
Framestock - stock.adobe.com
Proxmox VE: Metrikexport und Monitoring im Cluster
Proxmox VE exportiert Cluster-, Host-, SDN- und Gastsystemdaten an externe Collector-Systeme und liefert eine belastbare Grundlage für Analyse, Fehlersuche und Kapazitätsplanung.

Ein Proxmox-Cluster liefert fortlaufend Zustandsinformationen. Der interne Statusdienst sammelt CPU-Daten, Speicherauslastung, Storage-I/O, Netzwerkverkehr, VM-Aktivität und Vorgänge wie Migration, Backup oder HA-Reaktionen. Diese Werte bleiben im Standardumfang auf kurze Zeiträume begrenzt. Erst ein externer Collector erlaubt den Blick auf längere Verläufe, Korrelationen zwischen Knoten, Spitzenlasten und Auffälligkeiten in den einzelnen Subsystemen.
Der Export läuft auf jedem Host unabhängig. Die Konfiguration liegt im Datacenter und wandert automatisch zu allen Knoten. Dadurch greifen sämtliche Hosts auf dieselben Vorgaben zu. Nach der Aktivierung sendet der Proxmox-Cluster ohne Verzögerung die ersten Daten.
Metric-Server im Data Center einrichten: InfluxDB, Graphite, Open Telemetry
Die Verwaltung des Exports erfolgt über Datacenter/Metric Server. Ein Klick auf Edit öffnet das Dialogfenster. Dort legt man fest, an welches System die Metriken übertragen werden. Neue Verbindungen werden mit Add erstellt. Zur Auswahl stehen Graphite, InfluxDB und Open Telemetry.
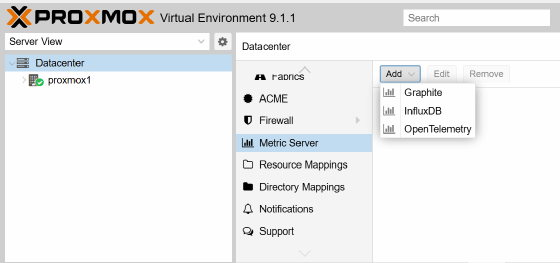
Jede dieser drei Varianten bildet einen eigenen technischen Ansatz ab und erweitert Proxmox um unterschiedliche Analyse- und Integrationsmöglichkeiten. Graphite konzentriert sich auf einen textbasierten Datenpfad. Die Messwerte fließen in einem zeilenorientierten Format zum Collector und lassen sich ohne komplexe Anforderungen verarbeiten. Diese Struktur eignet sich für Umgebungen, die einfache Zeitreihen voraussetzen und ein robustes System mit geringer Fehleranfälligkeit bevorzugen. Dashboards arbeiten mit den gelieferten Kurven und ermöglichen eine schnelle Diagnose der Lastzustände. Die geringe Protokollkomplexität sorgt im Betrieb für einen transparenten Datenfluss, der auch große Cluster ohne zusätzlichen Verwaltungsaufwand abbildet.
Das steckt hinter InfluxDB, Graphit und Open Telemetry
InfluxDB speichert die Messwerte in einer Zeitreihendatenbank. Die Daten erhalten Tags, über die sich einzelne Quellen, Knoten, VM-IDs, Interfaces oder Storage-Subsysteme voneinander trennen lassen. Dadurch entstehen umfangreiche Analysewege, weil sich Messpunkte nach Kategorien filtern, gruppieren oder verdichten lassen. Dieser Ansatz unterstützt auch komplexere Auswertungen, bei denen sich mehrere Messreihen logisch zueinander verhalten müssen, zum Beispiel bei der Suche nach Korrelationen zwischen CPU-Last, Storage-Latenz und Netzwerkverkehr. Gleichzeitig verbessert die Struktur die Kapazitätsplanung, da Trends aus historischen Daten abgeleitet werden können.
Open Telemetry ergänzt beide Varianten, weil es als offenes Telemetrie-Framework konzipiert ist und Metriken nicht nur speichert, sondern über standardisierte Schnittstellen verteilt. Dadurch lassen sich breitere Integrationspfade in externe Observability-Plattformen aufbauen. Die Daten können ohne proprietäre Bindung an ein einzelnes Backend weitergeleitet werden, zum Beispiel an verteilte Messplattformen oder Systeme, die zusätzlich Logs und Traces einbeziehen. Open Telemetry öffnet die Tür zu einem einheitlichen Beobachtungsmodell, bei dem Proxmox nicht isoliert überwacht wird, sondern Teil einer umfassenden Infrastrukturdiagnose ist. Das erleichtert die Analyse verteilter Anwendungen, die sich über mehrere Cluster und Dienste erstrecken.
Alle drei Lösungen lassen sich kombinieren. Jede Variante erzeugt eigene Messreihen, die parallel zu den anderen exportiert werden können. Ein Cluster kann Graphite für Standardmetriken nutzen, InfluxDB für Zeitreihenanalysen und Open Telemetry für die Weitergabe in übergeordnete Monitoring- oder Observability-Systeme. Trifft eine Lösung auf einen Engpass, stehen die anderen weiterhin zur Verfügung. Das Ergebnis ist ein Monitoring-Modell, das sowohl klassische Zeitreihen als auch moderne Telemetriestrukturen unterstützt und damit sämtliche Anforderungen von Grundüberwachung bis zu komplexer Infrastrukturdiagnostik abdeckt.
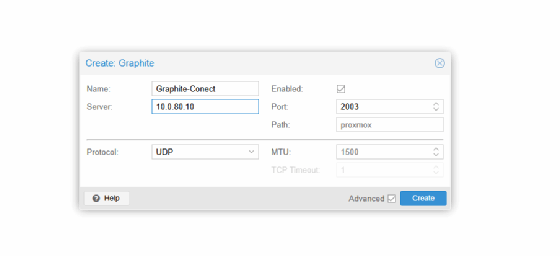
Konfiguration für Graphite
Graphite empfängt Textzeilen über TCP. Nach der Auswahl von Graphite folgen drei Angaben. Das Feld Server erhält die IP-Adresse des Zielsystems. Port bleibt bei 2003, sofern die Gegenstelle standardkonform arbeitet. Protocol steht weiterhin auf tcp. Nach dem Speichern beginnt die Übertragung sofort.
Um die Netzwerkverbindung zu prüfen, öffnet man die Shell eines Knotens und führt telnet <ip> 2003 aus. Eine erfolgreiche Verbindung zeigt, dass die Datenpfade stehen. Die ersten Werte erscheinen danach im Graphite-Verzeichnisbaum. Jeder Node besitzt ein eigenes Präfix. Dadurch lassen sich CPU-Werte, RAM-Last, Netzwerkstatistiken, Storage-Messpunkte und alle VM-Serien eindeutig zuordnen.
Konfiguration für InfluxDB
InfluxDB arbeitet über HTTP oder UDP. Für eine HTTP-Anbindung trägt man die Adresse des Servers ein, gefolgt vom Port 8086. Danach folgt der Name der gewünschten Datenbank. Sobald die Konfiguration gespeichert ist, öffnen sich die Messpunkte in Grafana oder jedem anderen Influx-Client.
Ein kurzer Test erfolgt über curl -i http://<ip>:8086/ping. Eine gültige Antwort bestätigt die Erreichbarkeit. InfluxDB legt alle Messwerte mit Tags an. Dadurch lassen sich Daten nach Node, VM-ID, Interface, Storage oder Kategorie filtern. Der Cluster erzeugt ohne zusätzliche Schritte eine vollständige Struktur für Host-Last, Netzwerkdaten, Speicherzugriffe und VM-Aktivität.
Zur Kontrolle der exportierten Daten lohnt ein Blick in die Shell des jeweiligen Knotens. Dort lassen sich alle Messgrundlagen ansehen, die später im Collector erscheinen.
cat /proc/loadavg zeigt die aktuelle Lastverteilung.
cat /proc/meminfo liefert detaillierte Speicherinformationen.
pvesm status listet Storage-Zustände, Kapazitäten und Reaktionswerte.
Diese lokalen Abfragen eignen sich, um Abweichungen im Monitoring einzuordnen. Viele Leistungsprobleme kündigen sich durch schleichende Erhöhungen der Speicherauslastung oder durch längere Plattenzugriffszeiten an. Ein externer Collector macht diese Trends sichtbar, weil dort auch Wochen oder Monate erfasst werden.
Metrikexporte gezielt testen und Fehlerquellen systematisch eingrenzen
Nach der Einrichtung des Metric-Servers lohnt es sich, den Exportpfad vollständig durchzugehen, um sicherzustellen, dass alle Hosts tatsächlich Daten übertragen. Als erster Schritt bietet sich eine direkte Prüfung der Konfigurationsdatei an. Die Datei /etc/pve/status.cfg enthält die aktive Definition des Metric-Servers und zeigt unmittelbar, ob die Einträge korrekt im Cluster angekommen sind. Ein kurzer Blick mit einem Editor oder über cat /etc/pve/status.cfg macht sichtbar, welche Protokolle, Ports und Serveradressen aktuell gelten.
Anschließend folgt ein praktischer Live-Test. Auf einem beliebigen Knoten lässt sich ein einzelner Messpunkt auslösen, indem der Dienst pvestatd neu gestartet wird. Der Befehl systemctl restart pvestatd erzwingt eine sofortige Aktualisierung der internen Messwerte und damit einen direkten Export. Für InfluxDB bietet sich zusätzlich ein Aufruf über die integrierte API des Collectors an. Der Befehl
curl http://<influx>/query?db=<datenbank>&q=SHOW+SERIES
listet alle aktuell geschriebenen Serien auf und zeigt damit sehr schnell, ob der Exportpfad vollständig arbeitet. Falls keine Daten erscheinen, lässt sich das Problem oft auf einen der Kernbereiche eingrenzen. Eine falsche Uhrzeit auf einem Host führt zu Messpunkten außerhalb des sichtbaren Fensters. Ein fehlender DNS-Eintrag sorgt dafür, dass der Zielserver nicht erreichbar ist. Auch falsch gesetzte Firewall-Einstellungen blockieren häufig TCP-Port 2003 oder HTTP/8086. Daher sollten alle Knoten einmal über ping, telnet und curl den direkten Zugriff auf den Metric-Server prüfen. Erst wenn diese grundlegenden Tests eindeutig funktionieren, steht einem konsistenten Export aller Clusterwerte nichts im Weg.
Metriken von VMs und Containern erfassen
Proxmox erzeugt für jede VM und jeden Container separate Messreihen. Die Werte stammen aus der Virtualisierungsschicht und erscheinen als CPU-Last, RAM-Verbrauch, Disk-I/O und Netzdurchsatz. Beim Einsatz von InfluxDB werden alle Serien mit Tags versehen, sodass sich die Daten gezielt pro VM filtern lassen.
Nach einer Migration setzt die Messkurve auf dem Zielknoten fort. Dadurch entsteht ein Verlauf, der erkennbar macht, wann ein Gast verschoben wurde, wie hoch die Last während einer Migration war oder ob eine VM nach einer Änderung auffällig reagiert hat. Diese Nachvollziehbarkeit ist hilfreich, wenn mehrere Knoten in kurzer Abfolge Migrationen oder Replikationen ausführen.
Storage-Überwachung und I/O-Analyse
Im Clusterbetrieb sind Storage-Werte wichtig. ZFS liefert ARC-Statistiken (Adaptive Replacement Cache), LVM-Volumes melden Durchsatzdaten, Ceph übermittelt seinen Status über interne Abfragen. Auf der Shell eines Knotens lassen sich diese Werte jederzeit verifizieren. Bei ZFS liefert zpool status die Informationen über Zustand und Last. Bei Ceph zeigt ceph -s den Zustand der Monitore, OSDs (Object Storage Daemon) und Pools an.
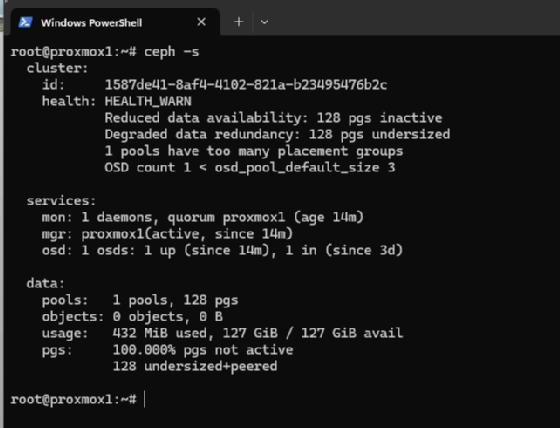
Sobald der Export aktiv ist, erscheinen diese I/O-Zustände im Monitoring. Dadurch lässt sich erkennen, ob einzelne OSDs überlastet sind, ob Snapshots im falschen Moment erzeugt wurden oder ob Backup-Fenster das Storage stärker beanspruchen als erwartet.
Für Backup-Ziele bietet sich zusätzlich der Befehl proxmox-backup-client benchmark an. Er prüft den Durchsatz eines Ziels und zeigt unmittelbar, ob ein Engpass vorliegt. Dieser Engpass wird parallel in Form eines I/O-Anstiegs im Collector sichtbar.
Netzwerk-Monitoring im Cluster-Umfeld
Netzwerkdaten gehören zu den wichtigsten Metriken im Cluster. Die Mehrheit aller Vorgänge verläuft über das Netzwerk: Migrationen, Replikationen, HA-Operationen, SDN-Verkehr, DHCP-Leases, Ceph-Synchronisation und API-Kommunikation. Die Shell liefert alle nötigen Prüfwerte.
ip -s link zeigt Paketraten und Fehler.
ethtool <interface> liefert Zusatzinformationen über Geschwindigkeit und Treiberzustände.
Sobald Graphite oder InfluxDB aktiv ist, fließen diese Daten ebenfalls in die Zeitreihen. Bond-Verbindungen, Bridges, VLAN-Interfaces und SDN-VNets erscheinen dann als separate Serien. Dadurch lassen sich Latenzverläufe und Unregelmäßigkeiten eindeutig zuordnen.
SDN erweitert die Überwachung deutlich. Proxmox erzeugt pro Zone eine eigene Netzwerklogik. Jede Zone verwaltet DHCP-Bereiche, Gateways, Subnetze und optional Routing. Daraus ergibt sich ein zusätzlicher Satz an Messpunkten, die für ein vollständiges Monitoring unverzichtbar sind.
DHCP-Daten aus dnsmasq beobachten
dnsmasq arbeitet zonenweise. Jede Zone erhält einen eigenen Dienst mit eigener Konfiguration. Beim Start eines Containers oder einer VM erzeugt der DHCP-Dienst neue Leases. Der Netzwerkverkehr im entsprechenden VNet nimmt sichtbar zu. Diese Bewegungen erscheinen ebenfalls im externen Monitoring.
Ein Blick auf die Shell zeigt, ob die Dienste aktiv sind. Der Aufruf systemctl status dnsmasq deckt den lokalen Zustand ab. Die SDN-Struktur erzeugt allerdings eigene Instanzen, die Proxmox verwaltet. Sobald neue Leases verteilt werden, wandern die Änderungen in die exportierten Netz- und CPU-Serien.
Routingdaten aus FRRouting einbeziehen
FRRouting steuert den Austausch von Routinginformationen. In SDN-Zonen mit dynamischer Topologie übernimmt dieser Dienst die Verwaltung von BGP- oder OSPF-Beziehungen. Sobald eine Route fehlt oder sich eine Nachbarschaft ändert, erzeugt der Host zusätzliche Last. Diese Last ist im externen Monitoring sichtbar, weil CPU- und Netzweraktivität der Routing-Instanz steigen.
Eine schnelle Kontrolle erfolgt über systemctl status frr.service. Die Metriken im Collector erlauben anschließend Rückschlüsse auf typische Probleme, etwa instabile Links oder fehlerhafte IP-Bereiche.




