Datenarchitektur

Was ist eine Datenarchitektur?
Eine Datenarchitektur (Data Architecture) dokumentiert die Datenbestände eines Unternehmens, bildet den Datenfluss durch die Systeme ab und liefert einen Plan für das Datenmanagement. Damit soll sichergestellt werden, dass die Daten ordnungsgemäß verwaltet werden und den geschäftlichen Anforderungen an Informationen entsprechen.
Die Datenarchitektur kann zwar betriebliche Anwendungen unterstützen, definiert aber vor allem die zugrunde liegende Datenumgebung für Business Intelligence (BI) und Advanced Analytics. Sie umfasst ein mehrschichtiges Framework für Datenplattformen und Datenmanagement-Tools sowie Spezifikationen und Standards für die Erfassung, Integration, Umwandlung und Speicherung von Daten.
Im Idealfall ist der Entwurf der Datenarchitektur der erste Schritt im Datenmanagementprozess. Dies ist jedoch in der Regel nicht der Fall, was zu inkonsistenten Umgebungen führt, die im Rahmen einer Datenarchitektur harmonisiert werden müssen. Außerdem sind Datenarchitekturen trotz ihrer grundlegenden Natur nicht in Stein gemeißelt und müssen aktualisiert werden, wenn sich Daten und Geschäftsanforderungen ändern. Das macht sie zu einer ständigen Aufgabe für Datenmanagementteams.
Die Datenarchitektur geht Hand in Hand mit der Datenmodellierung, bei der Diagramme von Datenstrukturen, Geschäftsregeln und Beziehungen zwischen Datenelementen erstellt werden. Es handelt sich dabei jedoch um zwei unterschiedliche Disziplinen des Datenmanagements.
Wie haben sich Datenarchitekturen entwickelt?
In der Vergangenheit waren die meisten Datenarchitekturen weniger kompliziert als heute. Sie umfassten meist strukturierte Daten aus Transaktionsverarbeitungssystemen, die in relationalen Datenbanken gespeichert wurden. Analyseumgebungen bestanden aus einem Data Warehouse, manchmal mit kleineren Data Marts, die für einzelne Geschäftsbereiche erstellt wurden, und einem operativen Datenspeicher als Staging Area. Die Transaktionsdaten wurden für die Analyse in Batch-Jobs verarbeitet, wobei ETL-Prozesse (Extract, Transform, Load) für die Datenintegration verwendet wurden.
Ab Mitte der 2000er Jahre wurden durch die Einführung von Big-Data-Technologien in Unternehmen unstrukturierte und semistrukturierte Daten in viele Architekturen aufgenommen. Dies führte zum Einsatz von Data Lakes, in denen Rohdaten häufig in ihrem ursprünglichen Format gespeichert werden, anstatt sie für die Analyse im Vorfeld zu filtern und umzuwandeln – eine große Veränderung gegenüber dem Data-Warehousing-Prozess. Der neue Ansatz führt zu einem verstärkten Einsatz von ELT-Datenintegration (Extract, Load, Transform), einer Alternative zu ETL, bei der die Lade- und Transformationsschritte umgekehrt werden.
Die zunehmende Verwendung von Stream-Processing-Systemen hat auch dazu geführt, dass Echtzeitdaten in mehr Datenarchitekturen eingesetzt werden. Viele Architekturen unterstützen jetzt Anwendungen für künstliche Intelligenz (KI) und maschinelles Lernen, zusätzlich zu den grundlegenden BI- und Berichtsfunktionen von Data Warehouses. Die Verlagerung zu Cloud-Systemen erhöht die Komplexität der Datenarchitekturen zusätzlich.
Ein weiteres neues Architekturkonzept ist die Data Fabric, die darauf abzielt, Datenintegrations- und -managementprozesse zu rationalisieren. Es bietet eine Vielzahl von potenziellen Anwendungsfällen in Datenumgebungen.
Warum sind Datenarchitekturen wichtig?
Eine gut durchdachte Datenarchitektur ist ein entscheidender Bestandteil des Datenmanagementprozesses. Sie unterstützt die Datenintegration und die Verbesserung der Datenqualität sowie das Data Engineering und die Datenaufbereitung. Sie ermöglicht auch eine effektive Datenverwaltung und die Entwicklung interner Datenstandards. Diese beiden Faktoren wiederum unterstützen Unternehmen dabei, sicherzustellen, dass ihre Daten korrekt und konsistent sind.
Eine Datenarchitektur ist auch die Grundlage für eine Datenstrategie, die die Unternehmensziele und -prioritäten unterstützt. Laut Donald Farmer, Principal Consultant beim Beratungsunternehmen TreeHive Strategy, „hängt eine moderne Geschäftsstrategie von Daten ab. Deshalb sind Datenmanagement und -analyse zu wichtig, um sie Einzelpersonen zu überlassen.“ Um Daten gut zu verwalten und zu nutzen, muss ein Unternehmen eine umfassende Datenstrategie entwickeln, die durch eine starke Datenarchitektur untermauert wird.

Was sind die Merkmale und Komponenten einer Datenarchitektur?
Farmer betont, wie wichtig es ist, sowohl Data-Governance- als auch Compliance-Prozesse einzubeziehen sowie die wachsende Notwendigkeit, Multi-Cloud-Umgebungen zu unterstützen. Der potenzielle Geschäftswert von Daten wird vergeudet, wenn eine Datenarchitektur sie nicht für Analysezwecke verfügbar macht.
„Es ist ein Klischee des modernen Datenmanagements, dass Daten per se ein Geschäftswert sind“, sagt Farmer. „Aber Daten, die einfach herumliegen, sind nur eine Kostenstelle, die gepflegt werden muss, ohne einen geschäftlichen Nutzen zu bringen.“
Zu den weiteren gemeinsamen Merkmalen von gut konzipierten Datenarchitekturen gehören
- ein geschäftsorientierter Fokus, der auf die Unternehmensstrategien und Datenanforderungen abgestimmt ist
- Flexibilität und Skalierbarkeit, um verschiedene Anwendungen zu ermöglichen und neue Geschäftsanforderungen an Daten zu erfüllen
- starke Sicherheitsvorkehrungen zum Schutz vor unbefugtem Datenzugriff und unsachgemäßer Nutzung der Daten
Aus der Sicht eines Puristen umfassen die Komponenten einer Datenarchitektur keine Plattformen, Tools oder andere Technologien. Stattdessen handelt es sich bei einer Datenarchitektur um eine konzeptionelle Infrastruktur, die durch eine Reihe von Diagrammen und Dokumenten beschrieben wird. Datenmanagementteams verwenden diese dann als Leitfaden für die Bereitstellung von Technologien und die Verwaltung der Daten.
Einige Beispiele für diese Komponenten sind
- Datenmodelle, Datendefinitionen und gemeinsame Vokabularien für Datenelemente
- Datenflussdiagramme, die veranschaulichen, wie Daten durch Systeme und Anwendungen fließen
- Dokumente, die die Datennutzung auf Geschäftsprozesse abbilden, wie zum Beispiel eine CRUD-Matrix – kurz für create, read, update und delete
- andere Dokumente, die Geschäftsziele, -konzepte und -funktionen beschreiben, um die Datenmanagementinitiativen darauf abzustimmen
- Richtlinien und Standards, die regeln, wie Daten gesammelt, integriert, umgewandelt und gespeichert werden
- ein übergeordnetes Architekturkonzept mit verschiedenen Ebenen für Prozesse wie Dateneingabe, Datenintegration und Datenspeicherung
Was sind die Vorteile einer Datenarchitektur?
Im Idealfall hilft eine gut konzipierte Datenarchitektur einem Unternehmen, effektive Datenanalyseplattformen zu entwickeln, die nützliche Informationen und Erkenntnisse liefern. In Unternehmen verbessern diese Erkenntnisse die strategische Planung und die betriebliche Entscheidungsfindung, was zu einer besseren Unternehmensleistung und zu Wettbewerbsvorteilen führen kann. Sie unterstützen auch bei verschiedenen anderen Anwendungen, zum Beispiel bei der Diagnose von Krankheiten und in der wissenschaftlichen Forschung.
Die Datenarchitektur trägt unter anderem dazu bei, die Datenqualität zu verbessern, die Datenintegration zu optimieren und die Kosten für die Datenspeicherung zu senken. Laut Peter Aiken, Berater für Datenmanagement und außerordentlicher Professor für Informationssysteme an der Virginia Commonwealth University, wird dabei eine unternehmensweite Perspektive eingenommen, im Gegensatz zu einer bereichsspezifischen Datenmodellierung oder einer Architektur auf Datenbankebene.
„Wenn wir es aus einer Datenarchitekturperspektive betrachten, haben wir ein größeres Wertpotenzial, und das liegt daran, dass wir eine breite Nutzung [von Daten] über alle Datenbanken hinweg betrachten“, sagt Aiken.
Welche Risiken birgt das Design einer schlechten Datenarchitektur?
Ein Fallstrick der Datenarchitektur ist zu viel Komplexität. Die gefürchtete Spaghetti-Architektur mit einem Gewirr von Linien, die verschiedene Datenflüsse und Punkt-zu-Punkt-Verbindungen darstellen, ist ein Beleg dafür. Das Ergebnis ist eine unübersichtliche Datenumgebung mit inkompatiblen Datensilos, die sich für Analysezwecke nur schwer integrieren lassen. Ironischerweise zielen Datenarchitekturprojekte oft darauf ab, Ordnung in bestehende unordentliche Umgebungen zu bringen, die sich organisch entwickelt haben. Wenn sie jedoch nicht sorgfältig verwaltet werden, können sie ähnliche Probleme verursachen.
Eine weitere Herausforderung besteht darin, eine allgemeine Einigung über standardisierte Datendefinitionen, -formate und -anforderungen zu erzielen. Ohne dies ist es schwierig, eine effektive Datenarchitektur zu erstellen. Das Gleiche gilt für die Einordnung von Daten in einen geschäftlichen Kontext. Eine gut gemachte Datenarchitektur „erfasst die geschäftliche Bedeutung der Daten, die für den Betrieb des Unternehmens erforderlich sind“, erklärt Aiken. Wenn dies jedoch nicht der Fall ist, kann es zu einer Diskrepanz zwischen der Architektur und den strategischen Datenanforderungen kommen, die sie erfüllen soll.
Datenarchitektur versus Datenmodellierung
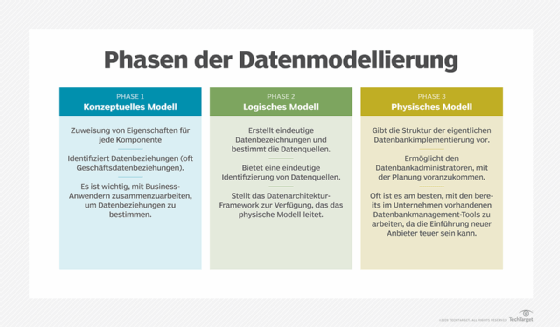
Die Datenmodellierung konzentriert sich auf die Details bestimmter Datenbestände. Sie erstellt eine visuelle Darstellung der Dateneinheiten, ihrer Attribute und der Beziehungen zwischen den verschiedenen Einheiten. Dies hilft bei der Festlegung der Datenanforderungen für Anwendungen und Systeme und dem anschließenden Entwurf von Datenbankstrukturen für die Daten, ein Prozess, der durch eine Abfolge von konzeptionellen, logischen und physischen Datenmodellen erfolgt.
Bei der Datenarchitektur werden die Daten eines Unternehmens aus einer umfassenderen Perspektive betrachtet, um einen Rahmen für die Datenverwaltung und -nutzung zu schaffen. Wie Berater Loshin sagt, „ergänzen sich Datenmodellierung und Datenarchitektur gegenseitig. Datenmodelle sind ein entscheidendes Element in Datenarchitekturen, und eine etablierte Datenarchitektur vereinfacht die Datenmodellierung.“
Rick Sherman, Managing Partner des Beratungsunternehmens Athena IT Solutions, erläutert in seinem Artikel sieben Techniken zur Datenmodellierung, darunter die derzeit am häufigsten verwendeten Ansätze zur Modellierung von Entity-Relationships, Dimensionen und Graphen. Außerdem stellte er eine Reihe von Best Practices für die Datenmodellierung vor, darunter:
- Sammeln Sie im Vorfeld sowohl Geschäfts- als auch Datenanforderungen, bevor Sie Modelle erstellen.
- Entwickeln Sie Datenmodelle iterativ und inkrementell, um den Prozess überschaubar zu machen.
- Verwenden Sie Datenmodelle als Werkzeug für die Kommunikation mit Geschäftsanwendern über deren Bedürfnisse.
- Verwalten Sie Datenmodelle wie jede andere Art von Anwendungscode.
Datenarchitektur versus Informationsarchitektur und Unternehmensarchitektur
Sherman erläutert zudem den Unterschied zwischen Datenarchitektur und Informationsarchitektur in Unternehmensanwendungen. „Informationen sind Daten im Kontext“, sagt er. „Eine Informationsarchitektur definiert den Kontext, den ein Unternehmen für seine Geschäftsabläufe und sein Management verwendet. Eine Datenarchitektur, die qualitativ hochwertige und zuverlässige Daten liefert, bildet die Grundlage für die Informationsarchitektur.“
Inzwischen wird die Datenarchitektur gemeinhin als Teil der Unternehmensarchitektur (Enterprise Architecture, EA) betrachtet, die darauf abzielt, einen organisatorischen Entwurf für ein Unternehmen in vier Bereichen zu erstellen. Diese umfasst außerdem:
- Geschäftsarchitektur (Business Architecture), die sich mit der Geschäftsstrategie und den wichtigsten Geschäftsprozessen befasst
- Anwendungsarchitektur (Application Architecture), die sich auf die einzelnen Anwendungen und ihre Beziehungen zu den Geschäftsprozessen konzentriert
- Technologiearchitektur (Technology Architecture), die IT-Systeme, Netzwerke und andere Technologien umfasst, welche die anderen drei Bereiche unterstützen
Welche Datenarchitektur-Frameworks gibt es?
Unternehmen können standardisierte Frameworks verwenden, um Datenarchitekturen zu entwerfen und zu implementieren, anstatt ganz von vorne anzufangen. Drei dieser Frameworks sind:
DAMA DMBOK2. Der DAMA Guide to the Data Management Body of Knowledge ist ein Datenmanagement-Framework und ein Referenzhandbuch, das von DAMA International, einem Berufsverband für Datenmanager, erstellt wurde. In seiner zweiten Auflage, die allgemein als DAMA DMBOK2 bekannt ist, befasst sich das Framework mit der Datenarchitektur und anderen Datenmanagementdisziplinen. Die erste Ausgabe wurde 2009 veröffentlicht, und die zweite ist seit 2017 erhältlich.
TOGAF. The Open Group Architecture Framework (TOGAF) wurde 1995 entwickelt und seitdem mehrmals aktualisiert. Es handelt sich dabei um ein Framework und eine Methodik für die Unternehmensarchitektur, die auch einen Abschnitt über das Design von Datenarchitekturen und die Entwicklung von Roadmaps enthält. Es wurde von The Open Group entwickelt, und TOGAF stand ursprünglich für The Open Group Architecture Framework. Mittlerweile wird er jedoch einfach als TOGAF-Standard bezeichnet.
Zachman Framework. Beim Zachman Framework handelt es sich um ein Ontologie-Framework, das eine 6-x-6-Matrix aus Zeilen und Spalten verwendet, um eine Unternehmensarchitektur zu beschreiben, einschließlich der Datenelemente. Es enthält keine Implementierungsmethodik, sondern soll als Grundlage für eine Architektur dienen. Das Framework wurde ursprünglich 1987 von John Zachman entwickelt, einer IBM-Führungskraft, die 1990 aus dem Unternehmen ausschied und eine Beratungsfirma namens Zachman International gründete.
Wichtige Schritte zur Erstellung einer Datenarchitektur
Datenmanagementteams müssen bei der Entwicklung einer Datenarchitektur eng mit Geschäftsführern und anderen Endanwendern zusammenarbeiten. Ist dies nicht der Fall, stimmt sie möglicherweise nicht mit den Geschäftsstrategien und Datenanforderungen überein. Zwei der neun Planungsschritte für die Datenarchitektur, die Berater Loshin auflistet, sind die Einbindung von Führungskräften, um deren Unterstützung zu erhalten, und Treffen mit Benutzern, um deren Datenanforderungen zu verstehen.
Neben anderen Schritten empfiehlt er Unternehmen auch:
- Bewertung von Datenrisiken auf der Grundlage von Data-Governance-Richtlinien
- Datenflüsse sowie Informationen zum Datenlebenszyklus und zur Datenabfolge aufzeichnen
- die bestehende technologische Infrastruktur für die Datenverwaltung zu dokumentieren und zu bewerten
- einen Fahrplan für die Projekte zur Einführung der Datenarchitektur aufstellen
Welche verschiedenen Rollen gibt es bei der Entwicklung von Datenarchitekturen?
Die Führungsrolle bei Datenarchitekturinitiativen liegt in der Regel bei Datenarchitekten. Sie benötigen eine Vielzahl von technischen Fähigkeiten sowie die Fähigkeit, mit Geschäftsanwendern zu interagieren und zu kommunizieren. Ein Datenarchitekt verbringt viel Zeit damit, mit Endbenutzern zusammenzuarbeiten, um Geschäftsprozesse und die bestehende Datennutzung sowie neue Datenanforderungen zu dokumentieren.
Auf der technischen Seite erstellen Datenarchitekten selbst Datenmodelle und beaufsichtigen die Modellierungsarbeit anderer. Außerdem erstellen sie Datenarchitekturpläne, Datenflussdiagramme und andere Artefakte. Weitere Aufgaben sind, Datenintegrationsprozesse zu skizzieren und die Entwicklung von Datendefinitionen, Geschäftsglossaren und Datenkatalogen zu beaufsichtigen. In einigen Unternehmen sind Datenarchitekten auch für die Entwicklung von Datenplattformen und die Bewertung und Auswahl von Technologien zuständig.
Zu den weiteren Fachleuten, die häufig am Datenarchitekturprozess beteiligt sind, gehören:
- Datenmodellierer. Sie arbeiten auch mit Geschäftsanwendern zusammen, um den Datenbedarf zu ermitteln und Geschäftsprozesse zu überprüfen. Anschließend verwenden sie die gesammelten Informationen, um Datenmodelle zu erstellen.
- Entwickler für die Datenintegration. Sobald die Architektur implementiert ist, sind sie mit der Erstellung von ETL- und ELT-Aufträgen zur Integration von Datensätzen betraut.
- Dateningenieure. Sie erstellen Pipelines, um Daten an Datenwissenschaftler und andere Analysten weiterzuleiten. Außerdem unterstützen sie die Data-Science-Teams bei der Datenaufbereitung.
Erfahren Sie mehr über Big Data
-
![]()
ESG-Reporting in SAP: Datenmodell, Governance und Audit
Von: Thomas Joos
-
![]()
Wie sich die KI-Integration in Unternehmen entwickelt
Von: Malte Jeschke
-
![]()
Entitätsbeziehungsdiagramm (Entity Relationship Diagram, ERD)
Von: Katie Terrell Hanna
-
![]()
Was Datenmodellierung und Datenarchitekturen unterscheidet
Von: David Loshin



