Paralleles Dateisystem (Parallel File System)
Was ist ein paralleles Dateisystem?
Ein paralleles Dateisystem ist eine Softwarekomponente, die dazu dient, Daten auf mehreren vernetzten Servern zu speichern. Es ermöglicht einen leistungsstarken Zugriff durch gleichzeitige, koordinierte Ein-/Ausgabeoperationen (I/Os) zwischen Clients und Speicherknoten.
Parallele Dateisysteme können Tausende von Serverknoten umfassen und Petabytes oder Exabytes an Daten verwalten. In der Regel setzen Anwender Hochgeschwindigkeitsnetzwerke wie InfiniBand, Omni-Path oder moderne Ethernet-Varianten (zum Beispiel 40/100 Gbit) ein, um den I/O-Pfad zu optimieren und eine größere Bandbreite zu ermöglichen.
Wie funktioniert ein paralleles Dateisystem?
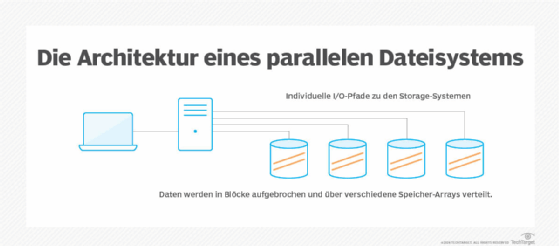
Parallele Dateisysteme teilen einen Datensatz auf und verteilen die Blöcke auf mehrere Speicherlaufwerke, die sich auf lokalen und externen Servern befinden. Benutzer müssen den physischen Speicherort der Datenblöcke nicht kennen, um eine Datei abzurufen. Die Systeme verwenden einen globalen Namensraum, um den Datenzugriff zu erleichtern.
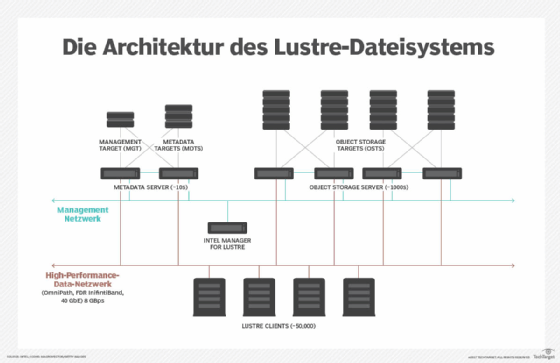
Diese Systeme verwenden häufig einen oder mehrere Metadatenserver, um Informationen über die Daten zu speichern, wie zum Beispiel den Dateinamen, den Speicherort und den Eigentümer. Moderne parallele Dateisysteme wie Lustre oder IBM Spectrum Scale (GPFS) setzen mehrere Metadatenserver ein, um Engpässe zu vermeiden.
Ein paralleles Dateisystem liest und schreibt Daten auf verteilte Speichergeräte unter Verwendung mehrerer I/O-Pfade gleichzeitig als Teil eines oder mehrerer Prozesse eines Computerprogramms. Die koordinierte Verwendung mehrerer I/O-Pfade kann einen erheblichen Leistungsvorteil bieten, insbesondere beim Streaming von Workloads, an denen viele Clients beteiligt sind.
Kapazität und Bandbreite können skaliert werden, um enorme Datenmengen und unterschiedliche Anforderungen von Rechenzentren zu bewältigen. Zu den Speicherfunktionen gehören Hochverfügbarkeit, Spiegelung, Replikation und Snapshots.
Häufige Anwendungsfälle für parallele Dateisysteme
Parallele Dateisysteme sind in der Regel für HPC-Umgebungen (High Performance Computing) vorgesehen, die den Zugriff auf große Dateien, riesige Datenmengen oder den gleichzeitigen Zugriff von mehreren Rechenservern erfordern.
Zu den Nutzern paralleler Dateisysteme zählen nationale Laboratorien, Behörden und Universitäten sowie Branchen wie Finanzdienstleistungen, Biowissenschaften, Fertigung, Medien, Unterhaltung sowie Öl und Gas.
Zu den Anwendungsbereichen gehören:
- Klimamodellierung
- Computergestütztes Engineering
- Explorative Datenanalyse
- Finanzmodellierung
- Genomsequenzierung
- Maschinelles Lernen (ML) und künstliche Intelligenz (KI)
- Seismische Datenverarbeitung
- Videobearbeitung und Rendering visueller Effekte
Paralleles Dateisystem vs. verteiltes Dateisystem
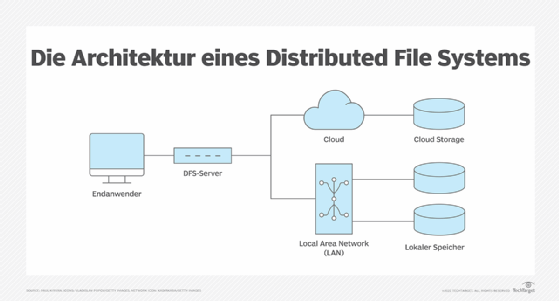
Ein paralleles Dateisystem ist eine Art verteiltes (Distributed) Dateisystem. Sowohl verteilte als auch parallele Dateisysteme können Daten auf mehrere Speicherserver verteilen, auf Petabytes an Daten skalieren und hohe Bandbreiten unterstützen.
Verteilte Dateisysteme unterstützen in der Regel einen gemeinsamen globalen Namensraum, ebenso wie parallele Dateisysteme. Bei einem verteilten Dateisystem greifen jedoch alle Clientsysteme, die auf einen bestimmten Teil des Namensraums zugreifen, in der Regel über denselben Speicherknoten auf die Daten und Metadaten zu, selbst wenn Teile der Datei auf anderen Servern gespeichert sind. Bei einem parallelen Dateisystem haben die Clientsysteme direkten Zugriff auf alle Speicherknoten für die Datenübertragung, ohne über einen einzigen Koordinierungsserver gehen zu müssen.
Weitere Unterschiede zwischen parallelen und verteilten Dateisystemen sind unter anderem die folgenden:
- Ein verteiltes Dateisystem verwendet in der Regel ein Standard-Netzwerkdateizugriffsprotokoll wie Network File System (NFS) oder Server Message Block (SMB), um auf einen Speicherserver zuzugreifen. Ein paralleles Dateisystem erfordert die Installation von clientbasierten Softwaretreibern, um auf das gemeinsam genutzte Speichersystem zuzugreifen, in der Regel über Hochgeschwindigkeits-Ethernet-, InfiniBand- und Omni-Path-Netzwerke.
- Ein verteiltes Dateisystem speichert eine Datei häufig auf einem einzelnen Speicherknoten, während ein paralleles Dateisystem die Datei aufteilt und die Datenblöcke auf mehrere Speicherknoten verteilt.
- Verteilte Dateisysteme speichern Daten auf den Anwendungsservern oder zentralen Servern, während typische parallele Dateisysteme aus Leistungsgründen die Rechen- und Speicherserver trennen.
- Verteilte Dateisysteme zielen auf lose gekoppelte, datenintensive Anwendungen oder aktive Archive ab. Parallele Dateisysteme konzentrieren sich auf Hochleistungs-Workloads, die von einem koordinierten I/O-Zugriff und einer erheblichen Bandbreite profitieren können.
- Verteilte Dateisysteme verwenden Techniken wie Drei-Wege-Replikation und Erasure Coding, um Fehlertoleranz in der Software zu gewährleisten, während viele parallele Dateisysteme auf Hardware-Ebene (zum Beispiel RAID oder verteilte Objektspeicher) für Redundanz und Fehlertoleranz sorgen.
Vor- und Nachteile paralleler Dateisysteme
Positiv zu vermerken ist, dass parallele Dateisysteme HPC, Datenreplikation und Scale-Out-Speicher unterstützen können. Sie sind auch wichtige Werkzeuge für Disaster-Recovery-Prozesse, da Daten an mehreren Orten gespeichert werden können, um einen schnellen Abruf und eine schnelle Wiederherstellung zu ermöglichen.
Umgekehrt führt ein Hochleistungssystem oft zu erhöhter Komplexität und Verwaltungsaufwand. Die Wartung eines parallelen Systems kann schwieriger sein, und die mit System-Upgrades verbundenen Aktivitäten sind oft kompliziert.
Beispiele für parallele Dateisysteme
Zu den von Branchenexperten und Forschern identifizierten parallelen Dateisystemen gehören die folgenden:
- Parallel Virtual File System (PVFS): PVFS ist ein Open-Source-Dateisystem für Linux-basierte Cluster. Es wurde vom Parallel Architecture Research Laboratory der Clemson University und der Abteilung für Mathematik und Informatik des Argonne National Laboratory entwickelt. PVFS basiert auf Vesta, das im T.J. Watson Research Center von IBM entwickelt wurde. Die aktuelle Version, PVFS2, wurde 2003 veröffentlicht.
- OrangeFS: OrangeFS ist ein Open-Source-Parallel-Dateisystem für parallele Rechenumgebungen und ein Ableger von PVFS, das eine breitere Palette von Anwendungsfällen und Funktionen unterstützt.
- Lustre: Dieses objektbasierte Open-Source-Parallel-Dateisystem verfügt über Dateibereiche unterschiedlicher Länge und statische Metadaten für die Informationsverteilung. Das Lustre-Dateisystem unterstützt eine Reihe von Linux-Distributionen und bietet Funktionen wie die Skalierbarkeit von Metadatenservern, eine Online-Konsistenzprüfung und Servicequalität.
- IBM Spectrum Scale (GPFS): Ein weit verbreitetes, kommerzielles paralleles Dateisystem, das sich durch hohe Zuverlässigkeit, Skalierbarkeit und breite Funktionsunterstützung auszeichnet.
- BeeGFS: Ein flexibles paralleles Dateisystem aus Deutschland, das für HPC-Cluster, KI-Workloads und kommerzielle Umgebungen eingesetzt wird und sich durch einfache Administration und gute Performance auszeichnet.
Paralleles Dateisystem: Das Wichtigste auf einen Blick
Parallele Dateisysteme ermöglichen gleichzeitigen Zugriff vieler Clients auf Daten durch verteilte Speicherung und koordinierte I/O-Operationen.
Sie sind für HPC-Umgebungen optimiert und skalieren auf Petabytes bis Exabytes.
Der Zugriff erfolgt über Hochgeschwindigkeitsnetze (InfiniBand, Omni-Path, moderne Ethernet-Standards).
Metadatenserver und ein globaler Namensraum sorgen für Transparenz und effizienten Datenzugriff.
Typische Anwendungsfelder: Klimamodellierung, Genomik, KI/ML, Finanz- und Ingenieursimulationen.
Unterschied zu verteilten Dateisystemen: parallele Systeme erlauben direkten Zugriff auf viele Speicherknoten und erzielen dadurch hohe I/O-Bandbreiten.
Beispiele: Lustre, IBM Spectrum Scale (GPFS), BeeGFS, OrangeFS, PVFS.
Erfahren Sie mehr über Storage Management
-
![]()
Ceph Storage auf Ubuntu für Proxmox und Kubernetes
Von: Thomas Joos
-
![]()
XFS oder ext4: Welches Linux-Dateisystem maximiert Storage?
Von: Damon Garn
-
![]()
Parallele Dateisysteme für HPC, KI und Analyse im Vergleich
Von: Thomas Joos
-
![]()
Eröffnet die KI-Technologie Object Storage neue Marktchancen?
Von: Simon Robinson



