
greenbutterfly - stock.adobe.com
Netzwerk-Automatisierungsarchitektur in 4 Schritten aufbauen
Die Implementierung einer Architektur zur Netzwerkautomatisierung umfasst mehrere Elemente, darunter eine zentrale Orchestrierungs-Engine, Datenbanken und geeignete Netzwerktests.
Die meisten Netzwerkmanager interessieren sich für die Netzwerkautomatisierung, weil sie sich durch die Automatisierung wiederkehrender Aufgaben wie Gerätebereitstellung und Konfigurationsmanagement auf strategische Initiativen konzentrieren können. Doch wie ist die Netzwerk-Automatisierungsarchitektur zu planen und welche Elemente sollten zuerst in Angriff genommen werden? Der Trick besteht darin, eine Architektur zu schaffen, die unabhängig von kommerziellen oder Open-Source-Produkten ist.
Eine Architektur für Netzwerkautomatisierung bietet die Skalierbarkeit und Ausfallsicherheit, die für die Anpassung an sich ändernde Netzwerkanforderungen erforderlich sind. Wir stellen eine Architektur vor und schlagen eine Reihenfolge vor, um die Elemente zu implementieren.
Beginnen Sie mit den Anforderungen, die architektonische Funktionen widerspiegeln, zum Beispiel die Automations-Engine. Jede dieser Funktionen besitzt Inputs und Outputs, die bestimmen, wie die einzelnen Elemente interagieren.Verfolgen Sie dann einen stufenweisen Ansatz, der die Automatisierungsfähigkeiten in dem Maße steigert, wie die neuen Technologien und Prozesse in der vorangegangenen Phase integriert und übernommen werden.
Die architektonischen Funktionen und Phasen
Wie so vieles andere im Leben folgen auch Implementierungen der Evolution vom Einfachen zum Komplexen. Die frühen Phasen bieten einfache Funktionen, die reine Lesevorgänge auf Netzwerkgeräten durchführen. Spätere Phasen ermöglichen die Änderung von Gerätekonfigurationen. Die letzten Phasen schließlich automatisieren komplette Prozesse, etwa Tests auf virtuellen Instanzen des Produktionsnetzwerks vor dem finalen Rollout. Einige Funktionen lassen sich entsprechend den Anforderungen des Unternehmens auch in andere Phasen verschieben.
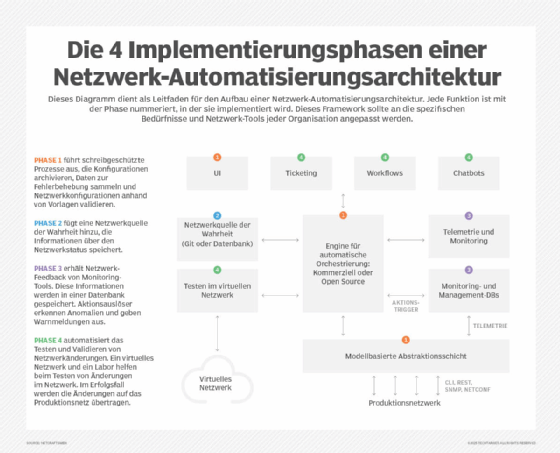
Phase 1: Start von Nur-Lese-Prozessen
Phase 1 ermöglicht eine grundlegende Funktionalität durch drei Funktionen: das System für die Automationsorchestrierung, die Benutzeroberfläche (User Interface, UI) und die Geräteabstraktionsschicht. Phase 1 beginnt mit automatisierten Prozessen, die nur lesend zugreifen. Diese archivieren Konfigurationen, sammeln Troubleshooting-Daten und validieren Netzwerkkonfigurationen anhand von Vorlagen (Templates). Die Elemente in Phase 1 umfassen:
- Automationsorchestrierung. Die Core-Orchestrierungs-Engine steuert den Automatisierungsprozess. Sie enthält Skalierungsfunktionen, wie parallele Verarbeitung und verteilte Agenten. Für diese Funktion sind mehrere kommerzielle Produkte und Open-Source-Pakete verfügbar.
- Benutzeroberfläche. Kommerzielle Produkte verfügen in der Regel über eine GUI und eine API, was für spätere Phasen der Automation wichtig ist. Open-Source-Projekte bieten üblicherweise eine Befehlszeile für die Administration und eine API zur Programmsteuerung.
- Abstraktionsschicht. Die Abstraktionsschicht ermöglicht ein Modell, das die Unterschiede zwischen den Geräteanbietern verbirgt, sodass sich die Netzwerkgeräteschnittstelle stark vereinfachen lässt. Die Abstraktionsschicht kann in einige Orchestrierungssysteme integriert sein.
Phase 2: Hinzufügen einer Quelle der Wahrheit im Netzwerk
In Phase 2 kommen eine NSoT-Datenbank (Network Source of Truth) und eine Schnittstelle für ein Trouble-Ticketing-System hinzu. Die Elemente in Phase 2 umfassen:
- NSoT-Datenbank. Die NSoT speichert Informationen über den gewünschten Netzwerkstatus, den das System zur Automationsorchestrierung nutzt, um den Netzwerkbetrieb zu validieren und – in späteren Phasen – zu korrigieren. Zu diesen Daten können Adresszuweisungen, benachbarte Netzwerkprotokolle sowie der Betriebszustand und die Erreichbarkeit der Schnittstellen gehören.
- Automatisches Trouble Ticketing. Eine Schnittstelle für ein Trouble-Ticketing-System ermöglicht es dem System zur Automationsorchestrierung, Tickets zu erstellen, wenn der Netzwerkstatus und die NSoT voneinander abweichen. Die Problembehebung wird anfangs manuell erfolgen, in späteren Phasen aber zunehmend automatisiert ablaufen.
Phase 3: Implementierung von Netzwerk-Telemetrie und -Monitoring.
In dieser Phase liefert das Netzwerk Feedback in Form von Telemetriedaten und Monitoringwarnungen. Bis zu diesem Zeitpunkt hat das Netzwerk nur wenig Rückmeldung gegeben, abgesehen von Syntaxvalidierungen beim Schreiben von Konfigurationen, die in das NSoT eingegeben wurden. Die Elemente der Phase 3 sind
- Telemetrie und Monitoring: In der Vergangenheit basierte das Netzwerk-Monitoring auf dem Simple Network Management Protocol (SNMP). Modernere Implementierungen setzen hingegen auf Streaming-Telemetrie. Netzwerke werden für geraume Zeit beide Methoden nutzen müssen. Die meisten Plattformen, die zur Erfassung von Telemetriedaten verwendet werden, unterstützen auch eine Möglichkeit, Überwachungswarnungen zu senden. Ein Beispiel ist der Prometheus Alertmanager, der Warnungen an einen E-Mail- oder Slack-Kanal senden kann.
- Monitoring- und Managementdatenbanken: Die überwachten Daten müssen irgendwo gespeichert werden. Zu den Datenspeichern können eine Dokumentenspeicher-Datenbank für Protokolle, eine Zeitreihendatenbank für Metriken, eine verteilte Tracing-Datenbank für Traces und eine relationale Datenbank für beziehungsartige Daten wie Gerätetyp und Schnittstellenliste gehören. Zu den beliebten Open-Source-Plattformen, die Datenbanken zur Implementierung von Netzwerktelemetrie unterstützen, gehören:
- Prometheus: eine Metrikplattform, die Zeitreihendatenbanken verwendet.
- Elasticsearch: eine Protokollplattform, die eine Dokumentenspeicherdatenbank verwendet.
- Jaegar: eine Ablaufverfolgungsplattform, die eine verteilte Ablaufverfolgungsdatenbank verwendet.
- NetBox: eine Verwaltungsplattform, die eine relationale Datenbank nutzt.
- Monitoring- und Managementdatenbanken. Die Überwachungsdaten müssen irgendwo gespeichert werden. Das geschieht entweder in einer relationalen Datenbank (für Beziehungsdaten wie Gerätetyp und Interface-Liste) oder in einer Zeitreihendatenbank (für Interface-Performance-Variablen).
- Aktions-Trigger. Netzwerk-Monitoring ist nur dann von Vorteil, wenn die Ergebnisse auch zu Reaktionen führen. Aktions-Trigger nutzen entweder Regelsätze oder Machine Learning, um Anomalien zu erkennen, Alarme auszulösen und Trouble Tickets zu eröffnen. Fortgeschrittenere Implementierungen lösen automatisierte Workflows aus, um die Problembehebung ohne menschliche Eingriffe zu beginnen, etwa alternatives Routing um einen ausgefallenen Link herum.
Phase 4: Änderungen automatisiert testen und validieren
In dieser letzten Phase der Architektur werden Änderungstests und -validierungen automatisiert. Dies umfasst Folgendes:
- Testen im virtuellen Netzwerk: Der wichtigste Faktor bei der Steuerung von Netzwerkänderungen ist die Praxis, eine Änderung im Labor zu testen, bevor sie in der Produktion eingesetzt wird. Im Labor werden virtuelle, softwaresimulierte Geräte verwendet, um die Schlüsselparameter des Produktionsnetzwerks zu modellieren. Vorgeschlagene Änderungen instanziieren das virtuelle Netzwerk, führen Tests vor der Änderung durch, um zu überprüfen, ob das Labor wie vorgesehen funktioniert, wenden die Änderung an und führen Tests nach der Änderung durch, um zu überprüfen, ob das gewünschte Ergebnis erzielt wurde.
- Workflows: Workflows können durch die Ausführung von Skripten, beispielsweise Python- oder Ansible-Playbooks, ausgelöst werden, die innerhalb eines Git-Repositorys oder eines beliebigen Quellcodeverwaltungssystems, das als Quelle der Wahrheit fungiert, versionskontrolliert sind. Kommerzielle Produkte bieten oft mehrere Mechanismen zur Steuerung von Workflows, darunter grafische Editoren und APIs. Der beliebteste Workflow für die Infrastrukturautomatisierung ist GitOps, eine Untergruppe von DevOps. Das folgende Beispiel ist ein typischer Workflow:
-
- Ein GitOps-Agent von Flux CD, Argo CD oder Jenkins überwacht das Git-Repository.
- Eine neue Netzwerkkonfiguration wird in das Git-Repository übertragen.
- Wenn eine Änderung erkannt wird, ruft der Agent die Konfiguration über eine CI/CD-Pipeline wie Flux CD oder Jenkins ab, testet sie und wendet sie an.
- Router werden automatisch konfiguriert.
- Wenn die Konfiguration eines Geräts von Git abweicht, wird sie durch die Automatisierung korrigiert.
- Änderungsvalidierungstests: Wenn die Tests des virtuellen Netzwerks erfolgreich sind, wird die Änderung auf das Produktionsnetzwerk angewendet. Die Freigabe erfolgt in drei Schritten:
-
-
-
- Validierung des Zustands vor der Änderung, um sicherzustellen, dass alle Konfigurationen und Verbindungen wie erwartet funktionieren.
- Durchführen der Änderung, um neue Konfigurationen oder Aktualisierungen einzuführen.
- Validierung des resultierenden Zustands, um zu bestätigen, dass das Netzwerk reibungslos funktioniert und die Leistungserwartungen erfüllt.
-
-
- Automatische Erstellung von Trouble-Tickets: Eine Schnittstelle zu einem Trouble-Ticketing-System ermöglicht es dem Automation Orchestration System, Tickets zu erstellen, wenn der Netzwerkstatus und der NSoT voneinander abweichen. Die Fehlerbehebung erfolgt zunächst manuell, wird aber mit zunehmender Reife der Organisation immer weiter automatisiert. Ein CI/CD-System wie GitHub Actions kann auch verwendet werden, um einen Merge Change Request im Code Repository mit einer Funktion wie einem Pull Request zu öffnen.
- Chatbots: Tools wie GitHub Copilot können bei der Überprüfung von Pull-Anfragen helfen, indem sie Zusammenfassungen erstellen, Verbesserungen vorschlagen und sogar Kommentare auf der Grundlage vordefinierter Kriterien automatisieren. Dadurch wird die Belastung der Entwickler bei der Codeüberprüfung verringert.
Das Endziel
Die in diesem Artikel beschriebene Netzwerk-Automatisierungsarchitektur ist ein Framework. Netzwerkteams können sie an die Anforderungen ihrer Organisation und an die Funktionen der ausgewählten Tools anpassen.
Das Ziel besteht letztlich darin, einen Continuous-Integration-, Continuous-Delivery- und Continuous-Deployment-Prozess zu gestalten, in dem kleine, klar definierte Netzwerkänderungen nur nach dem Bestehen von strengen Tests automatisch bereitgestellt werden. Dieses Verfahren, das als NetOps oder NetDevOps bezeichnet wird, ermöglicht es Ihnen, Ihr Netzwerk auf Infrastructure as Code zu migrieren und dabei viele der gleichen Konzepte und Techniken wie bei der erfolgreichen Methoden für die Softwareentwicklung zu nutzen.
Hinweis: Dieser Artikel wurde aktualisiert, um die neuesten Entwicklungen bei der Planung und dem Aufbau von Architekturen für die Netzwerkautomatisierung widerzuspiegeln.







