
pressmaster - stock.adobe.com
Ceph und Sheepdog als Object-Datenspeicher einsetzen
Wir zeigen in diesem Beitrag die beiden Open Source-Storage-Lösungen Ceph und Sheepdog. Mit beiden lassen sich Object Storage-Szenarien umsetzen.

Geht es um die Bereitstellung von Object Storage im Unternehmen oder hybriden Netzwerken, in denen auch effektiver Cloud-Speicher genutzt werden soll, bieten große Hersteller wie Amazon oder Microsoft in ihren Cloud-Speichern einige Möglichkeiten an.
Im internen Netzwerk gibt es ebenfalls Möglichkeiten, Object Storage umzusetzen. Wir sind im Beitrag Object Storage: Speicher für Cloud und hybride Umgebungen bereits auf das Thema eingegangen.
Unternehmen können beim Aufbau eines Speichernetzwerkes mit Object Storage auch auf Open-Source-Lösungen setzen. Wir stellen nachfolgend die beiden bekannten Lösungen Ceph und Sheepdog vor.
Object Storage mit Open Source: Ceph
Ceph bietet einheitliche Object- und Block Storage-Funktionen. Die Softwarebibliotheken von Ceph bieten Client-Anwendungen zum Beispiel Zugriff auf das objektbasierte Speichersystem RADOS. Dazu kommen Grundlagen wie RADOS Block Device (RBD), RADOS Gateway (RGW) und das Ceph File System (CephFS). Diese Funktionen stehen als Open Source bereit.
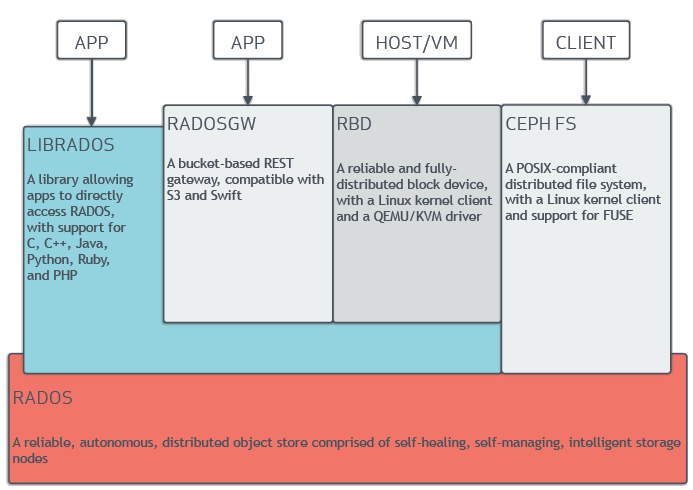 Aufbau eines Ceph Object Storage (Copyright: Ceph)
Aufbau eines Ceph Object Storage (Copyright: Ceph)
Die Librados-Softwarebibliothek von Ceph ermöglichen Anwendungen, die in C, C++, Java, Python und PHP geschrieben wurden, über native APIs auf das Objektspeichersystem von Ceph zuzugreifen. Darüber hinaus bietet Ceph S3-kompatible und Swift-kompatible Schnittstellen. Schreibgeschützte Snapshots und das Zurücksetzen von Snapshots werden ebenfalls unterstützt.
Ceph Object Storage verwendet Ceph Object Gateway Daemon (Radosgw). Dieser stellt einen HTTP-Server für die Interaktion mit einem Ceph Storage Cluster bereit. Neben der Kompatibilität mit OpenStack Swift und Amazon S3, verfügt das Ceph Object Gateway über eine eigene Benutzerverwaltung.
Das Ceph Object Gateway kann Daten im gleichen Ceph Storage Cluster speichern, der auch für die Speicherung von Daten der Ceph File System Clients oder Ceph Block Device Clients verwendet wird. Die S3- und Swift-APIs teilen sich einen gemeinsamen Namensraum, so dass Daten mit einer API geschrieben und mit einer anderen abgerufen werden können.
Unabhängig davon ob Ceph Object Storage oder Ceph Block Device Services für Cloud-Plattformen bereitgestellt werden sollen, wird beim Einsatz von Ceph zunächst mit der Einrichtung der Ceph-Knotens begonnen. Das gilt auch dann, wenn ein Ceph File System bereitgestellt werden soll, oder Ceph für andere Zweck eingesetzt wird.
Ein Ceph Storage Cluster besteht aus mehreren Komponenten. Abhängig von der Größe des Clusters können auch mehrere dieser Komponenten eingesetzt werden. Die wichtigsten Komponenten sind Ceph Monitor, Ceph Manager und Ceph OSD (Object Storage Daemon). Der Ceph Metadata Server wird benötigt, wenn Ceph File System-Clients im Einsatz sind.
Ein Ceph-Monitor (ceph-mon) verwaltet die Maps des Clusters. Die Maps werden dazu benötigt, damit Ceph-Daemons miteinander kommunizieren können. Monitore sind auch für die Verwaltung der Authentifizierung zwischen Daemons und Clients zuständig. Der Ceph Manager-Daemon (ceph-mgr) ist für die Laufzeitmetriken und den aktuellen Zustand des Ceph-Clusters verantwortlich. Er überwacht Speicherauslastung, aktuelle Performance-Metriken und die komplette Systemauslastung.
Ein Ceph OSD (Object Storage Daemon, ceph-osd) speichert Daten, und ist für die Datenreplikation, Wiederherstellung und den Datenabgleich verantwortlich. Außerdem stellt er den Ceph-Monitoren und Managern Überwachungsdaten zur Verfügung. Dazu überwachen sich Ceph OSD Daemons selbst und die anderen OSDs im Cluster. Ceph speichert Daten als Objekte in logischen Speicherpools. Dazu wird der CRUSH-Algorithmus verwendet. Dieser berechnet wie das Objekt gespeichert werden soll, und berechnet welcher Ceph OSD-Daemon die Daten speichern soll. Der Algorithmus ermöglicht es dem Ceph Storage Cluster, dynamisch zu skalieren.
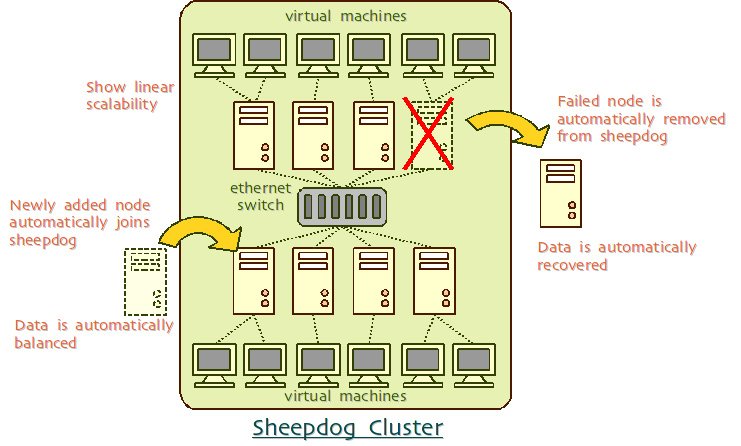 Abbildung 2: Aufbau eines Sheepdog-Clusters (Copyright: Sheepdog)
Abbildung 2: Aufbau eines Sheepdog-Clusters (Copyright: Sheepdog)
Sheepdog - Distributed Object Storage-System für VMs und Container
Sheepdog gibt es seit 2009. Auch damals gab es bereits Ceph. Allerdings war dem Entwickler der Umgang mit Ceph zu kompliziert. Daher hat er sich entschieden ein Object-Storage-System zu entwickeln, dass hochverfügbar und skalierbar ist, aber gleichzeitig auch eine einfache Bedienung bietet. Sheepdog ist seit Beginn eng an Speicherinfrastruktur für KVM/QEMU gebunden und wurde für die Verwendung mit diesen Virtualisierungs-Technologien optimiert.
Sheepdog ist ein verteiltes Objektspeichersystem, das auch für Containerdienste eingesetzt werden kann. Die Verwaltung der angebundenen Festplatten und Knoten werden durch das System intelligent verwaltet. Sheepdog unterstützt das Klonen, Snapshots und Thin Provisioning.
Darüber hinaus ist das Tool mit Amazon S3 und OpenStack kompatibel. Die Containerabstraktion auf Objektebene kann verwendet werden, um beliebige Datenmengen mit einer Webservice-Schnittstelle zu speichern und abzurufen. Sheepdog bietet die Möglichkeit der Skalierung auf Tausende von Knoten.
Die Volume-Abstraktion auf Blockebene kann an virtuelle QEMU-Maschinen und Linux SCSI-Target gehängt werden. Sheepdog sollte zu Beginn vor allem als Speichersystem für QEMU eingesetzt werden. Die Verwaltung der gespeicherten Daten basiert auf Virtual Disk Images (VDIs). Das Befehlszeilen-Tool von Sheepdog verwendet das Schlüsselwort „vdi“, um auf Speicherobjekte zuzugreifen.
Sheepdog unterscheidet generell vier Arten von Informationen für jedes Speicherobjekt: Dazu gehören zunächst die eigentlichen Daten und die Metadaten wie Name, Größe, Zeitstempel und ID. Darüber hinaus kann der Status virtuellen Servers und die VDI-Attribute gespeichert werden.
Zookeeper oder Corosync nutzen
Sheepdog ist IP-basiert. Die Umgebungen nutzen also das Netzwerk als Transportmedium. Der Cluster bildet in Sheepdog das Grundgerüst für die Server, mit denen Datenspeicherung bereitgestellt wird. Sheepdog kann auch mit Zookeeper eingesetzt werden. Das ist vor allem für große Cluster sinnvoll. In kleinen Umgebungen kann auch auf Corosync gesetzt werden.
Sheepdog
Wer Sheepdog in kleinen Umgebungen nutzen will, oder eine Test- und Entwicklungsumgebung aufbauen will, kann den Cluster auch auf einer einzelnen Maschine installieren. Auf jedem Sheepdog-Computer, der als Datenspeicherknoten genutzt wird, läuft ein Daemon-Prozess mit dem Namen „sheep“.
Er verarbeitet die I/O-Anforderungen und kümmert sich um die Speicherung der Daten. Die teilnehmenden Speicherserver werden als Sheeps bezeichnet.




