpassen, wenn man seinen Enterprise Storage modernisieren und die Ursachen von Speicher-Latenz beseitigen will.