
sdecoret - stock.adobe.com
Techniken und Konzepte der Datenmodellierung für Unternehmen
Es gibt verschiedene Datenmodelle und -techniken, die Datenmanagementteams zur Verfügung stehen, um die Umwandlung von Daten in wertvolle Geschäftsinformationen zu unterstützen.

Ein gut durchdachtes Datenmodell ist der Eckpfeiler operativer Systeme sowie von Business-Intelligence- und Analyseanwendungen, die durch die Umwandlung von Unternehmensdaten in nützliche Informationen einen geschäftlichen Mehrwert schaffen.
Informationen sind Daten in einem Kontext, und ein Datenmodell ist die Blaupause für diesen Kontext. Daten haben oft viele Kontexte, die auf ihrer Verwendung in verschiedenen Geschäftsprozessen und Analyseanwendungen basieren. Daher benötigt ein Unternehmen viele Datenmodelle und nicht nur eines, welches alle Anwendungsfälle abdeckt. Datenmanagementteams stehen verschiedene Datenmodellierungstechniken zur Verfügung.
Was sind Datenmodelle?
Ein Datenmodell ist eine Spezifikation von Datenstrukturen und Geschäftsregeln. Es dient der visuellen Darstellung von Daten und veranschaulicht, wie verschiedene Datenelemente zueinander in Beziehung stehen. Es beantwortet auch das wer, was, wo und warum der Datenelemente. Bei einer Einzelhandelstransaktion liefert das Datenmodell beispielsweise Angaben darüber, wer den Kauf getätigt hat, was gekauft wurde und wann. Das Modell kann auch zusätzliche Daten über Kunden, Produkt, Geschäft, Verkäufer, Hersteller, Lieferkette und vieles mehr enthalten.
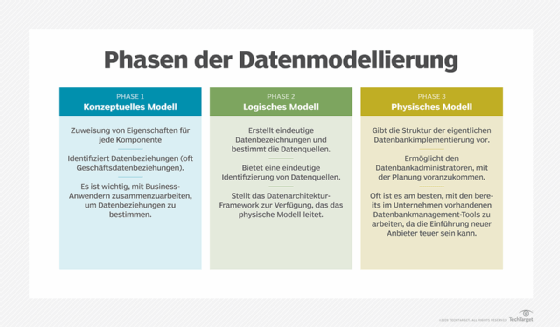
Es ist am besten, ein Datenmodell in einem Top-Down-Ansatz aufzubauen, von den übergeordneten Geschäftsanforderungen bis hin zu einer detaillierten Datenbank- oder Dateistruktur. Bei diesem Ansatz werden die folgenden drei Arten von Datenmodellen verwendet:
- Konzeptionelles Datenmodell. Ein konzeptionelles Modell legt fest, welche Daten in Geschäftsprozessen oder in Analyse- und Berichtsanwendungen benötigt werden, zusammen mit den zugehörigen Geschäftsregeln und Konzepten. Es definiert nicht den Datenverarbeitungsfluss oder die physischen Eigenschaften.
- Logisches Datenmodell. In diesem Modell werden die Datenstrukturen, wie zum Beispiel Tabellen und Spalten, und die Beziehungen zwischen den Strukturen, wie zum Beispiel Fremdschlüssel, festgelegt. Es werden spezifische Entitäten und Attribute definiert. Ein logisches Datenmodell ist unabhängig von einer bestimmten Datenbank- oder Dateistruktur. Es kann in einer Vielzahl von Datenbanken implementiert werden, darunter relationale, spaltenbasierte, multidimensionale und NoSQL-Systeme – oder sogar in einer XML- oder JSON-Datei.
- Physisches Datenmodell. Ein physisches Modell definiert die spezifischen Datenbank- oder Dateistrukturen, die in einem System verwendet werden sollen. Bei einer Datenbank umfasst dies Elemente wie Tabellen, Spalten, Datentypen, Primär- und Fremdschlüssel, Constraints, Indizes, Trigger, Tablespaces und Partitionen.
Allgemeine Techniken und Konzepte der Datenmodellierung
Um die heute gängigen Datenmodellierungstechniken besser zu verstehen, ist es hilfreich, einen kurzen historischen Überblick über die Entwicklung der Modellierung zu geben. Von den sieben hier beschriebenen Datenmodellen wurden die ersten vier Typen in den Anfängen der Datenbanken verwendet und sind auch heute noch möglich, gefolgt von den drei heute am häufigsten verwendeten Modellen.
1. Hierarchisches Datenmodell
Die Daten werden in einer baumartigen Struktur mit übergeordneten und untergeordneten Datensätzen gespeichert, die eine Sammlung von Datenfeldern umfassen. Ein übergeordneter Datensatz kann einen oder mehrere untergeordnete Datensätze haben, aber ein untergeordneter Datensatz kann nur einen übergeordneten Datensatz haben. Das hierarchische Modell besteht auch aus Verknüpfungen, das heißt Verbindungen zwischen Datensätzen, und aus Typen, die die Art der in einem Feld enthaltenen Daten angeben. Es hat seinen Ursprung in Mainframe-Datenbanken in den 1960er Jahren.
2. Netzwerkdatenmodell
Dieses Modell erweitert das hierarchische Modell, indem es zulässt, dass ein untergeordneter Datensatz einen oder mehrere übergeordnete Datensätze hat. Eine Standardspezifikation des Netzwerkmodells wurde 1969 von der Conference on Data Systems Languages, einer heute nicht mehr existierenden Gruppe, besser bekannt als CODASYL, angenommen. Aus diesem Grund wird es auch als CODASYL-Modell bezeichnet. Die Netzwerktechnik ist der Vorläufer einer Graphendatenstruktur, bei der ein Datenobjekt in einem Knoten und die Beziehung zwischen zwei Knoten als Kante dargestellt wird. Obwohl sie auf Großrechnern beliebt war, wurde sie nach deren Aufkommen in den späten 1970er Jahren weitgehend durch relationale Datenbanken ersetzt.
3. Relationales Datenmodell
In diesem Modell werden die Daten in Tabellen und Spalten gespeichert und die Beziehungen zwischen den Datenelementen in diesen Tabellen und Spalten werden identifiziert. Es umfasst auch Datenbankmanagementfunktionen wie Constraints und Trigger. Der relationale Ansatz wurde in den 1980er Jahren zur vorherrschenden Datenmodellierungstechnik. Das Entity-Relationship-Modell und das dimensionale Datenmodell, die derzeit am weitesten verbreiteten Techniken, sind Variationen des relationalen Modells, können aber auch mit nicht-relationalen Datenbanken verwendet werden.
4. Objektorientiertes Datenmodell
Dieses Modell kombiniert Aspekte der objektorientierten Programmierung und des relationalen Datenmodells. Ein Objekt stellt Daten und ihre Beziehungen in einer einzigen Struktur dar, zusammen mit Attributen, die die Eigenschaften des Objekts spezifizieren, und Methoden, die sein Verhalten definieren. Zwischen den Objekten können mehrere Beziehungen bestehen. Das objektorientierte Modell besteht außerdem aus folgenden Elementen
- Klassen, das heißt Sammlungen ähnlicher Objekte mit gemeinsamen Attributen und Verhaltensweisen
- Vererbung, die es einer neuen Klasse ermöglicht, die Attribute und Verhaltensweisen eines bestehenden Objekts zu übernehmen
Es wurde für die Verwendung mit Objektdatenbanken entwickelt, die in den späten 1980er und frühen 1990er Jahren als Alternative zu relationaler Software aufkamen. Sie konnten jedoch die Vorherrschaft der relationalen Technologie nicht brechen.
5. Entity-Relationship-Datenmodell
Dieses Modell hat sich für relationale Datenbanken in Unternehmensanwendungen, insbesondere für die Transaktionsverarbeitung, weitgehend durchgesetzt. Mit minimaler Redundanz und klar definierten Beziehungen ist es effizient für Datenerfassungs- und Aktualisierungsprozesse. Das Modell besteht aus
- Entitäten, die Personen, Orte, Dinge, Ereignisse oder Konzepte darstellen, zu denen Daten verarbeitet und als Tabellen gespeichert werden
- Attributen, das heißt bestimmten Merkmalen oder Eigenschaften einer Entität, die als Daten in Spalten gepflegt und gespeichert werden
- Beziehungen, die logische Verknüpfungen zwischen zwei Entitäten definieren, die Geschäftsregeln oder Beschränkungen darstellen
Das Design des Modells wird durch den Grad der Normalisierung charakterisiert, das heißt den Grad der Redundanz, der von Edgar F. Codd, dem Erfinder des relationalen Modells, festgelegt wurde. Die gängigsten Formen sind die dritte Normalform (3NF) und die Boyce-Codd-Normalform, eine etwas stärkere Version, die auch als 3.5NF bekannt ist.
6. Dimensionales Datenmodell
Wie das Entity-Relationship-Modell umfasst auch das dimensionale Modell Attribute und Beziehungen. Es weist jedoch zwei Kernkomponenten auf:
- Fakten, bei denen es sich um Messungen einer Aktivität handelt, zum Beispiel eines Geschäftsprozesses oder eines Ereignisses, an dem eine Person oder ein Gerät beteiligt ist. Fakten sind im Allgemeinen numerisch, und Faktentabellen sind normalisiert und enthalten wenig Redundanz.
- Dimensionen, das heißt Tabellen, die den geschäftlichen Kontext der Fakten enthalten, um die Attribute wer, was, wo und warum zu definieren. Dimensionen sind in der Regel beschreibend und nicht numerisch.
Das Dimensionsmodell hat sich für Business-Intelligence- und Analyseanwendungen weitgehend durchgesetzt. Es wird oft als Sternschema bezeichnet – ein Fakt, der von mehreren anderen Fakten umgeben und mit diesen verbunden ist, obwohl dies die Modellstruktur zu stark vereinfacht. Die meisten dimensionalen Modelle haben viele Faktentabellen, welche mit vielen Dimensionen verknüpft sind, die als conformed bezeichnet werden, wenn sie von mehr als einer Faktentabelle gemeinsam genutzt werden.
7. Graphdatenmodell
Die Modellierung von Graphdaten hat ihre Wurzeln in der Technik der Netzwerkmodellierung. Sie wird in erster Linie zur Modellierung komplexer Beziehungen in Graphdatenbanken verwendet, kann aber auch für andere NoSQL-Datenbanken wie Key-Value- und Dokumenttypen eingesetzt werden.
Es gibt zwei grundlegende Elemente in einem Graphdatenmodell.
- Knoten, die Entitäten mit einer eindeutigen Identität darstellen. Jede Instanz einer Entität ist ein anderer Knoten, der mit einer Zeile in einer Tabelle im relationalen Modell vergleichbar ist.
- Kanten, auch als Links oder Beziehungen bezeichnet. Sie verbinden Knoten und definieren, wie die Knoten miteinander in Beziehung stehen. Alle Knoten müssen mindestens eine Kante haben, die mit ihnen verbunden ist. Kanten können ungerichtet sein, mit einer bidirektionalen Beziehung zwischen Knoten, oder gerichtet, wobei die Beziehung in eine bestimmte Richtung geht.
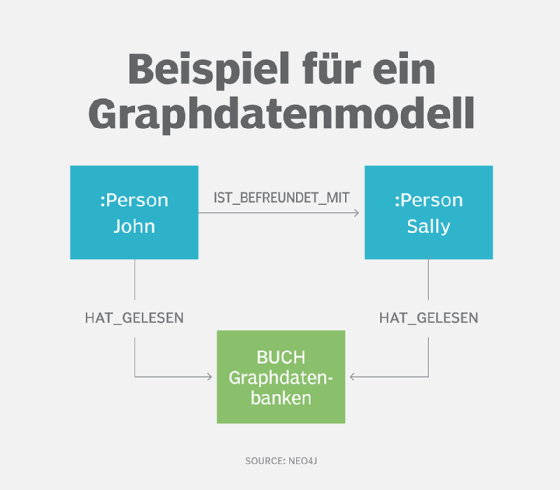
Eines der beliebtesten Graphenformate ist das Property-Graph-Modell. In diesem Modell werden die Eigenschaften von Knoten oder Kanten durch Name-Wert-Paare dargestellt. Mit Unterstützung von Bezeichnungen können Knoten auch gruppiert werden, um die Abfrage zu erleichtern. Jeder Knoten mit der gleichen Bezeichnung wird zu einem Mitglied der Gruppe, und den Knoten können so viele Bezeichnungen zugewiesen werden, wie sie passen.
Bewährte Verfahren bei der Datenmodellierung
Zu den Best Practices für die Datenmodellierung gehören acht Schritte, die ein Unternehmen dabei unterstützen, den gewünschten Geschäftswert aus seinen Daten abzuleiten.
Betrachten Sie das Datenmodell als Blueprint beziehungsweise Spezifikation. Datenmodelle sollten ein nützlicher Leitfaden für die Personen sein, die das Datenbankschema entwerfen, und für diejenigen, die die Daten erstellen, aktualisieren, verwalten, kontrollieren und analysieren. Verfolgen Sie den Weg vom konzeptionellen über das logische bis hin zum physischen Modell, wenn ein neues Datenmodell in einer neuen Umgebung erstellt wird, in der noch keine Modelle oder physischen Schema existieren.
Sammeln Sie im Vorfeld sowohl Geschäfts- als auch Datenanforderungen. Holen Sie den Input der Geschäftsinteressenten ein, um konzeptionelle und logische Datenmodelle auf der Grundlage der Geschäftsanforderungen zu entwerfen. Sammeln Sie auch Datenanforderungen von Geschäftsanalysten und anderen Fachleuten, um detailliertere logische und physische Modelle aus den Geschäftsanforderungen und übergeordneten Modellen abzuleiten. Die Datenmodelle müssen sich mit dem Unternehmen und der Technologie weiterentwickeln.
Entwickeln Sie Modelle iterativ und inkrementell. Ein Datenmodell kann Hunderte oder Tausende von Entitäten und Beziehungen enthalten. Es ist äußerst schwierig, alles auf einmal zu entwerfen. Am besten ist es, das Modell in die in einem konzeptionellen Datenmodell festgelegten Themenbereiche zu unterteilen und diese Themenbereiche nacheinander zu entwerfen. Danach sollten Sie sich mit den Verbindungen zwischen diesen Bereichen befassen.
Verwenden Sie ein Datenmodellierungswerkzeug, um die Datenmodelle zu entwerfen und zu pflegen. Datenmodellierungs-Tools bieten visuelle Modelle, eine Datenstrukturdokumentation, ein Datenwörterbuch und den Code für die Datendefinitionssprache, der für die Erstellung physischer Datenmodelle erforderlich ist. Außerdem können sie häufig Metadaten mit Datenbank-, Datenintegrations-, BI-, Datenkatalog- und Data Governance Tools austauschen. Und wenn es keine Datenmodelle in bestehenden Datenbanken gibt, können Sie die Reverse-Engineering-Funktionen eines Tools nutzen, um den Prozess in Gang zu bringen.
Bestimmen Sie die in den Datenmodellen benötigte Granularitätsebene. Im Allgemeinen sollten Sie die niedrigste Datengranularität beibehalten, das heißt die detailliertesten Daten, die erfasst werden. Aggregieren Sie Daten nur bei Bedarf und nur als abgeleitetes Datenmodell, während Sie die Daten mit der niedrigsten Granularität im primären Modell beibehalten.
Vermeiden Sie eine umfassende Denormalisierung von Datenbanken. Die Denormalisierung einer Datenbank fügt redundante Daten hinzu, um die Abfrageleistung zu optimieren. Dabei wird jedoch eine bestimmte Beziehung zwischen Entitäten vorausgesetzt, die den Nutzen für verschiedene Analyseanwendungen einschränken kann. Wie bei der Aggregation sollte die Denormalisierung am besten in einem abgeleiteten Datenmodell angewandt werden, zum Beispiel in einem Schema für eine BI-Anwendung und nicht in einem Data Warehouse.
Verwenden Sie Datenmodelle als Kommunikationsmittel mit Geschäftsanwendern. Ein 10.000-Tabellen-Entity-Relationship-Modell kann jeden Kopf zum Qualmen bringen. Aber ein Datenmodell oder ein Teil davon, das sich auf einen bestimmten Geschäftsprozess oder eine Datenanalyse konzentriert, bietet eine gute Gelegenheit, das Schema mit den Geschäftsanwendern zu diskutieren und zu überprüfen. Die Annahme, dass Geschäftsanwender ein Datenmodell nicht verstehen könnten, ist eine fatale Annahme bei Modellierungsbemühungen.
Verwalten Sie Datenmodelle genauso wie jeden anderen Anwendungscode. Unternehmensanwendungen, Datenintegrationsprozesse und Analyseanwendungen verwenden alle Datenstrukturen, unabhängig davon, ob sie entworfen und dokumentiert sind oder nicht. Anstatt zuzulassen, dass sich eine ungeplante zufällige Architektur entwickelt und jede Chance auf einen soliden ROI aus ihren Daten zunichte macht, müssen Unternehmen die Datenmodellierung ernsthaft angehen.






