
Leigh Prather - stock.adobe.com
Best Practices für Ihre Multi-Cloud-Kubernetes-Strategie
Die Multi-Cloud hat Vorteile, erhöht aber die Komplexität der Verwaltung. Wir zeigen die Best Practices und Konfigurationen für eine erfolgreiche Multi-Cloud-Kubernetes-Strategie.

Das Verschieben von Workloads von einer Umgebung in eine andere ist immer ein kompliziertes Unterfangen – egal, ob in der Cloud oder On-Premises. Der Schlüssel zum Erfolg liegt darin, die Details der Implementierung bereits im Voraus auf diese Aufgabe auszurichten. Aus der Architekturperspektive ist Kubernetes eine gute Methode, um die Komplexität eines Multi-Cloud-Szenarios zu verringern.
Bei der Multi-Cloud geht es darum, Workloads auf verschiedene Clouds zu verteilen und sie zwischen diesen zu verschieben. Dazu verbinden Sie diese mit Netzwerken, VPN-Verbindungen und Rollenbasierten Zugangskontrollen (Role-based acces control, RBAC) sowie Identitäts- und Zugangsmanagement für die Authentifizierung und Autorisierung. Wenn Sie mehrere Clouds gleichzeitig einsetzen, nutzen Sie in diesen jedoch wahrscheinlich verschiedene Betriebssysteme oder sind an systemspezifische Abhängigkeiten gebunden. Kubernetes ist eine beliebte Lösung für Hybrid- und Multi-Clouds, weil es eine gute Portabilität bietet.
Werfen wir einen Blick auf Multi-Clouds und wie Ihr Unternehmen davon profitieren könnte, in Zukunft auf Kubernetes zu setzen.
K8s Cluster über mehrere Clouds hinweg betreiben
Für Kubernetes müssen Sie ähnliche Grundfragen abklären, wie für ein komplettes Datacenter. Sie befassen sich mit:
- Netzwerk
- Server
- Storage
- Sicherheit und Richtlinien
- Befugnisse und RBAC
- Container-Images
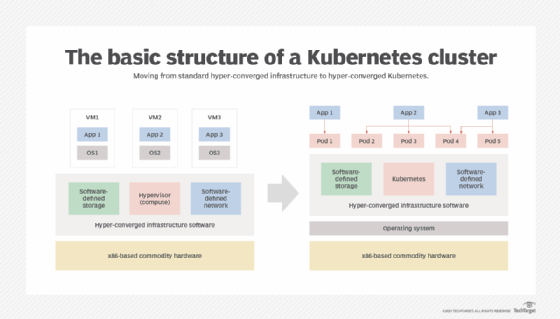
Innerhalb eines Kubernetes-Clusters verhalten sich Workloads auf derselben Plattform wie eine komplett eigenständige Umgebungen. Manche Ingenieure bezeichnen es gar als Rechenzentrum in der Cloud.
Unerwartete Ereignisse wie eine Überschwemmung, ein Feuer oder ein schwerer technischer Defekt können die gesamte Umgebung ausschalten. Mit Kubernetes bedeutet eine solche Katastrophe im Cluster, dass hunderte oder sogar tausende von Anwendungen ausfallen. Deshalb ist Disaster Recovery einer der wichtigsten Aspekte einer durchdachten Kubernetes-Strategie.
Eine Multi-Cloud-Kubernetes-Strategie aufsetzen
Wenn Sie eine Multi-Cloud-Kubernetes-Strategie erarbeiten, sollten Sie sich an den folgenden vier kritischen Themen ausrichten.
Standardisierte Cluster-Richtlinien
Open Policy Agend (OPA) ist auf dem Weg, einer der wichtigsten Standards für Kubernetes-Cluster neben Kyverno zu werden. Im Gegensatz zu letzterem, lässt sich OPA auch auf den Bereich außerhalb von Kubernetes anwenden, so dass Entwickler ihn über sämtliche Umgebungen hinweg nutzen können. Daneben stellen sie mit OPA sicher, dass alle Kubernets-Manifeste Labels erhalten, welche die containerisierte Anwendung identifizieren und dass kein Container-Image den letzten Tag verwenden kann. Entwickler erstellen in diesem Framework alles von generellen Best Practices bis hin zu spezifischen Sicherheitsanweisungen.
Track-Versionierung
Es ist von entscheidender Bedeutung, wie Sie containerisierte Anwendungen bereitstellen und verwalten. In der Vergangenheit galt es als solide Praxis, ein Kubernetes-Manifest herzunehmen und es über einen Localhost mit kubectl apply –f bereitzustellen, oder eine CI/CD Pipeline dafür zu nutzen. Heute, mit GitOps, ist das nichtmehr notwendig, da es Kubernetes-Manifeste automatisch bereitstellen kann. GitOps prüft, ob sich die Bereitstellung im angestrebten Zustand befindet, den es einem Git-basierten Repository entnimmt.
Konsequente Beschriftung
Vergeben Sie Tags an Ressourcen, damit Sie und andere Benutzer verstehen, was sie vor sich haben, woher die Ressource kommt und wie sie sich verhalten wird. Damit sparen Sie sich einiges an Verwirrung. Wenn Sie beispielsweise zehn Kubernetes-Cluster betreiben und diese als kubernetes01, kubernetes02, kubernetes03 und so weiter beschriftet sind, werden Sie niemals wissen, zu welcher Cloud sie gehören, in welcher Region sie sich befinden und was für Workloads darauf laufen.
Verteilen von Workloads
Es ist wichtig, dass Sie Workloads – oder Cluster – über Regionen und Verfügbarkeitszonen hinweg verteilen. Wenn Sie beispielsweise useast-1 in AWS nutzen und eastus1 in Azure, befinden sie sich geografisch nah beieinander. Wenn eine Naturkatastrophe den AWS-Standort betrifft, wird sie wahrscheinlich auch den Azure-Standort betreffen. Deshalb ist es sinnvoll, die Regionen Ihrer Multi-Cloud etwas zu entzerren.
Stellen Sie Apps in Ihren Clustern mit Kubeconfig bereit
Für die im Folgenden beschriebene Vorgehensweise benötigen wir:
- Azure Kubernetes Services (AKS) und Amazon Elastic Kubernetes Service (EKS) für unsere Kubernetes-Cluster; und
- Argo CD für GitOps
Wenn Sie diese Plattformen nicht verwenden, können Sie der Anleitung dennoch folgen; die Vorgehensweise wird vom Prinzip her dieselbe sein.
Schritt 1: Cluster erstellen und konfigurieren
Als erstes brauchen Sie ein EKS- und AKS-Cluster. Wenn Sie diese lieber automatisiert einrichten, finden Sie alles, was Sie dazu brauchen, im GitHub-Repo KubernetesEnvironments.
Schritt 2: Kontexte einholen
Sind Ihre Cluster konfiguriert, benötigen Sie den Kontext von beiden für Kubeconfig. Um beispielsweise den Kontext aus AKS und EKS zu erhalten, verwenden Sie die folgenden Befehle:
# Azure
az aks get-credentials -n name_of_k8s_cluster
# AWS
aws eks --region region update-kubeconfig --name cluster_name
Schritt 3: Cluster registrieren
Sobald Sie den jeweiligen Kontext in Ihr Kubeconfig eingefügt haben, registrieren Sie die beiden Cluster mit Argo CD und den folgenden Befehlen:
# Retrieve the context names for AKS and EKS
kubectl config get-contexts -o name
# Register the contexts
argocd cluster add aks_context_name_here
argocd cluster add eks_context_name_here
Schritt 4: Apps bereitstellen
Als nächstes platzieren Sie die Apps in den beiden Clustern:
# AKS
argocd app create app_name --repo https://github.com/orgname/reponame.git --path repo_path_where_k8s_manifests_exist --dest-server https://
#EKS
argocd app create app_name --repo https://github.com/orgname/reponame.git --path repo_path_where_k8s_manifests_exist --dest-server https://
Stellen Sie das AKS- oder EKS-Cluster ab, um eine hot/cold-Wiederherstellung einzurichten. Sie können Automatisierung anwendet, damit das ruhende Cluster startet, wenn das aktive ausfällt, und sich selbstständig mit einem GitOps-Repository synchronisiert. Unsere Einleitung ist aber auf jeden Fall ein guter Einstiegspunkt in die Arbeit mit Kubernetes und der Multi-Cloud.






