
your123 - stock.adobe.com
Hochverfügbarkeit mit Promox VE: HA-Cluster aufbauen
Proxmox VE wird hochverfügbar, wenn ein Quorum steht und die Kommunikation stabil läuft. Failover bei Störung Switchover für Wartung und Live Migration halten Dienste verfügbar.

Hochverfügbarkeit in Proxmox VE basiert auf einem Zusammenspiel aus Cluster-Dateisystem pmxcfs, Corosync-Kommunikation, Quorum-Logik und dem HA-Manager. Alle beteiligten Knoten agieren als gleichberechtigte Mitglieder eines Verbunds. Steuerungsinformationen liegen nicht lokal, sondern synchronisiert im Cluster-Dateisystem. Entscheidungen über Start, Stop, Neustart oder Verschiebung von virtuellen Maschinen erfolgen zustandsbasiert und nicht durch einzelne Hosts. Voraussetzung für jeden HA-Mechanismus ist ein funktionsfähiges Quorum. Ohne Quorum blockiert Proxmox VE sämtliche clusterweiten Aktionen.
Clusterknoten synchronisieren sich mit Corosync
Corosync bildet die zentrale Kommunikationsschicht eines Proxmox-Clusters und stellt den zuverlässigen Nachrichtenaustausch zwischen allen Knoten sicher. Der Dienst übernimmt die Cluster-Mitgliedschaft, verteilt Statusinformationen und berechnet das Quorum. Alle Knoten tauschen über Corosync in kurzen Intervallen Heartbeats aus, um Erreichbarkeit und Konsistenz des Verbunds festzustellen. Fällt ein Knoten aus oder verliert die Verbindung, erkennt Corosync diesen Zustand und aktualisiert den Clusterstatus entsprechend.
Im Proxmox-Kontext nutzt das Cluster-Dateisystem pmxcfs Corosync als Transportmechanismus. Konfigurationsdaten unter /etc/pve werden über Corosync synchronisiert und stehen damit auf allen Knoten identisch zur Verfügung. Änderungen an Firewall-Regeln, Storage-Definitionen, HA-Parametern oder SDN-Konfigurationen propagieren dadurch ohne manuelle Eingriffe im gesamten Cluster. Die Firewall-Regelverteilung und die Konsistenz von IP-Sets hängen direkt von dieser Synchronisation ab.
Das Quorum verhindert widersprüchliche Zustände im Cluster. Nur wenn eine Mehrheit der Knoten erreichbar ist, erlaubt Proxmox VE Änderungen an Konfigurationen, Migrationen oder HA-Aktionen. Bei fehlendem Quorum blockiert das System diese Vorgänge, um parallele Schreibzugriffe oder inkonsistente Entscheidungen zu vermeiden. Funktionen wie Live Migration, HA-Manager und Firewall-Aktivierung setzen daher einen funktionierenden Corosync-Verbund voraus.
Technisch arbeitet Corosync auf IP-Basis und unterstützt redundante Kommunikationspfade. In Proxmox VE erfolgt die Anbindung üblicherweise über ein dediziertes Cluster-Netz, das geringe Latenz und stabile Erreichbarkeit liefert. Diese Architektur stellt sicher, dass alle clusterweiten Mechanismen deterministisch arbeiten und die Sicherheits- und Netzwerkregeln jederzeit auf einem konsistenten Stand bleiben.
Aufbau eines Proxmox-Clusters
Der Aufbau beginnt mit mindestens zwei Proxmox-Knoten, produktiv sinnvoll sind drei, um Quorum-Verluste bei Ausfall eines Knotens zu vermeiden. Alle Systeme müssen dieselbe Proxmox-Version verwenden und über eine stabile Netzwerkverbindung verfügen. Nach der Installation erfolgt die Cluster-Erstellung auf einem ersten Knoten über die Shell mit
pvecm create <Clustername>
Dabei wird Corosync initialisiert und das Cluster-Dateisystem eingerichtet. Die Netzwerkschnittstelle für Corosync muss zuvor eindeutig festgelegt sein, idealerweise ein dediziertes Netzwerk.
Weitere Knoten treten dem Cluster über
pvecm add <IP-Adresse-des-ersten-Knotens>
bei. Während dieses Vorgangs synchronisiert Proxmox die Cluster-Konfiguration vollständig. Nach dem Beitritt zeigt
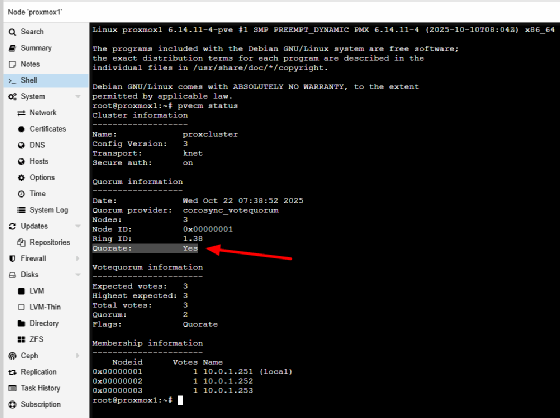
pvecm status
den Quorum-Zustand. Der Wert Quorate muss auf Yes stehen. Erst dann gelten Clusterfunktionen als aktiv.
Gemeinsames oder repliziertes Storage als Basis
Für Hochverfügbarkeit benötigen virtuelle Maschinen einen Speicher, der auf mehreren Knoten verfügbar ist. Gemeinsames Storage wie Ceph, NFS oder iSCSI erfüllt diese Anforderung direkt. Alternativ kommt lokaler ZFS-Speicher mit Replikation zum Einsatz. In diesem Fall besitzt jeder Knoten einen identischen ZFS-Pool-Namen. Proxmox VE nutzt ZFS-Snapshots, um inkrementelle Änderungen zu übertragen. Die Replikation richtet man zentral über den Menüpunkt Datacenter und dort Replication ein. Die konkrete Zuordnung erfolgt pro VM. Ohne funktionierende Replikation kann der HA-Manager eine VM nach einem Knotenausfall nicht starten.
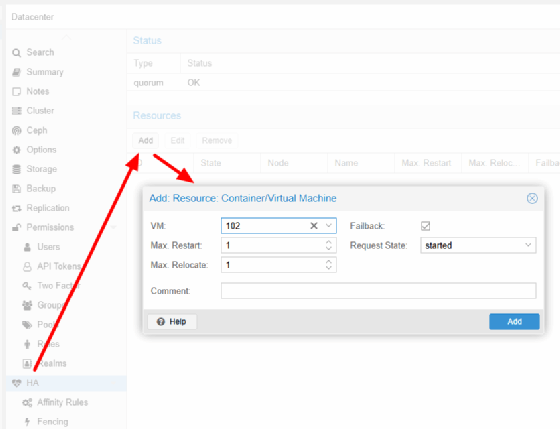
Anlegen einer HA-Ressource
Die eigentliche Aktivierung der Hochverfügbarkeit erfolgt über Datacenter und HA. Unter Resources wird über Add eine neue Ressource angelegt. Hier wählt man die virtuelle Maschine aus. Mit Max Restart wird definiert, wie oft Proxmox einen automatischen Neustart auf demselben Knoten versucht. Max Relocate legt fest, wie oft ein automatisches Verschieben auf einen anderen Knoten erlaubt ist. Beide Werte sollten bewusst niedrig bleiben. Request State steht im Normalbetrieb auf started. Ab diesem Moment steuert nicht mehr der Administrator den Laufzustand, sondern der HA-Manager.
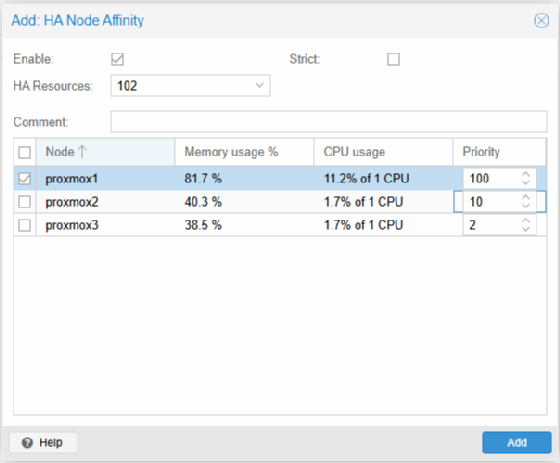
Node Affinity gezielt konfigurieren
Die bevorzugte Platzierung einer VM wird über Datacenter, HA und Affinity Rules gesteuert. Unter Node Affinity weist man der HA-Ressource pro Knoten eine Priorität zu. Der Knoten mit dem höchsten Wert gilt als bevorzugter Standort. Läuft eine VM mit Priorität 100 auf proxmox1 und Priorität 10 auf proxmox2, startet sie regulär auf proxmox1. Fällt dieser aus, übernimmt proxmox2 automatisch. Nach Wiederkehr von proxmox1 erfolgt ein Rückschwenk nur dann, wenn die Prioritäten unterschiedlich sind. Gleiche Werte verhindern ein automatisches Zurückverschieben und stabilisieren den Betrieb.
Resource Affinity für logische Trennung oder Bündelung
Zusätzlich lassen sich Abhängigkeiten zwischen mehreren VMs definieren. Über Resource Affinity Rules wird festgelegt, ob VMs gemeinsam oder getrennt laufen. Die Einstellung Keep Together zwingt mehrere Ressourcen auf denselben Knoten. Keep Separate sorgt dafür, dass sie niemals auf demselben Host gestartet werden. Diese Regel greift sowohl im Normalbetrieb als auch bei Failover-Entscheidungen. Damit lassen sich Redundanzen technisch erzwingen, ohne auf externe Orchestrierung zurückzugreifen.
Replikation für lokale ZFS-Umgebungen
Bei lokalem Storage ist Replikation zwingend erforderlich. Die Einrichtung erfolgt über den Menüpunkt Replication der jeweiligen VM oder zentral über Datacenter. Nach Auswahl des Zielknotens wird ein Zeitplan definiert. Typisch sind Intervalle von fünfzehn bis sechzig Minuten. Proxmox erstellt Snapshots und überträgt nur geänderte Blöcke. Der Status muss auf OK stehen. Nur dann betrachtet der HA-Manager das Ziel als gültige Startoption im Fehlerfall.
Live Migration als kontrolliertes Werkzeug
Live Migration ergänzt Hochverfügbarkeit um geplante Eingriffe. Über das Kontextmenü der VM und Migrate verschiebt Proxmox VE eine laufende Maschine auf einen anderen Knoten. Bei gemeinsamem Storage erfolgt ausschließlich eine Speicher- und Zustandsübertragung. Bei lokalem Storage mit Replikation reduziert sich die Übertragungsmenge erheblich. In der Shell erfolgt der Vorgang mit
qm migrate 102 proxmox1 --online
Optional lassen sich lokale Disks mit
--with-local-disks
einbeziehen oder die Bandbreite mit
--bwlimit 50
begrenzen. Eine erfolgreiche Migration endet mit TASK OK.
Failover-Logik im Fehlerfall
Ein Failover unterscheidet sich grundlegend von einer Migration. Corosync erkennt den Ausfall eines Knotens und aktualisiert den Quorum-Zustand. Der HA-Manager prüft anschließend alle betroffenen Ressourcen. Ist Max Restart noch nicht ausgeschöpft, erfolgt zunächst ein Neustart. Scheitert dieser oder ist der Knoten nicht erreichbar, greift Max Relocate. Die VM startet auf einem anderen Knoten gemäß Node- und Resource-Affinity. Ohne Quorum findet kein Failover statt, um widersprüchliche Zustände zu verhindern.
Bewährte Praxis für stabile Cluster
Ein stabiler HA-Cluster nutzt klare Prioritäten, wenige automatische Versuche und konsistente Storage-Konzepte. Node Affinity definiert den Normalzustand, Resource Affinity erzwingt logische Regeln. Replikation stellt die Datenbasis bereit. Live Migration dient der Wartung. Hochverfügbarkeit in Proxmox arbeitet deterministisch, transparent und reproduzierbar, sofern alle Schritte sauber konfiguriert sind und der Cluster dauerhaft stabil bleibt.
Erfahren Sie mehr über Server- und Desktop-Virtualisierung
-
![]()
Technische Hardening-Maßnahmen für Proxmox VE 9 Hosts
Von: Thomas Joos
-
![]()
Proxmox VE: Die Firewall für Cluster-Betrieb konfigurieren
Von: Thomas Joos
-
![]()
Ceph in Proxmox VE integrieren: Schritt-für-Schritt Anleitung
Von: Thomas Joos
-
![]()
Die 9 wichtigsten Blockchain-Plattformen für Unternehmen
Von: George Lawton



