
Zlider - stock.adobe.com
Orchestrierung für Block, File und Object Storage mit Rook
Rook orchestriert Ceph als Kubernetes-nativen Storage-Layer und automatisiert Deployment, Skalierung, Upgrades und Recovery für Block-, File- und Object-Workloads über CSI.

Persistentes Storage zählt zu den Grundvoraussetzungen für zustandsbehaftete Workloads in Kubernetes. Rook integriert Ceph als verteiltes Storage-System in den Cluster und steuert Deployment, Betrieb und Skalierung über Kubernetes-Ressourcen, CRDs (Custom Resource Definitions) und CSI (Container Storage Interface).
Rolle von Persistent Volumes im Kubernetes-Betrieb
Pods bleiben flüchtige Ausführungseinheiten. Scheduling, Rescheduling und Node-Wechsel gehören zum Normalbetrieb, Daten benötigen daher einen vom Pod-Lebenszyklus getrennten Speicherpfad. Kubernetes bildet diesen Pfad über PVs (Persistent Volume) und PVCs (Persistent Volume Claim) ab. In Managed-Cloud-Umgebungen liefern Provider Block-Volumes, File-Services oder Object Storage als externe Plattformdienste. In On-Premises- und selbst verwalteten Umgebungen übernimmt der Cluster-Betrieb auch die Verantwortung für das Storage-Backend, inklusive Kapazitätsplanung, Fehlertoleranz, Wartung und Upgrade-Strategie.
Ceph fasst Block Storage, Dateisystem und Object Storage in einer gemeinsamen Architektur zusammen. RADOS übernimmt die Speicherung und Konsistenz der Objekte und verteilt Daten über OSDs auf mehrere Datenträger. MON-Prozesse verwalten Cluster-Maps und Quorum, MGR liefert Management-Funktionen und Telemetrie. CephFS nutzt MDS für Metadatenoperationen und skaliert File-Workloads über mehrere Pfade. RBD stellt Block-Volumes bereit und unterstützt Snapshots sowie Klone. RGW liefert S3- und Swift-kompatible Object-APIs und koppelt Buckets an die Ceph-Pools.
Rook als Kubernetes Operator für Ceph
Rook agiert als Cloud-nativer Storage-Orchestrator für Kubernetes und steuert Ceph über den Operator-Pattern. Der Operator beobachtet den Ist-Zustand, vergleicht ihn mit der gewünschten Konfiguration und gleicht Abweichungen kontinuierlich aus. CRDs erweitern die Kubernetes-API um Ceph-spezifische Ressourcentypen, darunter CephCluster, Pools, File-Systeme und Object Stores. YAML-Manifeste beschreiben damit nicht nur Workloads, sondern auch den Storage-Layer selbst.
Rook automatisiert Aufgaben, die sonst bei Ceph-Installationen außerhalb von Kubernetes in separaten Betriebs- und Automationsketten liegen. Dazu zählen Bootstrap, Konfiguration, Provisioning, Skalierung, Upgrade-Steuerung, Monitoring-Integration, Ressourcenmanagement und Recovery-Workflows. Rook unterstützt unterschiedliche Topologien. Ein hyperkonvergentes Modell platziert Ceph-Pods auf denselben Nodes wie Applikationen und steuert Ressourcen über Requests, Limits, Affinities und Tolerations. Dedizierte Storage-Nodes isolieren Ceph über Taints und Tolerations. Ein External-Ceph-Modus bindet einen vorhandenen Ceph-Cluster an und nutzt Kubernetes primär als Control-Plane für CSI und Policy, inklusive Szenarien mit mehreren Kubernetes-Clustern gegen einen Ceph-Cluster und Mandantentrennung über reduzierte Ceph-User-Rechte und logische Trennung auf Pool- oder Sub-Volume-Ebene.
CSI als Datenpfad zwischen Kubernetes und Ceph
Kubernetes koppelt Storage über CSI an. Ceph-CSI implementiert die CSI-Spezifikation als gRPC-Server in Go und übersetzt CSI-Calls in Ceph-Operationen. Der Provisioner-Teil übernimmt Volume- und Snapshot-Lifecycle, Expansion und Attach-Workflows und nutzt Leader Election, um Failover im Controller-Pfad abzusichern. Der Node-Plug-in-Teil läuft als DaemonSet pro Node und übernimmt Mount und Unmount in den Pod-Namespace.
Ceph-CSI liefert separate Treiberpfade für RBD, CephFS und NFS. RBD adressiert Block-Workloads, CephFS liefert RWX-Shared-File-Workloads. Ceph-CSI liefert separate Treiber für RBD und CephFS. NFS wird in Ceph typischerweise über NFS-Ganesha bereitgestellt und kann in Kubernetes separat integriert werden. Topology-Awareness reduziert Latenz, indem Clients bevorzugt nahe OSD-Pfade nutzen, sofern die Cluster-Topologie die Platzierung abbildet.
Erweiterte Storage-Funktionen über CSI Addons
CSI Addons ergänzen die CSI-Spezifikation um fortgeschrittene Operationen. Reclaim Space führt bei RBD das Sparsify-Verfahren aus und nutzt bei Dateisystempfaden fstrim, um freigegebenen Platz wieder nutzbar zu machen. Network Fencing blockiert IP-Ranges über Ceph OSD-Blocklist und reduziert Konflikte nach Node-Loss-Szenarien, in denen ein Volume an einem neuen Node wieder anbindet. Volume Replication integriert DR-Mechanismen über wiederverwendbare APIs und ersetzt eigenständige Operator-Ketten. Encryption Key Rotation tauscht Schlüsselmaterial aus, ohne Daten neu zu verschlüsseln, und steuert Intervalle über Annotationen an PVs und StorageClasses. Diese Bausteine greifen über Custom Resources, Controller und gRPC-Kommunikation in Controller- und Node-Pfade ein.
Disaster Recovery über RBD Mirroring und CephFS Mirroring
RBD-Mirroring repliziert Images asynchron zwischen Clustern und unterstützt journal-basierte und snapshot-basierte Verfahren. Rook steuert Mirror-Daemons über CRDs und koppelt Failover-Aktionen über VolumeReplicationClass und VolumeReplication an einzelne PVs. Promotion und Demotion schalten die aktive Rolle eines Images um, Recovery-Time reduziert sich durch vorbereitete Replikationspfade.
CephFS Mirroring repliziert Snapshot-Stände für Remote-CephFS. Der Funktionsumfang bleibt im Vergleich zu RBD-DR stärker manuell geprägt und bleibt je nach Release-Stand im experimentellen Bereich. DR-Design hängt direkt an Failure-Domain-Definition, Replikationsfaktoren und an der Verfügbarkeit mindestens einer intakten Kopie als Ausgangspunkt für Recovery.
Installation von Rook und Ceph in einer Testumgebung
Für Evaluierungs- und Laborszenarien lässt sich ein Rook-Ceph-Cluster mit wenigen Schritten bereitstellen. Voraussetzung ist ein funktionsfähiger Kubernetes-Cluster sowie mindestens ein nicht partitioniertes Blockgerät pro Storage-Node. Auf den Nodes muss außerdem das Paket lvm2 installiert sein.
Das folgende Beispiel nutzt die Referenzmanifeste des Rook-Projekts und stellt einen minimalen Ceph-Cluster für Testzwecke bereit:
Voraussetzungen auf allen Kubernetes-Nodes
sudo apt-get update
sudo apt-get install -y lvm2Rook-Repository klonen
git clone --single-branch --branch v1.18.6 https://github.com/rook/rook.git
cd rook/deploy/examplesCRDs und Operator installieren
kubectl create -f crds.yaml
kubectl create -f common.yaml
kubectl create -f operator.yamlCeph-Cluster deployen (Testkonfiguration)
kubectl create -f cluster-test.yamlStatus prüfen
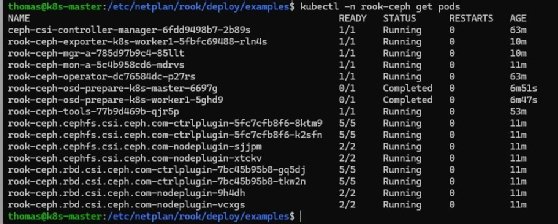
kubectl -n rook-ceph get podsFür Diagnosezwecke stellt Rook zusätzlich ein Toolbox-Pod bereit, über das sich Ceph-Kommandos direkt im Cluster ausführen lassen.
Die Testmanifeste sind nicht für Produktionsumgebungen gedacht. In realen Deployments werden üblicherweise angepasste Cluster-Definitionen mit expliziter Device-Selektion, Failure-Domain-Topologie, Ressourcenlimits und abgestimmten Replikationsfaktoren verwendet.
Observability
Ceph Manager liefert ein Dashboard für Cluster-Zustand, OSD-Status, Placement Groups, Latenzen, Objektverteilung und Kapazität. Rook integriert zusätzlich Prometheus-Metriken und Grafana-Dashboards, ergänzt um Alerting. Dieses Setup liefert Metriken für Throughput, Recovery-Raten, Backfill-Last, OSD-Latenzen, Client-I/O, Kapazitätsauslastung, Object Store Status und Fehlerzustände. Für die Diagnose eignet sich neben Dashboards auch ein CLI-Pfad im Cluster, der Ceph-Kommandos ohne SSH auf Storage-Nodes bereitstellt.
Nutzenprofil der Kombination Rook und Ceph in Kubernetes
Rook verschiebt Storage-Betrieb in das Kubernetes-Betriebsmodell und koppelt Ceph als Datenebene direkt an die Control-Plane. Teams pflegen Storage als deklarative Ressource, versionieren Konfigurationen und integrieren Änderungen in GitOps-Pipelines. Ceph liefert die eigentlichen Datenpfade für Block, Shared File und Object Storage, inklusive Replikation, Recovery-Mechanismen und Skalierung über Nodes und Datenträger. Diese Kombination adressiert typische Limits externer Cloud-Volumes in großen Clustern, reduziert Abhängigkeiten von Provider-Implementierungen und liefert ein einheitliches Storage-Backend für heterogene Workloads, ohne den Wechsel zwischen mehreren Storage-Produkten zu erzwingen.
Betriebssicherheit über Failure Domains und Wartungsmechanik
Ein belastbares Design setzt Failure Domains in die Topologie um und koppelt Replikationsfaktoren an real getrennte Ausfallbereiche. Rook steuert Upgrades so, dass Maintenance nicht mehrere Kopien gleichzeitig trifft, und nutzt dafür Kubernetes-Mechaniken wie Pod Disruption Budgets, Node-Drain-Verhalten und kontrollierte Rolling-Workflows. In einem Cluster mit drei Nodes führt ein vollständiger Ausfall aller Nodes ohne verbleibende Kopie zu komplexen Recovery-Pfaden, da Ceph keinen konsistenten Ausgangspunkt für Self-Healing sieht. Eine Architektur mit zusätzlichen Failure Domains, erhöhter Replikation oder einem zweiten Cluster für Replikation reduziert diese Risikoklasse und stabilisiert DR-Workflows.





