Diese Speichertypen eignen sich für Serverless Computing
Der Speicher für serverlose Funktionen muss außerhalb der Rechenumgebung liegen. Erfahren Sie mehr über die Speichertypen, die am besten für Serverless Computing geeignet sind.
Was ist Serverless Computing und wie funktioniert Serverless Storage? Grundsätzlich ist „serverlos“ eine Möglichkeit, eine Anwendung als eine Reihe kleinerer funktionaler Komponenten zu entwickeln und diese Funktionen dann an einen Hostdienst zur elastisch skalierbaren ereignisgesteuerten Ausführung zu übergeben. Der Dienstleister übernimmt die Skalierung und den Betrieb des gesamten darunter liegenden IT-Stacks, so dass sich der Anwender mehr auf die Geschäftsprozesse und weniger auf den IT-Betrieb konzentrieren kann.
Da der Dienstanbieter pro Funktionsausführung und nicht für reservierte Infrastrukturen berechnet, passen sich die serverlosen Betriebskosten vollständig der Anwendungsnutzung an. Mit Serverless können Cloud-Kosten direkt auf Anwendungen und Geschäftskunden zurückgeführt werden.
Serverless ist nicht wirklich ohne Server; es gibt einen Server in einer Cloud. Hinter den Kulissen gibt es wahrscheinlich virtuelle Maschinen, Container, Server und Speicher. Es gibt Betriebssystem- und Anwendungsservercode und IT-Verwaltungsebenen, die Cloud Orchestrierung, virtuelles Hosting und Containerverwaltung enthalten können, wie beispielsweise Kubernetes. Der Dienstleister kümmert sich um alle Netzwerk-, Verfügbarkeits-, Leistungs-, Kapazitäts- und Skalierbarkeitsprobleme, mit denen sich ein IT-Shop beim Hosting seiner eigenen Anwendungen normalerweise auseinandersetzen muss.
Funktionalitäten als Service
Ein besserer Name für all dies könnte „Function as a Service“ sein. Im einfachsten Fall ist diese Art von Funktion ein kleines Stück ereignisgesteuerten Codes, vielleicht in JavaScript geschrieben, der so eingerichtet ist, dass er als Reaktion auf einen Auslöser wie einen Klick auf ein Web-Formular oder ein IoT-Geräteereignis aufgerufen wird. Einfache Funktionen können einen Datensatz in eine Datenbank einfügen, einen Protokolleintrag vornehmen, ein anderes Ereignis auslösen, eine Benachrichtigung senden, eine Datentransformation durchführen oder eine Kalkulation zurückgeben.
Eine komplette serverlose Anwendung würde aus einer gut organisierten Kaskade von Funktionen bestehen. Jede Funktion könnte unabhängig voneinander wiederverwendet und großflächig parallel ausgelöst werden. Die Ausführung einer Funktion kann orthogonal von anderen Funktionen skaliert werden, was eine enorme Flexibilität ohne traditionelle Engpässe ermöglicht.
Wenn ein gut durchdachtes Masterdiagramm von Funktionen, die sich gegenseitig in einer sinnvollen Kaskade von Ereignissen auslösen lassen, maßstabsgetreu eingesetzt wird, kann es monolithische Anwendungen nicht nur ersetzen, sondern übertreffen. Eine der Voraussetzungen von Serverless ist, dass Ihre Anwendungen reibungslos skalierbar und voll elastisch sind, weit über die Grenzen einer vordefinierten oder vorausbezahlten Serverfarm oder einer Reihe von Cloud-Maschineninstanzen hinaus.
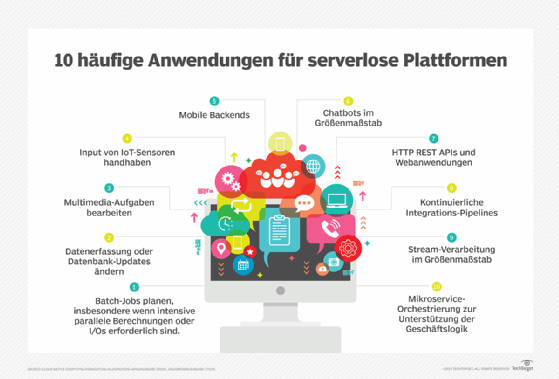
Abbildung 1: Zehn bekannte Anwendungsgebiete für Serverless Computing
Das ist noch etwas futuristisch, denn natürlich bestehen Anwendungen nicht nur aus Rechenfunktionen. Es gibt noch immer Daten, die verwaltet, geschützt und persistent gehalten werden müssen. Storage für Serverless Computing muss genau betrachtet und dann effektives serverloses Storage entwickelt werden.
Speicher für Serverless Computing
Wie Microservices in Containern besteht die Grundidee für serverlose Funktionen darin, sie vergänglich, also für kurzfristige Nutzung zu konstruieren, so dass sie keine Daten enthalten und nicht darauf angewiesen sind, dass sie intern persistente Daten enthalten.
Im Gegensatz zu lang laufenden Anwendungen geht es darum, dass Funktionen durch ein Ereignis ausgelöst werden, etwas Bestimmtes tun und ausgemustert werden, anstatt eine langlebige Anwendung zu werden. Serverless Computing funktioniert parallel und kann massiv parallel gestartet werden, um schnell und bedarfsgerecht zu skalieren. Wo residieren also serverlose Daten?
Effektiv muss die Datenspeicherung für serverlose Funktionen außerhalb der Rechenumgebung erfolgen. Aufgrund der elastischen Skalierung und kleiner Ereigniskaskaden werden traditionelle Speicher-Volumes und Dateisysteme problematisch und zu offensichtlichen Engpässen in großen, serverlosen App-Deployments werden.
Das serverlose Ideal ist es, die IT und DevOps von der Verwaltung und dem Betrieb von Servern jeglicher Art, einschließlich physischer Server, virtueller Server, Container und Cloud-Instanzen, zu befreien.
Heute können serverlose Funktionsentwicklungsumgebungen direkt auf Storage-Service-APIs zurückgreifen. Als skalierbarer Speicher, der sich für webbasierte und containerisierte Anwendungen eignet, sind Cloud-Data-Services ideale Datenpersistenz-Partner. Hier sind die Speichertypen, die gut als Speicher für Serverless funktionieren:
Cloud-Datenbankdienste, die für Mandantenfähigkeit, elastische Skalierbarkeit und webbasierten Zugriff ausgelegt sind und transaktionale Persistenz gewährleisten.
Objektspeicherdienste wie AWS S3 mit einfachen Get/Put-Protokollen sind ideal für viele Arten von webbasierten Anwendungen und funktionalen Designs.
Application Memory Cache, wie zum Beispiel Redis, kann für den Hochleistungs-Datenaustausch eingesetzt werden.
Aufzeichnungsprotokolle (Journaling), in denen Daten seriell bis zum Ende geschrieben werden, während sie in ihrer Gesamtheit lesbar sind, können helfen, Streaming-Daten in funktionalen Designs zu schützen.
Bei der Verwendung eines Datenspeichers mit serverbasierten Designs muss mit größter Sorgfalt auf die Idempotenz geachtet werden – eine Operation, die bei mehrfacher Anwendung keine zusätzliche Wirkung hat. Auch bei asynchronen Ereignisannahmen und Zeit- oder Laufbedingungen ist Vorsicht geboten. Insbesondere müssen funktionale Designs auf parallele Datenaktualisierungen und Schreibsperrbedingungen achten.
Was genau ist also Serverless Storage?
Das serverlose Ideal ist es, die IT – und DevOps – von der Verwaltung und dem Betrieb von Servern jeglicher Art, einschließlich physischer Server, virtueller Server, Container und Cloud-Instanzen, zu befreien. Die Idee besteht darin, die IT zu zwingen, die Verantwortung für alle betrieblichen Belange an den Anbieter von serverlosen Umgebungen zu übergeben. Wenn ein Unternehmen serverlos arbeitet, geht es letztendlich darum, auch den Betrieb und die Verwaltung von Storage einzustellen.
Gemeinsame Anforderungen an die IT zur Gewährleistung von Data Governance, Compliance und Schutz werden jedoch eine lange Zeit hybrider geschützter Speicherarchitekturen erfordern. Und auf lange Sicht? Daten könnten nur von Funktion zu Funktion über die Ereigniswarteschlange weitergeleitet werden und bleiben nie persistent, da sie sich auf den Ereigniswarteschlangen-Service für die Data Protection verlassen. Aber natürlich gibt es da drin immer noch irgendwo einen Speicher.