
kalafoto - stock.adobe.com
Longhorn: Blockspeicher im Cluster ohne externes SAN
Als Container-natives Storage-System stellt Longhorn persistente Volumes bereit, ermöglicht Replikation und eignet sich für Cluster ohne zentrales Storage.

Longhorn arbeitet als verteiltes Block Storage direkt im Kubernetes-Cluster und nutzt ausschließlich die lokalen Datenträger der Worker-Nodes. Ein externes SAN (Storage Area Network) oder ein separates Storage-Cluster ist für den Einsatz nicht notwendig. Der Ansatz zielt auf Umgebungen, in denen Kubernetes auf Bare-Metal oder auf Instanzen ohne bereitgestellten Netzwerkspeicher läuft. Persistente Volumes (PV) stehen damit unabhängig vom Infrastrukturmodell zur Verfügung und binden sich über CSI (Container Storage Interface) vollständig in die Kubernetes-API ein. Der Quellcode steht auf Github zur Verfügung.
Architektur mit Volume-orientierten Microservices
Jedes Volume erhält einen eigenen Controller in Form der Longhorn-Engine. Dieser Controller kapselt die Blockzugriffe und steuert die Replikate, die als separate Container auf verschiedenen Nodes laufen. Die Engine selbst liegt auf dem Node, an den das Volume gebunden ist. Der Longhorn-Manager koordiniert die Engine-Instanzen, verwaltet Replikate, überwacht Zustände und übersetzt Kubernetes-Aktionen auf Ebene von Persistent Volumes und Persistent Volume Claims (PVC) in Storage-Operationen. Dieser Volume-orientierte Zuschnitt reduziert die Komplexität gegenüber monolithischen Storage-Diensten und erlaubt eine feingranulare Steuerung pro Volume.
Nutzung lokaler Datenträger als Storage-Pool
Longhorn bildet keinen eigenen Storage-Pool außerhalb des Clusters. Stattdessen aggregiert es die Kapazitäten aller eingebundenen Worker-Nodes. Zusätzliche Nodes oder erweiterte Datenträger vergrößern den nutzbaren Pool damit, sobald diese an Longhorn angebunden sind. Replikate belegen Speicher dünn provisioniert und wachsen mit dem tatsächlichen Datenbestand. Diese Eigenschaft erfordert eine bewusste Kapazitätsplanung, da der physische Verbrauch sich mit der Replikatanzahl multipliziert.
Integration in Kubernetes über PV und PVC
Workloads binden Speicher nicht direkt an, sondern deklarieren ihren Bedarf über Persistent Volume Claims. Kubernetes ordnet diesen Anforderungen passende Persistent Volumes zu, die Longhorn dynamisch bereitstellt und verwaltet. Dadurch bleiben Deployments portabel und trennen Anwendungslogik von der zugrunde liegenden Storage-Implementierung. Longhorn stellt dazu eine StorageClass bereit, die dynamisch Persistent Volumes erzeugt. Die Steuerung der Replikatanzahl, der Platzierung und weiterer Parameter erfolgt entweder global oder auf Volume-Ebene. Kubernetes verwaltet Bindung, Mount und Lebenszyklus der Volumes, während Longhorn die Blockebene übernimmt. Dieser Mechanismus erlaubt portierbare Deployments ohne Abhängigkeit von Cloud-spezifischen Storage-Diensten.
Replikation und Verfügbarkeit
Jedes Volume lässt sich synchron über mehrere Nodes replizieren. Drei Replikate gelten als übliche Konfiguration für produktive Umgebungen, da ein Node-Ausfall ohne Datenverlust überstanden wird. Fällt ein Replikat aus, startet Longhorn automatisch einen Rebuild auf einem geeigneten Node. In dieser Phase markiert der Status das Volume als degradiert, bis der Rebuild abgeschlossen ist. Der Rebuild erzeugt zusätzliche Last auf dem verbliebenen Replikat, was bei gleichzeitigen Ausfällen die Performance reduziert. Diese Eigenschaft verlangt eine realistische Bewertung der Ausfallwahrscheinlichkeiten und der Lastprofile.
Mittlerweile wird auch auf eine Konfiguration mit zwei Replikaten hingewiesen, die eine bessere Kapazitätsnutzung bei weiterhin guter Verfügbarkeit verspricht und für Produktions-Workloads empfohlen wird.
Data Locality und Performance-Abwägung
Data Locality steuert die Platzierung von Replikaten in Relation zum konsumierenden Pod. Best-Effort versucht ein lokales Replikat bereitzustellen, ohne die Verfügbarkeit einzuschränken. Strict Local erzwingt die Bindung an einen Node und setzt ein einzelnes Replikat voraus. Diese Einstellung verbessert die Latenz, schränkt aber die Ausfallsicherheit massiv ein. Der Einsatz beschränkt sich auf Sonderfälle mit klar definierten Risiken. In allen anderen Szenarien bietet Best-Effort ein ausgewogeneres Verhältnis.
Replica Auto Balance verteilt Replikate gleichmäßig über verfügbare Nodes und reagiert auf neue Kapazitäten im Cluster. Ergänzend steuern Soft-Anti-Affinity-Regeln die Platzierung auf Disk-, Node- und Zonenebene. Dadurch verhindert Longhorn, dass mehrere Replikate desselben Volumes auf identischen Fehlerdomänen landen. Diese Mechanismen gewinnen an Bedeutung in Clustern mit vielen Disks pro Node oder mit logischer Zonierung.
Snapshot-Mechanik und Integrität
Snapshots speichern Blockänderungen inkrementell und bilden die Grundlage für Backups und Replikate. Die Snapshot-Integritätsprüfung berechnet Prüfsummen der Snapshot-Dateien und erkennt beschädigte Daten frühzeitig. Der Prüfprozess erzeugt zusätzliche Last und gehört in Nebenzeiten geplant. Eine zeitgesteuerte Ausführung über Cron-Jobs reduziert den Einfluss auf produktive Workloads. Korrupt erkannte Replikate lösen automatisch einen Rebuild aus.
Gelöschte Dateien geben auf Blockebene keinen Speicher frei, solange das Dateisystem nicht getrimmt wird. Longhorn stellt dafür eine Trim-Funktion bereit, die freien Platz zurückgewinnt. Der Vorgang beeinflusst die Performance und erfordert eine bewusste Planung. Ergänzend entfernt die Bereinigung verwaister Daten Reste aus abgebrochenen Rebuilds oder fehlgeschlagenen Operationen.
Backup-Ziele und externe Speicherung
Backups schreiben inkrementelle Daten in externe Ziele auf Basis von NFS oder S3-kompatiblen Objektspeichern. Die Anbindung erfolgt über Secrets im Namespace longhorn-system. Mehrere Backup-Ziele lassen sich parallel konfigurieren, um Redundanz oder getrennte Aufbewahrungsstrategien umzusetzen. Longhorn synchronisiert Metadaten regelmäßig und hält den Status der Backups konsistent.
Wiederkehrende Jobs steuern Snapshots und Backups zeitlich und legen die Anzahl aufzubewahrender Versionen fest. Diese Jobs laufen unabhängig vom Workload und reduzieren den operativen Aufwand. Die Kombination aus inkrementellen Snapshots und externer Speicherung ermöglicht kurze Wiederherstellungszeiten bei begrenztem Speicherverbrauch.
Ein Restore erzeugt ein neues Volume aus einem Backup. Dieses Volume bindet sich an ein neues PV und PVC. Der Ansatz vermeidet Risiken durch In-Place-Rücksicherungen und erlaubt parallele Tests. Cross-Cluster-DR (Disaster Recovery) nutzt denselben Mechanismus und stellt Volumes in einem zweiten Cluster bereit. Anwendungen starten dort mit definierten RPO- und RTO-Werten, sofern die Infrastruktur vorbereitet ist.
RWX-Volumes und Share Manager
ReadWriteMany-Volumes lassen sich über den Share Manager erstellen, der Longhorn-Volumes per NFS bereitstellt. Diese Option eignet sich für Anwendungen mit gemeinsamem Dateizugriff. Die zusätzliche Abstraktion erhöht die Latenz und begrenzt die Performance. Der Einsatz erfordert daher eine klare Abgrenzung zu Block-Workloads mit exklusivem Zugriff.
Installation und Node-Voraussetzungen
Vor der Installation prüfen Administratoren die Worker-Nodes mit dem von Longhorn bereitgestellten Environment-Check-Skript. Das Skript validiert Kernel-Version, verfügbare Blockgeräte sowie benötigte Abhängigkeiten für iSCSI und NFS und weist explizit auf fehlende Komponenten hin.
ARCH="amd64"
curl -LO "https://github.com/longhorn/cli/releases/download/v1.10.1/longhornctl-linux-${ARCH}"
curl -LO "https://github.com/longhorn/cli/releases/download/v1.10.1/longhornctl-linux-${ARCH}.sha256"
echo "$(awk '{print $1}' longhornctl-linux-${ARCH}.sha256) longhornctl-linux-${ARCH}" | sha256sum --check
sudo install longhornctl-linux-${ARCH} /usr/local/bin/longhornctl
longhornctl versionDie Prüfung erfolgt mit:
longhornctl check preflight --kubeconfig /home/thomas/.kube/config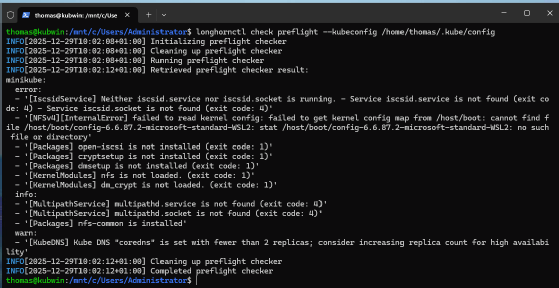
Erforderliche Pakete installieren Administratoren ausschließlich auf den Worker-Nodes. Für Block-Volumes über iSCSI sind Client-Werkzeuge und das Kernelmodul iscsi_tcp notwendig. Für Backups auf NFS kommt zusätzlich der passende Client zum Einsatz.
sudo apt update
sudo apt install -y open-iscsi nfs-common
sudo modprobe iscsi_tcpNach erfolgreicher Vorbereitung deployt die Installation alle Longhorn-Komponenten im Namespace longhorn-system. Die direkte Installation über kubectl nutzt das offizielle Manifest und eignet sich für schnelle Setups ohne zusätzliche Paketverwaltung.
kubectl apply -f
https://raw.githubusercontent.com/longhorn/longhorn/v1.10.1/deploy/longhorn.yamlDer Fortschritt lässt sich über die Pod-Übersicht überwachen, bis alle Komponenten den Status Running erreichen.
kubectl get pods -n longhorn-system --watchAlternativ erfolgt die Installation über Helm, was Anpassungen an Default-Werte und eine bessere Integration in bestehende Deployment-Prozesse erlaubt. Zunächst binden Administratoren das Helm-Repository ein und aktualisieren die Metadaten.
helm install longhorn longhorn/longhorn \
--namespace longhorn-system \
--create-namespace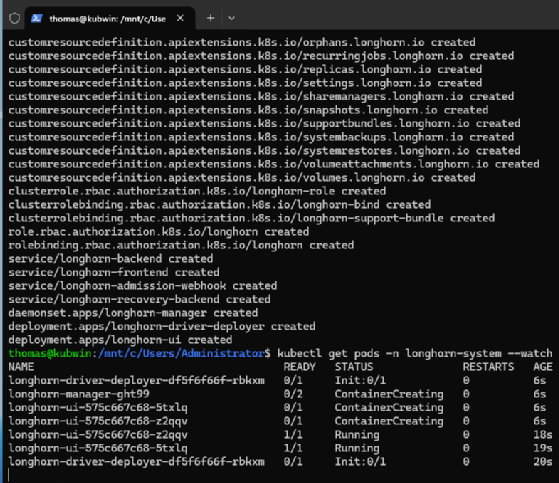
Anschließend installiert Helm Longhorn inklusive Namespace-Erstellung:
helm install longhorn longhorn/longhorn \
--namespace longhorn-system \
--create-namespaceNach dem Deployment prüfen Administratoren die erzeugten DaemonSets, Services und CSI-Komponenten, um einen konsistenten Betriebszustand sicherzustellen:
kubectl get daemonsets -n longhorn-system
kubectl get svc -n longhorn-systemFür den Zugriff auf die Weboberfläche nutzen Testumgebungen häufig Port-Forwarding auf den Service longhorn-frontend.
kubectl port-forward svc/longhorn-frontend -n longhorn-system 8080:80Produktive Umgebungen binden die UI über einen Ingress-Controller ein und ergänzen eine Authentisierungsebene, da Longhorn selbst keine Zugriffskontrolle auf UI-Ebene bereitstellt.
Wartung und Upgrades im laufenden Betrieb
Upgrades von Manager und Engine erfolgen ohne Eingriff in den laufenden Betrieb. Der Instance Manager orchestriert den Austausch der Engine-Images so, dass angebundene Volumes durchgehend erreichbar bleiben. Anstehende Wartungsarbeiten auf Node-Ebene lassen sich vorbereiten, indem Replikate frühzeitig auf andere Nodes verschoben werden. Auch Kubernetes-Upgrades laufen entlang abgestimmter Abläufe, die den Storage-Pfad funktionsfähig halten und ungeplante Unterbrechungen vermeiden.
Für den Betrieb stellt Longhorn umfangreiche Metriken bereit, die sich nahtlos in Prometheus und Grafana einfügen und die vom Kubelet gelieferten Informationen sinnvoll ergänzen. Beobachtet werden unter anderem Rebuild-Vorgänge, degradierte Volumes, Kapazitätsverläufe und Latenzentwicklungen. Alarmregeln heben Abweichungen zeitnah hervor. Support-Bundles bündeln relevante Zustands- und Diagnosedaten und erleichtern die Untersuchung komplexer Störfälle erheblich.
Zum Schutz ruhender Daten steht eine Volume-Verschlüsselung zur Verfügung. Die interne Kommunikation zwischen den Komponenten erfolgt über mTLS. Sensible Informationen verbleiben im dedizierten Namespace. Zugriffe auf Managementfunktionen erfordern eine konsequente Absicherung. Das Kommandozeilenwerkzeug longhornctl ergänzt den Betrieb um Möglichkeiten für Prüfungen, gezielte Fehleranalyse und die Automatisierung wiederkehrender Aufgaben.
Praktische Einordnung aus Betriebserfahrung
Longhorn entfaltet seinen Nutzen in Clustern ohne vorhandenes Netzwerk-Storage und mit Bedarf an persistenter Speicherung direkt im Kubernetes-Kontext. Der Mehrwert liegt in der einfachen Bereitstellung, der integrierten Replikation und den durchgängigen Backup- und Restore-Funktionen. Fehlplatzierungen auf redundantem SAN oder bei hochschreibintensiven, selbst replizierenden Datenbanken führen dagegen zu unnötigem Overhead. Eine bewusste Auswahl der Workloads, eine realistische Replikatplanung und eine strukturierte Backup-Strategie entscheiden über den Erfolg im Betrieb.
Erfahren Sie mehr über Storage und Virtualisierung
-
![]()
Orchestrierung für Block, File und Object Storage mit Rook
Von: Thomas Joos
-
![]()
Google Cloud Storage: Den CSI-Treiber für GKE installieren
Von: Ulrike Rieß-Marchive
-
![]()
Amazon EBS Storage mit CSI-Treiber in Kubernetes integrieren
Von: Ulrike Rieß-Marchive
-
![]()
Installationstipps für vSphere CSI-Treiber auf lokalem Storage
Von: Ulrike Rieß-Marchive



