
Miha Creative - stock.adobe.com
Apache Superset: interaktive Dashboards professionell nutzen
Mit Apache Superset lassen sich komplexe Datenquellen einbinden, visuell auswerten und in dynamischen BI-Dashboards mit umfassenden Analyseoptionen präsentieren.

Apache Superset ist eine skalierbare Visualisierungs- und Analyseebene für SQL-basierte Dateninfrastrukturen. Die Plattform greift auf bestehende Data-Warehouse- und Datenbank-Engines zu, ohne eine zusätzliche Verarbeitungsschicht einzufügen, und nutzt deren native Leistungsfähigkeit für komplexe Abfragen.
Die Kombination aus Metadaten-Backend, Caching Layer, asynchroner Query-Verarbeitung und modular erweiterbarer Frontend-Architektur ergibt ein System, das sowohl für Ad-hoc-Analysen als auch für die Bereitstellung interaktiver Dashboards in produktiven Umgebungen optimiert ist.
Datenvisualisierung mit Apache Superset
Apache Superset ist eine Open-Source-Business-Intelligence-Plattform (BI), die für die visuelle Exploration und Analyse strukturierter Daten spezialisiert ist. Sie ermöglicht die Erstellung interaktiver Dashboards und Charts, die auf eine Vielzahl von Datenquellen zugreifen können, ohne dass diese zuvor in eine separate Engine geladen werden müssen.
Der Kern der Anwendung basiert auf einer Python-Implementierung mit Flask als Webframework, einem React-basierten Frontend sowie einer integrierten API-Schicht. Diese Architektur erlaubt es, sowohl deklarative No-Code-Auswertungen als auch SQL-basierte Analysen in einer einheitlichen Oberfläche auszuführen.
Superset ist darauf ausgelegt, in bestehende Dateninfrastrukturen integriert zu werden, sodass es die Verarbeitung an das jeweilige Datenbanksystem delegiert und selbst nur als Visualisierungs- und Steuerungsschicht fungiert. Da die Anwendung Open Source ist, entfällt ein Vendor Lock-in, und Unternehmen können die Plattform an eigene Anforderungen anpassen oder erweitern.
Systemarchitektur und Komponenten
Eine vollständige Superset-Installation besteht aus mehreren Kern- und Zusatzkomponenten, die je nach Einsatzzweck skaliert und konfiguriert werden. Die Hauptapplikation verarbeitet Benutzeranfragen, kommuniziert mit angebundenen Datenquellen und liefert die Ergebnisse in visualisierter Form aus. Die Metadaten-Datenbank speichert zentrale Informationen wie Benutzerkonten, Rollen, Berechtigungen, Dashboard-Definitionen, Visualisierungskonfigurationen und Audit-Logs. In der Vorkonfiguration wird häufig SQLite verwendet, was jedoch für produktive Szenarien nicht empfohlen wird, da fehlende Parallelitäts- und Locking-Funktionen zu Engpässen führen können.
In der Praxis sind PostgreSQL oder MySQL als produktive Backends die Datenbank der Wahl. Ergänzend kann eine Caching-Schicht wie Redis implementiert werden, die sowohl Abfrageergebnisse speichert als auch als Message Broker zwischen der Hauptanwendung und den Celery Worker fungiert. Diese Worker übernehmen Aufgaben wie das Rendern von Dashboard-Thumbnails, das Versenden von E-Mail-Berichten, die Ausführung zeitgesteuerter Alerts oder die Verarbeitung asynchroner Abfragen. Für Hochverfügbarkeit lassen sich die einzelnen Komponenten hinter einem Load Balancer betreiben und in Kubernetes-Umgebungen orchestrieren.
Installation und Erstkonfiguration
Für einen schnellen Einstieg in eine Entwicklungs- oder Testumgebung empfiehlt sich Docker Compose – dies wird allerdings nur für Tests und Entwicklungen empfohlen. Dabei wird das offizielle Superset-Repository von GitHub geklont, auf die gewünschte Version geprüft und die Containerumgebung mit einem vordefinierten Compose File gestartet.
Nach dem Download der Images und der Initialisierung stehen Beispiel-Dashboards bereit, um die Funktionen zu testen. Der Standardzugang erfolgt mit dem Benutzer admin und dem Passwort admin. Im produktiven Betrieb werden die Container-Images in ein eigenes Deployment integriert, wobei Datenbankverbindungen, Caching-Backends, Worker-Prozesse und Sicherheitskonfigurationen vorab festgelegt werden.
Bei einer manuellen Installation auf einem Linux-Server wird Python 3.10 in einer virtuellen Umgebung benötigt, Superset per pip installiert, ein Administratorkonto angelegt und die Metadatenbank migriert. Abschließend können Beispieldaten geladen werden, um die Funktionsprüfung vorzunehmen, bevor die Instanz über eine IP-gebundene Ausführung auch extern erreichbar gemacht wird.
Anbindung von Datenquellen
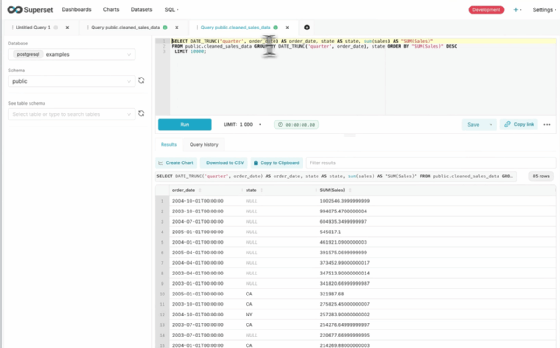
Superset unterstützt eine große Bandbreite an SQL-Datenbanken und Abfrage-Engines. Dazu zählen relationale Systeme wie PostgreSQL, MySQL, Oracle und Microsoft SQL Server, analytische Engines wie Trino, ClickHouse oder Apache Druid sowie Cloud-Datenbanken wie Snowflake, BigQuery, Amazon Redshift und Databricks. Auch Flat-File-Quellen wie CSV oder Google Sheets können eingebunden werden. Die Integration erfolgt über SQLAlchemy-Konnektoren, die eine DBAPI-Schnittstelle voraussetzen.
Einschränkungen bestehen in der grafischen Explore-Oberfläche, die pro Dataset nur auf eine Tabelle oder View zugreifen kann. Komplexe Joins über mehrere Tabellen werden daher entweder vorab in der Datenquelle modelliert oder direkt im SQL Lab ausgeführt. Views dienen dabei als logische Schicht, in der Joins, Unions und Transformationen definiert werden, um in Superset als eigenständiges Dataset genutzt zu werden. Die Leistung hängt dabei von der Performance der zugrunde liegenden Datenbank ab, da Superset keine eigene Query Engine betreibt.
Datasets und semantische Schicht
Datasets sind in Superset die Grundlage für jede Visualisierung. Physische Datasets basieren auf Tabellen oder Views in der angebundenen Datenbank, virtuelle Datasets auf gespeicherten SQL-Abfragen. In der semantischen Schicht lassen sich Metriken (zum Beispiel SUM, COUNT_DISTINCT) und berechnete Spalten definieren, die für mehrere Charts wiederverwendet werden können.
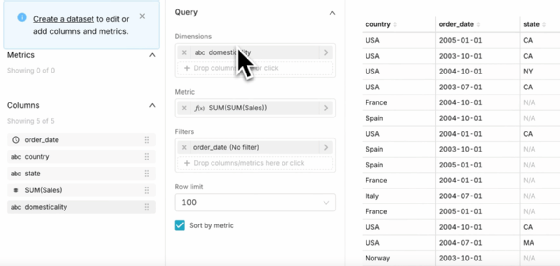
Dadurch entsteht eine konsistente Logik für Berechnungen und Kennzahlen über alle Dashboards hinweg. Änderungen am Quellschema, etwa neue Spalten oder geänderte Datentypen, können durch eine Synchronisationsfunktion in der Dataset-Verwaltung übernommen werden. Dort lassen sich Spalten mit Formatierungen, Zeitversatz (Hours Offset) oder Beschreibungstexten versehen. Für Zeitanalysen ist die Kennzeichnung einer temporalen Spalte erforderlich, die als Zeitachse für Diagramme dient.
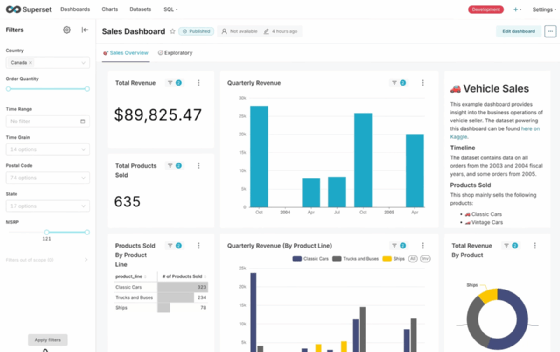
Erstellung von Visualisierungen
Superset bietet mehr als 40 vorinstallierte Visualisierungstypen, von klassischen Balken- und Liniendiagrammen über Karten mit Mapbox bis zu komplexen, interaktiven Ring- und Sunburst-Charts. Die Erstellung erfolgt entweder direkt aus einem Dataset im Explore-Interface oder aus einer SQL-Abfrage, die in ein neues Dataset umgewandelt wird.
Im Chart-Builder werden Dimensionen und Metriken per Drag-and-drop den Visualisierungsfeldern zugeordnet. Der Tab Data steuert die Abfrageparameter, Filter und Gruppierungen, der Tab Customize kontrolliert Layout, Farbschema, Achsentitel und Interaktionselemente. Erweiterte Funktionen wie Rolling Averages, kumulative Summen oder Zeitvergleiche werden über Advanced Analytics realisiert. Für geographische Visualisierungen ist ein Mapbox-API-Key notwendig, der in den Einstellungen hinterlegt wird.
Dashboards und interaktive Analyse
Ein Dashboard in Superset ist eine Sammlung aus Charts, Filtern und Layout-Elementen, die gemeinsam angezeigt und interaktiv gesteuert werden können. Layouts lassen sich per Drag-and-drop anpassen, Markdown-Elemente erlauben die Integration von beschreibenden Texten oder Links. Filter-Widgets können so konfiguriert werden, dass sie global für alle Charts gelten oder nur für ausgewählte Elemente.
Cross-Filtering ermöglicht es, durch Klick auf ein Chart-Element automatisch Filter auf andere Charts im Dashboard anzuwenden. Drill-to-Detail öffnet eine tabellarische Ansicht der zugrunde liegenden Daten, Drill-by erlaubt das Wechseln der Granularität, zum Beispiel von Bundesland zu Stadt. Zeitgesteuerte Aktualisierungen lassen sich auf Gesamt-Dashboard-Ebene einrichten, wobei einzelne Charts von der automatischen Aktualisierung ausgenommen werden können. Das Stagger-Refresh-Feature verteilt Abfrageaufrufe über ein Zeitfenster, um Lastspitzen zu vermeiden.
Berechtigungen und Sicherheit
Die Zugriffssteuerung erfolgt über das rollenbasierte Berechtigungsmodell von Flask AppBuilder. Rollen können Berechtigungen auf Objekte wie Datenbanken, Tabellen, Datasets, Charts oder Dashboards erhalten. Row-Level Security-Policies filtern Datensätze je nach Benutzerrolle oder anderen Kriterien automatisch, ohne dass der Anwender den Filter explizit setzen muss. Dies ermöglicht die Umsetzung von Datenschutz- und Compliance-Vorgaben, indem Benutzer nur die für sie freigegebenen Daten sehen. Benutzerkonten lassen sich manuell anlegen oder über OAuth, LDAP oder andere Authentifizierungsmechanismen integrieren.
Performance-Optimierung und Caching
Um Antwortzeiten zu verbessern und Datenbanken zu entlasten, speichert Superset Abfrageergebnisse im Cache. Dieser kann auf Chart- oder Dashboard-Ebene zeitlich gesteuert werden. Für große, komplexe Abfragen empfiehlt sich das asynchrone Abfrageverfahren, bei dem Celery Worker die Berechnungen im Hintergrund ausführen und das Ergebnis nach Fertigstellung an das Frontend übergeben. Die Konfiguration der Cache Backends und Timeouts erfolgt in der Datei superset_config.py. Zusätzlich können materialisierte Ansichten in der Datenquelle die Performance steigern.
Automatisierte Berichte und Alerts
Mit der Alerts-and-Reports-Funktion lassen sich Dashboards als periodische Screenshots per E-Mail oder über Webhooks an Slack versenden. Berichte werden in festgelegten Intervallen als hochauflösende PNG-Dateien generiert und können in Standardformaten weiterverarbeitet werden. Alerts sind an SQL-Bedingungen gebunden, die in definierten Abständen geprüft werden.
Bei Eintritt der Bedingung, etwa ein Umsatzwert unter einem Schwellwert oder eine Anomalie in den Daten, wird eine Benachrichtigung versendet. Die Ausführung dieser Aufgaben hängt von funktionierenden Worker- und Beat-Prozessen sowie einer korrekt konfigurierten Caching-Schicht ab.
API-Nutzung und Automatisierung
Superset stellt eine dokumentierte REST API bereit, deren Endpunkte mit Swagger einsehbar sind. Über die API lassen sich Dashboards, Charts, Datasets und andere Objekte erstellen, ändern, exportieren und importieren. Dadurch ist eine Integration in CI/CD-Pipelines möglich, zum Beispiel um Änderungen aus einer Entwicklungsumgebung automatisiert in eine Produktionsinstanz zu übertragen. Das Import-/Export-Feature erlaubt es, Dashboards als ZIP-Pakete zwischen Instanzen zu verschieben.
Erweiterung und Anpassung
Die Benutzeroberfläche kann über CSS-Templates und anpassbare Farbschema an Unternehmensvorgaben angepasst werden. Das Plugin-Framework ermöglicht die Entwicklung neuer Chart-Typen oder die Erweiterung bestehender um zusätzliche Parameter. Für geografische Visualisierungen lassen sich eigene Layer und Kartenstile einbinden. Feature Flags steuern die Aktivierung neuer oder experimenteller Funktionen wie Cross-Filtering, Drill-by oder verbesserte Tabellenexports.
Betrieb und Verwaltung
Ein stabiler Betrieb setzt regelmäßige Backups der Metadaten-Datenbank voraus, um Konfigurationen, Benutzerkonten und Visualisierungen im Fehlerfall wiederherstellen zu können. Änderungen an Konfiguration und Feature Flags werden zentral in superset_config.py vorgenommen. Für den sicheren Zugriff empfiehlt sich der Betrieb hinter einem HTTPS-fähigen Reverse Proxy. Bei steigender Nutzerzahl sollte die Last auf mehrere Applikations-Instanzen verteilt werden, um Antwortzeiten stabil zu halten.
Fazit
Apache Superset verbindet die Offenheit einer Open-Source-Lösung mit einem breiten Funktionsspektrum für Analyse und Visualisierung. Die Plattform bietet eine flexible Integration in bestehende Datenlandschaften, eine umfangreiche Chart-Bibliothek, eine leistungsfähige API und präzise Berechtigungsmechanismen. Richtig konfiguriert und in eine skalierbare Infrastruktur eingebettet, eignet sich Superset sowohl für explorative Ad-hoc-Analysen als auch für den Betrieb strategischer Dashboards im Unternehmen.




