Datenmodellierung
Was ist Datenmodellierung?
Bei der Datenmodellierung wird ein vereinfachtes Diagramm eines Softwaresystems und der darin enthaltenen Datenelemente erstellt, wobei Text und Symbole zur Darstellung der Daten und des Datenflusses verwendet werden. Datenmodelle dienen als Blaupause für den Entwurf einer neuen Datenbank oder für die Umgestaltung einer bestehenden Anwendung. Insgesamt hilft Datenmodellierung einem Unternehmen dabei, seine Daten effektiv zu nutzen, um den geschäftlichen Informationsbedarf zu decken.
Ein Datenmodell kann man sich als Flussdiagramm vorstellen, das Datenentitäten, ihre Attribute und die Beziehungen zwischen den Einheiten veranschaulicht. Es ermöglicht Datenmanagement- und Analyseteams, Datenanforderungen für Anwendungen zu dokumentieren und Fehler in Entwicklungsplänen zu erkennen, bevor Code geschrieben wird.
Alternativ können Datenmodelle auch durch Reverse Engineering erstellt werden, bei dem man das Modell aus bestehenden Systemen extrahiert. Dies geschieht, um die Struktur von relationalen Datenbanken zu dokumentieren, die ohne vorherige Datenmodellierung ad hoc erstellt wurden, und um Schemata für Rohdatensätze zu definieren, die in Data Lakes oder NoSQL-Datenbanken gespeichert sind, um bestimmte Analyseanwendungen zu unterstützen.
Warum werden Daten modelliert?
Die Datenmodellierung ist eine Kerndisziplin des Datenmanagements. Durch die visuelle Darstellung von Datensätzen und deren Geschäftskontext unterstützt es dabei, den Informationsbedarf für verschiedene Geschäftsprozesse zu ermitteln. Anschließend werden die Merkmale der Datenelemente spezifiziert, die in Anwendungen und in den Datenbank- oder Dateisystemstrukturen enthalten sind, die zur Verarbeitung, Speicherung und Verwaltung der Daten verwendet werden.
Datenmodellierung kann auch dazu beitragen, gemeinsame Datendefinitionen und interne Datenstandards festzulegen, oft in Verbindung mit Data-Governance-Programmen. Darüber hinaus spielt sie eine wichtige Rolle bei Datenarchitekturprozessen, die Datenbestände dokumentieren, abbilden, wie sich Daten durch IT-Systeme bewegen, und ein konzeptionelles Datenmanagement-Framework schaffen. Datenmodelle sind neben Datenflussdiagrammen, Architekturentwürfen, einem einheitlichen Datenvokabular und anderen Artefakten eine wichtige Komponente der Datenarchitektur.
Traditionell wurden Datenmodelle von Datenmodellierern, Datenarchitekten und anderen Datenmanagementexperten unter Mitwirkung von Geschäftsanalysten, Führungskräften und Benutzern erstellt. Doch Datenmodellierung ist heute auch eine wichtige Fähigkeit für Data Scientists und Analysten, die an der Entwicklung von Business-Intelligence-Anwendungen und komplexeren Data-Science- und Advanced-Analytics-Anwendungen beteiligt sind.
Was sind die verschiedenen Datenmodelltypen?
Datenmodellierer verwenden drei Arten von Modellen, um Geschäftskonzepte und Arbeitsabläufe, relevante Datenentitäten und deren Attribute und Beziehungen sowie technische Strukturen für die Verwaltung der Daten getrennt darzustellen. Die Modelle werden normalerweise nach und nach erstellt, wenn Unternehmen neue Anwendungen und Datenbanken planen.
Dies sind die verschiedenen Arten von Datenmodellen:
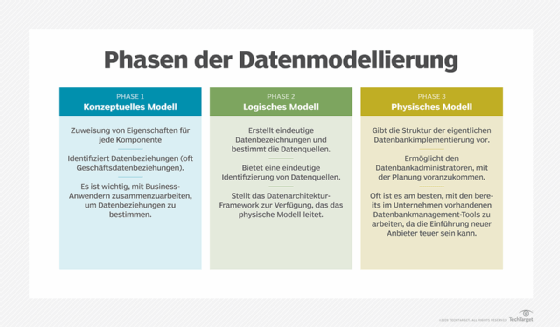
Konzeptuelles Datenmodell. Hierbei handelt es sich um eine übergeordnete Visualisierung der Geschäfts- oder Analyseprozesse, die ein System unterstützt. Es zeigt auf, welche Arten von Daten benötigt werden, wie verschiedene Geschäftseinheiten miteinander in Beziehung stehen und welche Geschäftsregeln damit verbunden sind. Die Zielgruppe für konzeptionelle Datenmodelle sind in erster Linie Führungskräfte, damit sie sich ein Bild davon machen können, wie ein System funktioniert, und um sicherzustellen, dass es den geschäftlichen Anforderungen entspricht. Konzeptuelle Modelle sind nicht an bestimmte Datenbank- oder Anwendungstechnologien gebunden.
Logisches Datenmodell. Sobald ein konzeptionelles Datenmodell fertiggestellt ist, kann es zur Erstellung eines weniger abstrakten logischen Modells verwendet werden. Logische Datenmodelle zeigen, wie Datenentitäten miteinander in Beziehung stehen, und beschreiben die Daten aus einer technischen Perspektive. Sie definieren zum Beispiel Datenstrukturen und liefern Details zu Attributen, Schlüsseln, Datentypen und anderen Merkmalen. Die technische Seite eines Unternehmens verwendet logische Modelle, um die erforderlichen Anwendungs- und Datenbankentwürfe zu verstehen. Wie konzeptionelle Modelle sind sie jedoch nicht an eine bestimmte Technologieplattform gebunden.
Physisches Datenmodell. Ein logisches Modell dient als Grundlage für die Erstellung eines physischen Datenmodells. Physische Modelle sind spezifisch für das Datenbankmanagementsystem (DBMS) oder die Anwendungssoftware, die implementiert werden soll. Sie definieren die Strukturen, die die Datenbank oder ein Dateisystem zur Speicherung und Verwaltung der Daten verwenden wird. Dazu gehören Tabellen, Spalten, Felder, Indizes, Constraints, Trigger und andere DBMS-Elemente. Datenbankdesigner verwenden physische Datenmodelle, um Entwürfe zu erstellen und Schemata für Datenbanken zu generieren.
Welche Datenmodellierungstechniken gibt es?
Die Datenmodellierung kam in den 1960er Jahren auf, als Datenbanken auf Großrechnern und später auf Minicomputern immer häufiger eingesetzt wurden. Sie ermöglichte es Unternehmen, Konsistenz, Wiederholbarkeit und disziplinierte Entwicklung in die Datenverarbeitung und -verwaltung zu bringen. Das ist auch heute noch der Fall, aber die Techniken zur Erstellung von Datenmodellen haben sich mit der Entwicklung neuer Arten von Datenbanken und Computersystemen weiterentwickelt.
Im Folgenden werden die im Laufe der Jahre am weitesten verbreiteten Datenmodellierungsansätze vorgestellt, darunter auch einige, die inzwischen weitgehend durch neuere Techniken verdrängt wurden.
1. Hierarchische Datenmodellierung
Hierarchische Datenmodelle organisieren Daten in einer baumartigen Anordnung von übergeordneten und untergeordneten Datensätzen. Ein Child-Datensatz kann nur einen Parent-Datensatz haben, so dass es sich um eine One-to-many-Modellierungsmethode handelt. Der hierarchische Ansatz hat seinen Ursprung in Mainframe-Datenbanken – IBMs Information Management System (IMS) ist das bekannteste Beispiel. Obwohl hierarchische Datenmodelle ab den 1980er Jahren größtenteils von relationalen Modellen abgelöst wurden, ist IMS immer noch verfügbar und wird von vielen Unternehmen verwendet. Eine ähnliche hierarchische Methode wird heute auch in XML verwendet, das offiziell als Extensible Markup Language bekannt ist.
2. Netzwerkdatenmodellierung
Dies war ebenfalls eine beliebte Datenmodellierungsoption in Mainframe-Datenbanken, die heute nicht mehr so häufig verwendet wird. Netzwerkdatenmodelle erweiterten die hierarchischen Modelle, indem sie es ermöglichten, untergeordnete Datensätze mit mehreren übergeordneten Datensätzen zu verbinden. Die Conference on Data Systems Languages, eine heute nicht mehr existierende technische Standardisierungsgruppe, die gemeinhin CODASYL genannt wird, nahm 1969 eine Spezifikation für ein Netzwerkdatenmodell an. Aus diesem Grund wird die Netzwerktechnik oft als CODASYL-Modell bezeichnet.
3. Relationale Datenmodellierung
Das relationale Datenmodell wurde als flexiblere Alternative zum hierarchischen und zum Netzwerkdatenmodell entwickelt. Das relationale Modell wurde erstmals 1970 in einem technischen Papier des IBM-Forschers Edgar F. Codd beschrieben und bildet die Beziehungen zwischen Datenelementen ab, die in verschiedenen Tabellen gespeichert sind, die Sätze von Zeilen und Spalten enthalten. Die relationale Modellierung bildete die Grundlage für die Entwicklung relationaler Datenbanken, und ihre weit verbreitete Verwendung machte sie bis Mitte der 1990er Jahre zur vorherrschenden Datenmodellierungstechnik.
4. Entity-Relationship-Datenmodellierung
Eine Variante des relationalen Modells, die auch bei anderen Datenbanktypen verwendet werden kann, sind Entity-Relationship-Modelle (ER-Modelle), die Entitäten, ihre Attribute und die Beziehungen zwischen verschiedenen Entitäten visuell abbilden. Die Attribute einer Entität für Mitarbeiterdaten könnten beispielsweise den Nachnamen, den Vornamen, die Beschäftigungsjahre und andere relevante Daten umfassen. ER-Modelle bieten einen effizienten Ansatz für Datenerfassungs- und -aktualisierungsprozesse und eignen sich daher besonders für Anwendungen zur Transaktionsverarbeitung.
5. Dimensionale Datenmodellierung
Dimensionale Datenmodelle werden hauptsächlich in Data Warehouses und Data Marts verwendet, die Business-Intelligence-Anwendungen unterstützen. Sie bestehen aus Faktentabellen, die Daten über Transaktionen oder andere Ereignisse enthalten, und Dimensionstabellen, die Attribute der Entitäten in den Faktentabellen auflisten. Eine Faktentabelle kann zum Beispiel die Produktkäufe von Kunden auflisten, während die damit verbundenen Dimensionstabellen Daten über die Produkte und Kunden enthalten. Bemerkenswerte Arten von Dimensionsmodellen sind das Sternschema, das eine Faktentabelle mit verschiedenen Dimensionstabellen verbindet, und das Schneeflockenschema, das mehrere Ebenen von Dimensionstabellen enthält.
6. Objektorientierte Datenmodellierung
Mit der Weiterentwicklung der objektorientierten Programmierung in den 1990er Jahren und der Entwicklung von Objektdatenbanken durch Softwareanbieter kam auch die objektorientierte Datenmodellierung auf. Der objektorientierte Ansatz ähnelt der ER-Methode in Bezug auf die Darstellung von Daten, Attributen und Beziehungen, abstrahiert aber Entitäten zu Objekten. Verschiedene Objekte, die dieselben Attribute und Verhaltensweisen aufweisen, können in Klassen gruppiert werden, und neue Klassen können die Attribute und Verhaltensweisen der vorhandenen Klassen übernehmen. Objektdatenbanken sind jedoch nach wie vor eine Nischentechnologie für bestimmte Anwendungen, was die Verwendung der objektorientierten Modellierung eingeschränkt hat.
7. Modellierung von Graphdaten
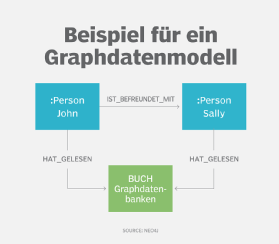
Das Graphdatenmodell ist ein modernerer Ableger von Netzwerk- und hierarchischen Modellen. Es wird häufig in Verbindung mit Graphdatenbanken verwendet, um Datensätze zu beschreiben, die komplexe Beziehungen enthalten. Die Modellierung von Graphdaten ist beispielsweise ein beliebter Ansatz in sozialen Netzwerken, Empfehlungsmaschinen und Anwendungen zur Betrugserkennung. Ein gängiger Typ sind Eigenschaftsgraphenmodelle, bei denen Knoten, die Datenentitäten darstellen und deren Eigenschaften dokumentieren, durch Beziehungen, auch Kanten oder Links genannt, verbunden sind, die festlegen, wie die verschiedenen Knoten miteinander in Beziehung stehen.
Wie sieht der Prozess der Datenmodellierung aus?
Idealerweise werden konzeptionelle, logische und physische Datenmodelle in einem sequenziellen Prozess erstellt, an dem Mitglieder des Datenmanagementteams und Geschäftsanwender beteiligt sind. Vor allem in der Phase der konzeptionellen und logischen Modellierung ist der Input von Geschäftsführern und Mitarbeitern wichtig. Andernfalls kann es passieren, dass die Datenmodelle den geschäftlichen Kontext der Daten nicht vollständig erfassen oder den Informationsbedarf des Unternehmens nicht erfüllen.
In der Regel beginnt ein Datenmodellierer oder Datenarchitekt ein Modellierungsprojekt mit der Befragung von Geschäftsinteressenten, um Anforderungen und Details über Geschäftsprozesse zu sammeln. Geschäftsanalysten können auch bei der Entwicklung des konzeptionellen und logischen Modells helfen. Am Ende des Projekts wird das physische Datenmodell verwendet, um den Datenbankentwicklern spezifische technische Anforderungen zu übermitteln.
Peter Aiken, ein Berater für Datenmanagement und außerordentlicher Professor für Informationssysteme an der Virginia Commonwealth University, hat in seinem Dataversity-Webinar 2019 folgende sechs Schritte für den Entwurf eines Datenmodells aufgeführt:
- Identifizieren Sie die Geschäftseinheiten, die in dem Datensatz repräsentiert werden.
- Identifizieren Sie Schlüsseleigenschaften für jede Entität, um sie voneinander zu unterscheiden.
- Erstellen Sie einen Entwurf für ein Entity-Relationship-Modell, um zu zeigen, wie die Entitäten miteinander verbunden sind.
- Identifizieren Sie die Datenattribute, die in das Modell aufgenommen werden müssen.
- Ordnen Sie die Attribute den Entitäten zu, um die geschäftliche Bedeutung der Daten zu verdeutlichen.
- Stellen Sie das Datenmodell fertig und validieren Sie seine Genauigkeit.
Selbst danach ist der Prozess in der Regel noch nicht abgeschlossen: Datenmodelle müssen oft aktualisiert und überarbeitet werden, wenn sich die Datenbestände eines Unternehmens und die geschäftlichen Anforderungen ändern.

Was sind Vorteile und Herausforderungen der Datenmodellierung?
Gut konzipierte Datenmodelle helfen einem Unternehmen, eine Datenstrategie zu entwickeln und zu implementieren, die alle Vorteile seiner Daten ausschöpft. Eine effektive Datenmodellierung trägt auch dazu bei, dass die einzelnen Datenbanken und Anwendungen die richtigen Daten enthalten und so konzipiert sind, dass sie die geschäftlichen Anforderungen an die Datenverarbeitung und -verwaltung erfüllen.
Weitere Vorteile der Datenmodellierung sind unter anderem:
- Interne Einigung auf Datendefinitionen und -standards. Die Datenmodellierung unterstützt die Bemühungen um eine unternehmensweite Standardisierung von Datendefinitionen, Terminologie, Konzepten und Formaten.
- Stärkere Beteiligung der Geschäftsanwender am Datenmanagement. Da die Datenmodellierung den Input des Unternehmens erfordert, fördert sie die Zusammenarbeit zwischen den Datenmanagementteams und den Unternehmensbeteiligten, was im Idealfall zu besseren Systemen führt.
- Effizienteres Datenbankdesign zu geringeren Kosten. Die Datenmodellierung gibt den Datenbankentwicklern einen detaillierten Entwurf an die Hand, mit dem sie arbeiten können, und verringert so das Risiko von Fehlentwicklungen, die spätere Überarbeitungen erforderlich machen.
- Bessere Nutzung der verfügbaren Datenbestände. Letztendlich ermöglicht eine gute Datenmodellierung den Unternehmen eine produktivere Nutzung ihrer Daten, was zu einer besseren Unternehmensleistung, neuen Geschäftsmöglichkeiten und Wettbewerbsvorteilen gegenüber anderen Unternehmen führen kann.
Die Datenmodellierung ist jedoch ein komplizierter Prozess, dessen erfolgreiche Durchführung schwierig sein kann. Im Folgenden sind einige der häufigsten Herausforderungen aufgeführt, die Datenmodellierungsprojekte aus dem Ruder laufen lassen:
- Mangelndes organisatorisches Engagement und mangelnde Akzeptanz im Unternehmen. Wenn die Unternehmens- und Geschäftsleitung nicht von der Notwendigkeit der Datenmodellierung überzeugt ist, ist es schwierig, das erforderliche Maß an geschäftlicher Beteiligung zu erreichen. Das bedeutet, dass Datenmanagementteams sich im Vorfeld die Unterstützung der Geschäftsleitung sichern müssen.
- Mangelndes Verständnis der Geschäftsanwender. Selbst wenn die Unternehmensbeteiligten komplett hinter dem Projekt stehen, ist die Datenmodellierung ein abstrakter Prozess, der für die Mitarbeiter oft schwer zu verstehen ist. Um dies zu vermeiden, sollten konzeptionelle und logische Datenmodelle auf geschäftlicher Terminologie und Konzepten basieren.
- Komplexität der Modellierung und schleichende Ausweitung des Umfangs. Datenmodelle sind oft groß und komplex, und Modellierungsprojekte können unhandlich werden, wenn Teams immer wieder neue Iterationen erstellen, ohne die Entwürfe abzuschließen. Es ist wichtig, Prioritäten zu setzen und sich an einen realisierbaren Projektumfang zu halten.
- Undefinierte oder unklare Geschäftsanforderungen. Vor allem bei neuen Anwendungen kann es vorkommen, dass die Geschäftsseite noch nicht über einen vollständig ausgearbeiteten Informationsbedarf verfügt. Datenmodellierer müssen oft eine Reihe von Fragen stellen, um Anforderungen zu sammeln oder zu klären und die erforderlichen Daten zu identifizieren.
Erfahren Sie mehr über Datenverwaltung
-
![]()
Harmonisierung verteilter Daten mit SAP One Domain Model
Von: Thomas Joos
-
![]()
SAP ABAP Cloud: Architektur, Programmiermodelle und Anwendung
Von: Thomas Joos
-
![]()
ESG-Reporting in SAP: Datenmodell, Governance und Audit
Von: Thomas Joos
-
![]()
Mit dem SAP Cloud Application Programming Model entwickeln
Von: Thomas Joos



