
rh2010 - stock.adobe.com
Ceph Storage auf Ubuntu für Proxmox und Kubernetes
Ceph ist ein hochverfügbares Open-Source-Speichersystem, das Block-, Datei- und Objektspeicher bereitstellen kann. Der Beitrag zeigt, wie sich das System einrichten lässt.

Ceph lässt sich als Storage-System schnell in Betrieb nehmen. Auch eine Verbindung mit Kubernetes ist möglich, zum Beispiel über Rook. Die Bereitstellung erfolgt beispielsweise auf einem Ubuntu-Server. Sinnvoll ist es natürlich, möglichst viele Knoten zu nutzen, damit das System ausfallsicher und performant ist.
Ein robustes Ceph-Cluster auf Ubuntu bildet eine verlässliche Grundlage für Block-, Datei- und Objektzugriffe in lokalen Umgebungen. Die folgenden Abschnitte zeigen Schritt für Schritt, wie ein Ceph-Host vorbereitet, installiert und erweitert wird. Kubernetes und Rook tauchen nur als Randthemen auf, da der Schwerpunkt auf der direkten Bereitstellung des Speichersystems liegt.
Grundlagen und Systemvorbereitung für Ceph
Ein Ceph-Cluster basiert auf mehreren Diensten, die zusammen einen verteilten Speicherpool bilden. Monitore verwalten den Cluster-Zustand, Manager liefern Telemetrie und Steuerung, OSDs verarbeiten den Zugriff auf die physischen Laufwerke und Metadatenserver unterstützen CephFS. Ein einzelner Host genügt für eine Testumgebung. Drei zusätzliche Laufwerke ohne Dateisystem liefern später die Grundlage für die OSDs. Im produktionsnahen Einsatz empfiehlt sich ein Verbund aus mindestens drei Ubuntu-Systemen mit lokalen Datenträgern und identischer Grundkonfiguration.
Der Aufbau beginnt auf Ubuntu mit einer Aktualisierung des Systems. Anschließend installiert das System alle Abhängigkeiten, die Ceph für das Management der Speichergeräte benötigt. Der folgende Befehl richtet LVM ein, das Ceph für die logischen Volumes nutzt.
sudo apt-get install -y lvm2Anschließend aktualisiert der Anwender das System, installiert alle erforderlichen Pakete und fügt das offizielle Ceph-Repository hinzu.
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl gnupg lsb-release
curl -fsSL https://download.ceph.com/keys/release.asc | sudo gpg --dearmor -o /usr/share/keyrings/ceph.gpg
echo "deb [signed-by=/usr/share/keyrings/ceph.gpg] https://download.ceph.com/debian-reef/ $(lsb_release -sc) main" | sudo tee /etc/apt/sources.list.d/ceph.list
sudo apt update
sudo apt install -y cephadmFalls die Paketquelle nicht zur Ubuntu-Version passt, lässt sich die Zeile mit dem festen Release-Namen jammy anlegen.
echo "deb [signed-by=/usr/share/keyrings/ceph.gpg] https://download.ceph.com/debian-reef/ jammy main" | sudo tee /etc/apt/sources.list.d/ceph.listCluster-Initialisierung mit cephadm
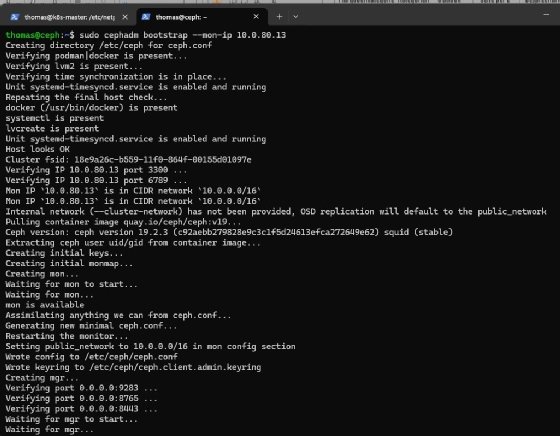
Die eigentliche Einrichtung beginnt mit dem Bootstrap-Befehl. Er richtet den ersten Monitor ein, erstellt die Verwaltungsschlüssel und aktiviert das Dashboard.
sudo cephadm bootstrap --mon-ip 10.0.80.13Nach Abschluss zeigt die Ausgabe die URL des Dashboards und den initialen Benutzernamen. Das Kennwort verlangt direkt nach der ersten Anmeldung eine Änderung. Über die Bereiche Cluster und Hosts lässt sich der Zustand des Systems prüfen.
Der folgende Aufruf zeigt den Cluster-Status direkt im Terminal.
sudo cephadm shell -- ceph statusEin HEALTH_OK signalisiert einen betriebsbereiten Host. HEALTH_WARN weist auf fehlende OSDs hin. In diesem Fall sind die leeren Laufwerke einzurichten. Die Übersicht über verfügbare Geräte liefert:
sudo cephadm shell -- lsblk -fSobald ein Gerät ohne Dateisystem auftaucht, legt der Administrator ein OSD an. Für zwei freie Geräte sieht das so aus:
sudo cephadm shell -- ceph orch daemon add osd ceph:/dev/sdb
sudo cephadm shell -- ceph orch daemon add osd ceph:/dev/sdcDer Host-Name hinter ceph muss exakt dem Namen des Systems entsprechen, das im Dashboard aufgeführt ist. Der Fortschritt lässt sich jederzeit abfragen.
sudo cephadm shell -- ceph orch psEin einzelner Host bildet eine einfache Entwicklungsumgebung. Bei späterer Erweiterung erkennt Ceph neue Geräte und zusätzliche Nodes automatisch und verteilt die Daten erneut, bis der Speicherpool ausgeglichen ist.
Verwaltung über Weboberfläche und Shell
Der eingebaute Webzugriff liefert eine strukturierte Übersicht über Leistungsdaten, Replikation und Auslastung. Diagramme zu Latenzen und Objektverteilungen unterstützen eine präzise Diagnose. Zusätzlich steht die Shell im cephadm-Container zur Verfügung. Sie erlaubt direkte Abfragen über ceph status, ceph df oder ceph osd tree und bildet damit ein komplettes Administrationswerkzeug direkt auf dem Host.
Nach der initialen Bereitstellung lassen sich Blockgeräte, CephFS-Dateisysteme oder Objektspeicher einrichten. RBD liefert Blockspeicher für virtuelle Maschinen oder Container. Das RADOS Gateway bietet S3-kompatible Zugriffe. Benutzerkonten, Quotas und Policies entstehen über separate Schlüssel und Pools. Die Verwaltung erfolgt über das Dashboard und das CLI (Command Line Interface).
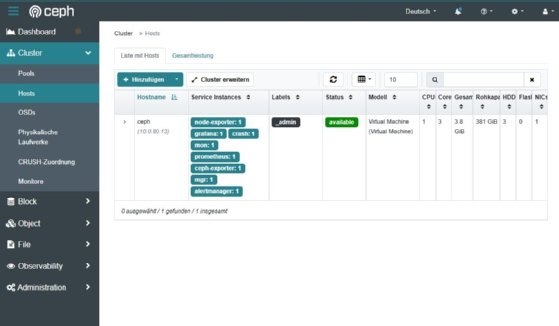
Erweiterung des Clusters
Neue Festplatten integriert Ceph automatisch. Der Administrator fügt sie über ceph orch daemon add osd hinzu. Ceph kopiert anschließend die Objekte auf die neuen Geräte und balanciert die Pools aus. Neue Hosts lassen sich mit cephadm ebenfalls einbinden. Der Befehl cephadm add-host registriert das System und macht es sofort für zusätzliche OSDs nutzbar.
Ceph nutzt Replikation, um Datenverluste zu verhindern. Jeder Pool erhält beim Anlegen einen Replikationsfaktor, der bestimmt, wie viele Kopien eines Objekts im Cluster existieren. Die Selbstheilungsmechanismen sichern die Integrität der Daten. Weicht ein Objekt von der referenzierten Version ab oder fällt ein OSD aus, kopiert Ceph automatisch eine gültige Kopie an einen neuen Ort. Verschlüsselung auf Blockebene erhöht den Schutz sensibler Informationen. Schlüssel und Zugriffsrechte verwaltet das System über CephX. Für jeden Nutzer lassen sich eigene Zugriffsprivilegien definieren.
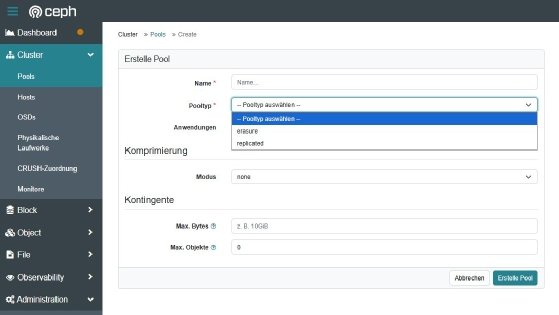
Pools bilden die logische Grundlage für Objektgruppen. Das Dashboard liefert eine strukturierte Ansicht der vorhandenen Ressourcen und bietet die Option zur Erstellung neuer Pools mit eigener Replikationsstrategie. Snapshots sichern einzelne RBD-Volumes oder CephFS-Verzeichnisse. Sie eignen sich zur schnellen Wiederherstellung definierter Zustände. Backups lassen sich auf externe Ziele verschieben.
Integration in Kubernetes mit Rook
Für Nutzer, die Ceph in Kubernetes nutzen, steht Rook als Operator zur Verfügung. Die Einrichtung folgt dem bekannten Schema. Nach dem Klonen des Projekts und dem Anlegen der CRDs startet der Operator und erkennt das Ceph-Cluster automatisch. StorageClasses für RBD oder CephFS integrieren die Pools in Container-Workloads. Der Operator steuert Skalierung, Selbstheilung und Statusabfragen vollständig im Kubernetes-Kontext.
kubectl create -f crds.yaml -f common.yaml -f csi-operator.yaml -f operator.yaml
kubectl create -f cluster-test.yamlNach dem Start aller Pods stehen dynamisch erzeugte Volumes bereit. Eine Toolbox liefert Zugriff auf die Ceph-Kommandos innerhalb des Clusters.
kubectl apply -f toolbox.yaml
kubectl -n rook-ceph exec -it rook-ceph-tools – bash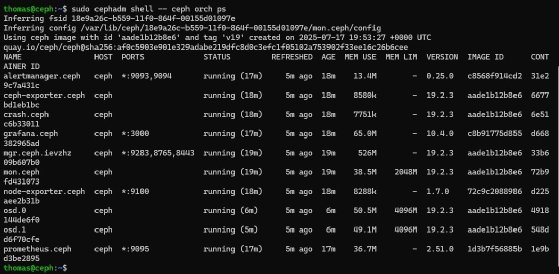
Praxisnutzen und typische Einsatzszenarien
Ein Ceph-Cluster auf Ubuntu eignet sich für Laborszenarien, Testinstallationen oder produktionsnahe Speicheranforderungen. Mehrere Pools für RBD, CephFS und Objektspeicher lassen sich parallel betreiben. Durch die flexible Architektur wächst das Cluster einfach mit. Zusätzliche Geräte oder Nodes erhöhen den verfügbaren Speicher und verbessern die Ausfallsicherheit. Die vollständige Steuerung über Dashboard und CLI liefert ein präzises Bild des aktuellen Zustands und ermöglicht eine feinkörnige Verwaltung aller Komponenten.
Sowohl kleine Entwicklungsumgebungen als auch größere Infrastrukturen profitieren von der Architektur. Ein grundlegender Aufbau auf einem einzigen Host erlaubt spätere horizontale Erweiterungen ohne strukturelle Änderungen. Ceph bildet damit eine konsistente Grundlage für sämtliche Speicheranforderungen in lokalen Rechenzentren und selbst betriebenen Kubernetes-Installationen.




