
Vasily Merkushev - stock.adobe.c
Wie Anwender von Self-Service-Datenaufbereitung profitieren
Die Verwendung von Self-Service-Tools zur Datenaufbereitung vereinfacht Analyse- und Visualisierungsaufgaben und beschleunigt Modellierungsprozesse für Datenwissenschaftler.
In den Bereichen Datenwissenschaft und Datenanalyse wird häufig behauptet, dass Datenaufbereitung und -verarbeitung 80 Prozent der Arbeit ausmacht. Warum ist so viel Aufwand erforderlich, um Daten aufzubereiten, bevor sie analysiert werden können?
Daten in Geschäftsanwendungen werden selten in einem für die Analyse geeigneten Format gespeichert. Das Kassensystem im Supermarkt ist darauf optimiert, den Inhalt des Einkaufswagens zu überprüfen und das Inventarsystem so effizient wie möglich zu aktualisieren. Es ist nicht darauf ausgelegt, vierteljährliche Bestandsberichte und Vorhersagen für die Lieferkette zu liefern.
Ebenso wichtig ist, dass die Daten selten die richtige Qualität für die Analyse haben. Einige Datensätze enthalten fehlende, falsche oder inkonsistente Werte; diese müssen korrigiert werden, und dieser Prozess kann kompliziert sein. Sie wollen auch nicht, dass die Datenanalyse Ihre operativen Systeme verlangsamt, also müssen Sie die Daten für Analysen und Berichte an einen neuen Ort verschieben – und dabei häufig die Daten anpassen, kombinieren und Datenqualitätsoperationen anwenden.
Aus all diesen Gründen ist Datenaufbereitung ein wichtiger – und in der Tat unvermeidlicher – Schritt bei Analyseanwendungen. Ich sage sogar oft, dass Datenaufbereitung in einem wesentlichen Sinne eine Datenanalyse ist, da man wissen muss, wie man die Daten verwenden will, um zu wissen, wie man sie aufbereiten muss. Meistens ist es nicht die IT-Abteilung, die diese Anwendungsfälle wirklich versteht, sondern es sind die Geschäftsanwender oder Datenwissenschaftler. Mittlerweile gibt es Tools, mit denen sich Daten im Self-Service aufbereiten lassen.
Was ist Self-Service-Datenaufbereitung?
Selbst in der jüngeren Vergangenheit war Datenanalyse eine Domäne von Spezialisten, in der Regel innerhalb von IT-Teams, denn nur Experten konnten die komplexen Berechnungen durchführen und die richtigen Datenvisualisierungen und -ausgaben auswählen. Auch die Datenaufbereitung war eine spezialisierte Aufgabe mit ihren eigenen Komplexitäten bei der Kombination, Bereinigung und Optimierung von Datensätzen.
In den letzten Jahren hat sich die Analysepraxis stark weiterentwickelt, und mittlerweile stehen Geschäftsanwendern gute, relativ einfache Tools für Analyse, Visualisierung, Berichterstattung und Data Storytelling zur Verfügung. Sie müssen zwar Experten auf dem Gebiet der Wirtschaft sein, aber ein Großteil des technischen Aufwands wird von intelligenteren Business-Intelligence-Anwendungen übernommen.
Da die Geschäftsanwender mit Self-Service-BI und -Analysen vertraut geworden sind, möchten sie auch direkt mit den Daten arbeiten. Auch wenn Sie Ihre eigenen Visualisierungen, Berichte und Dashboards erstellen können, ist es ein Hindernis für Ihre Produktivität, wenn Sie immer wieder die IT-Abteilung oder das Datenmanagementteam um weitere Daten bitten müssen, die so organisiert und formatiert sind, wie Sie es wünschen.
Datenwissenschaftler befinden sich in einer ähnlichen Situation, allerdings mit einigen Unterschieden. Auch sie müssen Daten aus den operativen Systemen an einen geeigneten Ort für maschinelles Lernen, prädiktive Modellierung und andere fortgeschrittene Analysen bringen. Auch sie müssen Datensätze bereinigen, aber sie können einige der Inkonsistenzen nützlich finden – zum Beispiel für Betrugsanalysen. Außerdem müssen die Daten in der richtigen Form vorliegen, damit ihre Algorithmen damit arbeiten können, was bedeuten kann, dass sie in einer sehr großen Tabelle zusammengefasst werden. In der Regel wollen sie all diese Dinge selbst erledigen.
Die Self-Service-Datenaufbereitung macht dies für Datenwissenschaftler und Geschäftsanwender möglich, indem sie die Datenbeschaffung, -aufbereitung und -bereinigung häufig von einfach zu bedienenden Desktop- oder Cloud-Anwendungen aus erledigen.
Wie Self-Service-Datenaufbereitung funktioniert
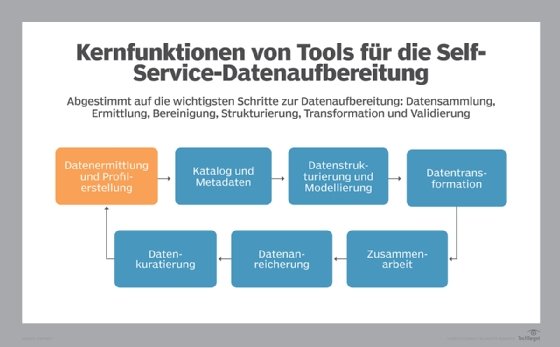
In vielerlei Hinsicht ist der Prozess der Self-Service-Datenaufbereitung derselbe wie bei herkömmlichen IT-gesteuerten Datenaufbereitungsprozessen. Nachfolgend finden Sie sechs etwas vereinfachte Schritte:
- Sammeln von Daten. Bei der Datenaufbereitung sammelt die IT-Abteilung Daten aus dem gesamten Unternehmen, wobei sie häufig spezielle Konnektoren und Know-how über Datenbanktechnologien einsetzt. Geschäftsanwender stellen höchstwahrscheinlich über vereinfachte Konnektoren, die in ihre Self-Service- Datenaufbereitungsplattform integriert sind, eine Verbindung zu vertrauten Anwendungen her.
- Profiling der Daten. Um effektiv mit den gesammelten Daten arbeiten zu können, müssen Sie sie in der Vorschau prüfen und sehen, wie vollständig und genau sie sind. Self-Service-Tools umfassen in der Regel Data-Profiling-Funktionen, die auch statistische Informationen über Wertebereiche, Ausreißer, Fehler und andere Datenattribute und -probleme liefern.
- Daten zusammenführen. Wenn Sie Daten aus verschiedenen Datensätzen oder aus verschiedenen Tabellen in einem Datensatz analysieren müssen, müssen Sie die Daten zunächst zusammenführen. Die Logik und der Code für die Durchführung von Joins ist immer noch eine beliebte Frage in technischen Prüfungen für Datenbankprogrammierer. Aber Self-Service-Tools helfen Ihnen dabei und machen Joins oft so einfach wie ein Drag-and-Drop-Verfahren.
- Daten bereinigen. Ihre Daten sind selten sofort gut genug für die Analyse. Möglicherweise müssen Sie Standardwerte für fehlende Werte hinzufügen oder verschiedene Formate an dasselbe Muster anpassen, zum Beispiel an einen Standard-Ländercode. Zunehmend bieten Datenaufbereitungsanwendungen hervorragende Datenqualitätsfunktionen. Andere bieten einfachere Funktionen mit Integrationen zu spezialisierten Datenqualitätsdiensten.
- Daten transformieren. Wie bereits erwähnt, müssen die Daten für die Analyse in die richtige Form gebracht werden. Es besteht beispielsweise ein erheblicher Unterschied zwischen den flachen Strukturen, die Datenwissenschaftler verwenden, und den hierarchischen Strukturen, die von Finanzanalysten genutzt werden. Diese Formgebung ist ein wichtiges Element der Datentransformation, bei der es auch darum geht, die Daten in das richtige Format für den letzten Schritt zu bringen.
- Speicherung der aufbereiteten Daten. Nach all dieser Arbeit müssen die Daten für die künftige Verwendung irgendwo gespeichert werden. Übliche Ziele sind Data Warehouses und Data Lakes, in denen Sie die Daten auch anderen Benutzern zur Verfügung stellen können. Sie können die Daten auch in einem System speichern, das speziell auf Ihr bevorzugtes BI- und Datenvisualisierungs-Tool zugeschnitten ist. Oder Sie speichern sie einfach lokal für Ihre eigene Verwendung.
Gute Self-Service-Datenaufbereitungs-Tools enthalten Funktionen, die all diese Schritte unterstützen, auch wenn der Ablauf des Datenaufbereitungsprozesses in einigen Fällen etwas anders ist.
Die Vorteile der Self-Service-Datenaufbereitung
Die Vorteile der Self-Service- Datenaufbereitung lassen sich in die folgenden drei Kategorien einteilen:
- Sie ermöglicht es Geschäftsanwendern und Data Scientists, agiler und effizienter zu arbeiten, indem sie ihnen vereinfachte Tools zur Verfügung stellt, mit denen sie traditionell komplexe Arbeiten selbst erledigen können. Dies erspart ihnen zeitaufwendige Prozesse, bei denen das IT-Team Anforderungen sammelt, Prototypen erstellt und testet und Feedback einholt.
- Dadurch, dass Analytik-Nutzer ihre Datenaufbereitung selbst durchführen können, werden außerdem IT- und Datenmanagementressourcen für produktivere Aufgaben freigesetzt.
- Der Self-Service-Ansatz ermöglicht es, die Datenaufbereitungsarbeit breiter über das gesamte Unternehmen und seine IT-Infrastruktur zu verteilen, wodurch Engpässe vermieden und die Ausfallsicherheit erhöht werden.
Ein gutes Beispiel für diese Vorteile in der Praxis ist, wenn Marketingteams auf erhebliche Veränderungen im Geschäftsumfeld reagieren müssen. Wir alle haben dies bei der COVID-19-Pandemie erlebt. Nach dem Ausbruch des Virus wollten viele Einzelhändler die Kundendaten von physischen Standorten mit Online-Aktivitäten und lokalen Daten über COVID-19-Fälle verknüpfen. Sie wollten einfache Fragen mit schwierigen Antworten stellen, zum Beispiel welche Kundenfrequenz sie noch erwarten konnten und wie viel Geschäft sich ins Internet verlagert lässt.
Meistens existierten diese Datensätze nicht, da dieses Szenario neu war. Die IT-Teams – die damals mit ihren eigenen neuen Herausforderungen zu kämpfen hatten – hätten Wochen für die Aufbereitung der Daten gebraucht, selbst wenn sie die Arbeit nach Prioritäten geordnet hätten. Durch die Self-Service-Datenaufbereitung konnten die Marketingteams jedoch problemlos interne und externe Datensätze beschaffen, sie zusammenführen und nach Bedarf bereinigen und umwandeln. Diese Beschleunigung der Analysen erwies sich für Unternehmen als entscheidend, um auf die Pandemie zu reagieren.
Diese spezifischen Vorteile sind überzeugend, aber viele Unternehmen finden den letzten Vorteil der Self-Service-Datenaufbereitung am wichtigsten, auch wenn er am schwierigsten zu quantifizieren ist. Die gesteigerte Effizienz für die Benutzer macht es ihnen leichter und wahrscheinlicher, neue Szenarien zu erforschen und innovative Methoden zur Analyse von Geschäftsabläufen auszuprobieren. Der ultimative Vorteil der Self-Service-Datenaufbereitung besteht darin, dass das Unternehmen besser mit seinen Geschäftsdaten verbunden ist und diese besser nutzen kann.
Self-Service-Datenaufbereitung im Vergleich zu ETL und Data-Science-Pipelines
Self-Service-Tools für die Datenaufbereitung sind natürlich nicht die einzige Möglichkeit, die es gibt. Es gibt immer noch etablierte Anwendungen, die für die IT entwickelt wurden – in erster Linie ETL-Tools (Extract, Transform, Load). Für Datenwissenschaftler stehen andere Datenaufbereitungstechnologien zur Verfügung. Wie lassen sich diese miteinander vergleichen?
Der erste und wichtigste Unterschied ist die Einfachheit und Benutzerfreundlichkeit. Self-Service-Tools sind für Nicht-Spezialisten konzipiert. Sie erfordern zwar eine gewisse Einarbeitung – und es lohnt sich auf jeden Fall, sie zu studieren und zu üben –, aber sie sind so konzipiert, dass die Benutzer schnell loslegen können.

ETL ist eine schwergewichtige Datenintegrationstechnologie, die dazu dient, große Datenmengen zwischen Datenbanken zu verschieben und sie während der Verschiebung zu formen und zu bereinigen. ETL-Tools können so konfiguriert werden, dass sie die fortschrittlichsten Funktionen von Datenbanken nutzen, und sie enthalten erweiterte Funktionen für die Fehlerbehandlung und die Erstellung komplexer Logik. Auch wenn die Tools einfacher zu bedienen sind, ist ETL oft eine spezialisierte Aufgabe, insbesondere in großen Unternehmen.
Während Datenwissenschaftler in einigen Anwendungen Self-Service-Tools für die Datenaufbereitung verwenden, erledigen viele einen Großteil ihrer Arbeit in Skriptsprachen wie Python und R. Meistens entwickeln sie nicht nur ein Skript, sondern eine Reihe von zusammenhängenden Skripten mit komplizierten Abhängigkeiten zwischen ihnen. Durch die Koordinierung der Skripte entsteht eine Data-Science-Pipeline, die eine Reihe von Aktionen auf einen Datensatz anwendet. Auch wenn die Erstellung solcher Pipelines dank neuer Tools immer einfacher wird, bleibt sie eine spezielle Option für die Datenwissenschaft.
Für einfachere Data-Science-Szenarien und für Geschäftsanwender, die regelmäßig Daten analysieren und Visualisierungen und Berichte erstellen müssen, ist die Self-Service- Datenaufbereitung eine zunehmend wichtige Fähigkeit. Sie wissen nur zu gut, dass Daten selten perfekt für die jeweilige Aufgabe sind – und sie sind diejenigen, die am besten in der Lage sind, sie für den beabsichtigten Zweck zu nutzen.







