
R Studio - stock.adobe.com
Persistentes Storage im Kubernetes-Cluster mit Ceph verwalten
Ceph und Rook verbinden Kubernetes mit hochverfügbarem, dynamisch skalierbarem Storage und ermöglichen persistente Datenhaltung ohne Cloud-Dienste. Der Beitrag zeigt, wie das geht.

Persistente Volumes bilden in Kubernetes die Grundlage für stabile Workloads. Container können jederzeit neu starten oder auf andere Nodes verschoben werden. Ohne eine dauerhaft angebundene Speicherstruktur gehen dabei alle Daten verloren. In Cloud-Umgebungen liefern Anbieter wie AWS oder Azure dafür eigene Storage-Services, die in Kubernetes typischerweise über CSI-Treiber wie EBS-CSI oder Azure Disk CSI eingebunden werden. In selbstverwalteten Clustern muss der Speicher lokal aufgebaut werden. Ceph und Rook kombinieren dafür Cluster-Architektur, Automatisierung und Kubernetes-native Verwaltung.
Architektur und Grundprinzip von Ceph
Ceph ist ein vollständig verteiltes Speichersystem, das Block-, Objekt- und Dateispeicher in einer konsistenten Struktur abbildet. Das Cluster besteht aus mehreren Nodes mit gemeinsamem Speicherpool. Die Daten liegen verteilt auf Object Storage Daemons (OSDs), die Ceph über den Dienst RADOS automatisch repliziert und synchronisiert. Monitore (MON) erfassen den Cluster-Zustand, Manager (MGR) übernehmen Telemetrie und Steuerung, Metadatenserver (MDS) verwalten Dateisysteme wie CephFS. Für Blockzugriffe stellt Ceph RBD bereit, RADOS Gateway öffnet S3- und Swift-kompatible APIs für Objektspeicher. Die Architektur ist auf Redundanz, Skalierbarkeit und Selbstheilung ausgelegt. Jeder Datenblock existiert mehrfach auf verschiedenen Festplatten und Hosts.
Rook als Operator für Kubernetes
Rook bindet Ceph direkt in Kubernetes ein. Der Rook-Operator agiert als Schnittstelle und steuert alle Komponenten über Custom Resource Definitions (CRDs). Diese erweitern die Kubernetes-API um eigene Objekte wie CephCluster, CephBlockPool oder CephFilesystem. Damit lassen sich sämtliche Parameter deklarativ in YAML-Dateien definieren. Der Operator analysiert die Konfiguration, erstellt Monitore, OSDs, Manager und Gateways und überwacht den Zustand aller Komponenten. Über den integrierten CSI-Treiber stellt Rook Block- und Dateispeicher für Pods bereit. Ceph wird dadurch zu einer nativen Kubernetes-Ressource, die sich wie jede andere Workload verwalten lässt.
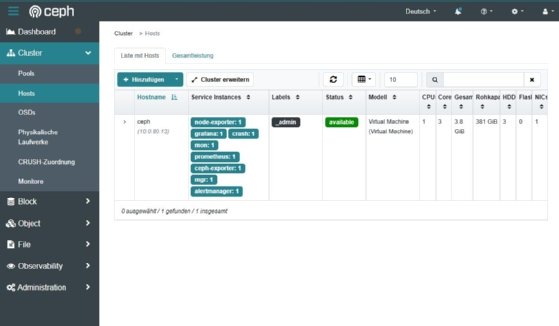
Aufbau einer Testumgebung
Für den praktischen Einstieg genügt ein einzelner Host mit Ubuntu 24.04 LTS und vier Laufwerken. Eine Festplatte enthält das Betriebssystem, die übrigen drei nutzt Ceph als OSD-Geräte. Ceph formatiert die Laufwerke automatisch (Bluestore), daher sollten sie leer sein. In produktiven Umgebungen sind mindestens drei Nodes mit jeweils zwei CPUs und 4 GB RAM sinnvoll. Die Laufwerke müssen unformatiert sein, damit Ceph sie direkt verwenden kann. Zuerst installiert man auf allen Hosts die erforderlichen Pakete:
sudo apt-get install -y lvm2Ceph benötigt LVM zur Verwaltung der logischen Volumes. Anschließend folgt die Installation des Cluster-Werkzeugs Cephadm:
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl gnupg lsb-release
curl -fsSL https://download.ceph.com/keys/release.asc | sudo gpg --dearmor -o /usr/share/keyrings/ceph.gpg
echo "deb [signed-by=/usr/share/keyrings/ceph.gpg] https://download.ceph.com/debian-reef/ $(lsb_release -sc) main" | sudo tee /etc/apt/sources.list.d/ceph.list
sudo apt update
sudo apt install -y cephadmNach Abschluss initialisiert der Befehl sudo cephadm bootstrap --mon-ip 10.0.80.13 den ersten Monitor und erstellt das Dashboard. Im Browser steht danach die Weboberfläche des Clusters zur Verfügung. Über den Menüpunkt Cluster → Hosts lässt sich der erste Node prüfen. Der Status zeigt available oder up, sobald die Basiskomponenten laufen.
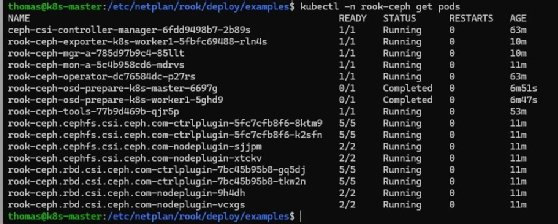
OSDs einbinden und Cluster prüfen
Die Speichergeräte lassen sich in der Shell mit sudo cephadm shell -- lsblk -f anzeigen. Nicht formatierte Laufwerke wie /dev/sdb oder /dev/sdc werden als OSDs hinzugefügt:
sudo cephadm shell -- ceph orch daemon add osd ceph:/dev/sdb
sudo cephadm shell -- ceph orch daemon add osd ceph:/dev/sdcDer Cluster-Status lässt sich jederzeit mit sudo cephadm shell -- ceph status kontrollieren.
Sobald HEALTH_OK erscheint, arbeitet mindestens ein OSD aktiv. Damit steht Ceph bereit, um über Rook in Kubernetes integriert zu werden.
In kleineren Szenarien genügt ein einzelner Host. Der Aufbau bleibt identisch, auch wenn später zusätzliche Nodes ergänzt werden.
Integration in Kubernetes mit Rook
Der Rook-Operator wird als Pod im Namespace rook-ceph betrieben. Nach dem Klonen des offiziellen Repositories
sudo git clone --single-branch --branch v1.18.6 https://github.com/rook/rook.git
cd rook/deploy/exampleswerden die Grundressourcen installiert:
kubectl create -f crds.yaml -f common.yaml -f csi-operator.yaml -f operator.yamlMit kubectl -n rook-ceph get pods lässt sich prüfen, ob der Operator aktiv ist. Danach folgt die Definition des CephClusters über die Datei cluster-test.yaml. Sie beschreibt ein einfaches Cluster mit automatischer Geräteerkennung:
kubectl create -f cluster-test.yamlRook initialisiert daraufhin alle Komponenten und startet Monitore, Manager und OSDs. Der Fortschritt ist über kubectl -n rook-ceph get pods sichtbar. Sobald alle Pods laufen, ist Ceph vollständig eingebunden.
StorageClass und Volume-Test
Für die Bereitstellung dynamischer Volumes definiert man eine StorageClass, die RBD-Pools nutzt. Im Verzeichnis rook/cluster/examples/kubernetes/ceph/csi/rbd befindet sich die passende Datei. Nach Anpassung der Parameter genügt:
kubectl apply -f storageclass-test.yamlDie StorageClass rook-ceph-block steht anschließend im Cluster bereit.
Ein Test-Deployment mit Nginx zeigt die Funktion:
apiVersion: apps/v1
kind: Deployment
metadata:
name: web
spec:
replicas: 1
selector:
matchLabels:
app: web
template:
metadata:
labels:
app: web
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: data
mountPath: /usr/share/nginx/html
volumes:
- name: data
persistentVolumeClaim:
claimName: web-pvc
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: web-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
storageClassName: rook-ceph-blockDie Datei wird mit kubectl apply -f web.yaml gespeichert und angewendet.
Der Operator erstellt automatisch ein Ceph-RBD-Volume und bindet es an den Pod. Der Status der PVC zeigt Bound, sobald das Volume aktiv ist. Nach dem Löschen und Neustarten des Pods bleiben die Daten erhalten, da sie im Ceph-Cluster liegen.
Verwaltung und Diagnose im Cluster
Zur internen Wartung steht die Rook-Toolbox zur Verfügung:
kubectl apply -f toolbox.yamlkubectl -n rook-ceph exec -it rook-ceph-tools -- bashIn der Toolbox sind Kommandos wie ceph status, ceph osd tree oder ceph df nutzbar, um den Zustand und die Replikation zu prüfen. Parallel dazu liefert das Ceph-Dashboard grafische Auswertungen zu Latenz, Auslastung und Cluster-Zustand. Über Prometheus und Grafana lassen sich Metriken zentral erfassen und auswerten. Rook exportiert diese automatisch, um Engpässe früh zu erkennen.
Skalierung und Redundanz
Ceph reagiert dynamisch auf neue Ressourcen. Sobald weitere Laufwerke oder Nodes eingebunden sind, erkennt Rook die Änderungen und erstellt zusätzliche OSDs. Ceph verteilt Daten automatisch neu, erhöht die Redundanz und balanciert das Cluster aus. Der Prozess läuft ohne manuelles Eingreifen. Fällt eine Node aus, übernehmen verbleibende OSDs den Zugriff auf replizierte Datenblöcke. Monitore und Manager sichern das Quorum und stellen den Dienst ohne Unterbrechung bereit. Die Architektur bleibt dadurch stabil, auch unter Last oder bei Ausfällen einzelner Komponenten.
Sicherheit und Wiederherstellung
Ceph schützt gespeicherte Daten über Replikation, Verschlüsselung und konsistente Integritätsprüfungen. Administratoren definieren für jeden Pool eine Replikationsstrategie, die Redundanz über mehrere Datenträger verteilt. Zusätzlich lassen sich Volumes verschlüsseln, um Daten bei physischem Zugriff zu schützen. Über das RADOS Gateway können Zugriffsschlüssel und Benutzerrollen erstellt und über Kubernetes Secrets abgebildet werden.
Snapshots sichern den Zustand einzelner Volumes oder Pools. Bei Defekten oder Fehlkonfigurationen kann Ceph daraus selbstständig wiederherstellen. Die Kombination aus Replikation, Self-Healing und verschlüsselter Speicherung erzeugt ein robustes Gesamtsystem für produktive Kubernetes-Workloads.
Auf einen Blick: Ceph und Rook für Kubernetes-Cluster
Rook und Ceph bilden eine vollständig integrierte Plattform für persistenten Speicher in Kubernetes-Clustern. Ceph liefert die skalierbare Speicherinfrastruktur, Rook automatisiert die Verwaltung über Kubernetes-native Mechanismen. Durch CRDs und CSI lassen sich komplexe Speicherstrukturen deklarativ abbilden und nahtlos in bestehende Cluster einfügen.
Der Aufbau kann mit minimaler Hardware beginnen und später ohne Neuinstallation wachsen. Damit steht eine ausgereifte Lösung bereit, um Container mit dauerhaften, fehlertoleranten und dynamisch erweiterbaren Volumes zu versorgen. Ceph und Rook schließen die Lücke zwischen Storage-Management und Containerorchestrierung und schaffen eine konsistente Basis für produktive Cloud-native Umgebungen.




