S3-Speicher anbinden und als Primärspeicher nutzen
Viele Anwendungen können Cloud-Speicher nicht als Primärspeicher nutzen. Wer das richtige Dateisystem einsetzt, kann Latenz- und Synchronisierungsprobleme umgehen.
Gesteigerte Produktivität, verbesserte Flexibilität, hohe Skalierbarkeit und bessere Kosteneffizienz? Um all die Vorteile der Cloud vollständig ausschöpfen zu können, spielt es eine entscheidende Rolle, wie man diese nutzt.
Für zahlreiche Unternehmen wäre es zum Beispiel verlockend, AWS S3-Speicher auch für Produktionsdaten, also als Primärspeicher, zu nutzen. Damit geht allerdings die Herausforderung einher, diesen so anzubinden, dass die lokalen Anwendungen schnell und performant auf die Daten aus der Cloud zugreifen können. Kann das funktionieren?
Werden Dateien mit großem Umfang aus einem Cloud-Objektspeicher in Produktionsumgebungen genutzt, beispielsweise in Bereichen wie Bauwesen, Filmproduktion oder Werbung, brauchen Anwender viel Geduld.
Wollen sie Dateien von der Größe mehrerer Gigabytes einsehen und bearbeiten (etwa Pläne oder Multimedia-Dateien), so können vom Aufruf derselben bis zu dem Zeitpunkt, an dem diese bearbeitet werden können, mitunter Stunden vergehen.
Zwar sind auf dem Markt verschiedene Lösungsansätze für die Anbindung von Cloud-Speicher etabliert, sie alle liefern jedoch nur ein suboptimales Ergebnis, wie man bei genauerem Hinsehen feststellt.
Vollständige Synchronisation und Synchronisation nach Bedarf
Dieser Cloud-Speicheransatz entstand vor über zehn Jahren im Zuge von Anwendungen wie Box, Dropbox und anderen File-Sharing-Angeboten. Die Idee erschien einfach: Eine Kopie der gespeicherten Datei wird an allen Zugriffsorten bereitgestellt und Änderungen daran werden auf allen damit verbundenen Geräten synchronisiert.
Einzelne Privatpersonen mit kleineren Dateien und geringen Sharing-Anforderungen bereitet dies keinerlei Schwierigkeiten. Auch in manchen kleinen Firmen mit einer Anzahl von weniger als zehn Mitarbeitern, kommen diese Verfahren häufig zum Einsatz. Mit zunehmenden Datenmengen und Dateigrößen lässt es sich jedoch nicht auf die produktive Nutzung von Primärdaten skalieren.
Zwar können Konnektoren die in diesen Diensten gespeicherten Daten bestimmten Anwendungen bereitstellen, an der Kompromisslosigkeit des ursprünglichen Vorgehens ändert dies allerdings nichts: Nach wie vor müssen Nutzer an verschiedenen Standorten alle Daten jeweils vollständig herunterladen und synchronisieren.
Dies beansprucht viel Zeit, Bandbreite und vervielfacht die benötigten Speicherressourcen. Auch unter dem Aspekt der Datensicherheit ergeben sich Nachteile, da wenig Kontrolle darüber besteht, wie und wo Daten gespeichert werden.
Cloud-Speicheranbindung als lokales Laufwerk
Einen verbesserten Nutzerkomfort versprechen Anwendungen, mit denen Cloud-Speicherorte direkt auf den Desktop gemountet und wie lokale Laufwerke genutzt werden können. Dazu verwenden die Anwendungen die Cloud-Objektspeicher-nativen Get/Put-API-Befehle, die über einen Mountpoint im lokalen Betriebssystem emuliert werden.
Nutzer können damit bequem ihren Arbeitsbereich ordnen, gespeicherte Dateien durchsuchen und nach Bedarf synchronisieren. Trotz ihres komfortablen lokalen Nutzungseindrucks eignet sich diese Variante lediglich für den gelegentlichen Zugriff auf kleinere Dateien.
Bei professionellen Ansprüchen, in Unternehmensumgebungen und bei der intensiven Zusammenarbeit mehrerer Anwender gerät auch dieser Ansatz schnell an seine Grenzen. Der Grund dafür liegt darin, dass das Betriebssystem für jeden einzelnen Zugriff die entsprechende Datei vollständig herunterlädt und nach erfolgter Bearbeitung in vollem Umfang wieder in den Cloud-Speicherort hochladen muss.
Gateways
Für Endpoints, die sich in derselben LAN-Umgebung befinden, kommt der Einsatz eines Gateways in Frage, das dem Cloud-Speicher vorgeschaltet wird. Dieses fungiert – entweder als physische oder virtuelle Appliance – als Zwischenspeicher für die Dateien, auf die zugegriffen wird.
Allerdings ist diese Lösung schwer zu skalieren, da sämtliche Verbindungen und Daten das Gateway passieren müssen. Die Folge sind Engpässe im Datenverkehr. Kommen außerdem weitere Standorte hinzu, muss auch die Anzahl der Gateways aufgestockt werden, was zusätzlichen Aufwand an Einrichtung, Überwachung und Verwaltung nach sich zieht.
Stolpersteine: Fehlendes Dateisystem und Latenz
Die Ursache dafür, dass der lokale Anwendungszugriff auf Cloud-Daten bislang nicht zufriedenstellend gelöst werden konnte, liegt darin, dass die drei gängigen Ansätze die beiden grundlegenden, mit Cloud-Objektspeicher verbundenen Schwierigkeiten nicht eliminieren.
Erstens existiert kein Dateisystem, das eine direkte Verbindung zum Objektspeicher herstellt. Daher müssen die dort gespeicherten Daten zuerst übersetzt oder in ein bestehendes Dateisystem überführt werden, um sie verwenden zu können. Die gemeinsame Datennutzung mit einer lokalen Anwendung wird dadurch erschwert.
Zweitens sind die von den Softwareanwendungen genutzten Kommunikationsprotokolle schlichtweg nicht für die Interaktion mit Cloud-Umgebungen designt.
Sie sind mehrere Jahrzehnte alt und damit darauf ausgelegt, die benötigten Dateien von der Festplatte des Endgeräts oder aus dem lokalen Netzwerk zu beziehen. Werden Dateien aus einem Cloud-Objektspeicher genutzt, bemerken Anwender dies meist durch lange Wartezeiten beim erstmaligen Öffnen sowie bei den einzelnen Zwischenspeichervorgängen. Woran liegt es?
Objektspeicher fügt den einzelnen Dateien (Objekten) Metadaten hinzu. Auf dieser Meta-Ebene befinden sich die Applikation und der Speicherort ständig in Kommunikation. Man spricht von „Chatty Protocols“ – geschwätzigen Protokollen.
Dieser stetige, intensive Informationsaustausch war in lokalen Netzwerkumgebungen kein Problem, denn der Bandbreitenbedarf dafür ist minimal und bei Leitungen, die nur wenige Meter lang sind, gibt es kaum Latenz.
Erfolgt dieser Austausch jedoch mit einem weiter entfernten Cloud-Speicherort, werden alle anfallenden Datenpakete mit einer schon deutlich höheren Verzögerung übermittelt – und das viele tausend Mal. Die Folge: Die Anwendungen geraten ins Stocken oder frieren ein. Die Ursache dafür, dass Cloud-Objektspeicher sich bislang nicht als Primärspeicher eignet, liegt also in den mit Cloud-Umgebungen unvereinbaren Kommunikationsmechanismen der Anwendungen.
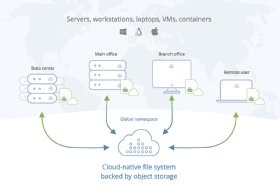
Ein verteiltes Dateisystem macht S3 primärspeichertauglich
Mittlerweile existiert allerdings ein Ansatz, um diesen gordischen Knoten durchzuschlagen: Ein besseres Datenlayout ermöglicht es, die damit verbundenen Latenzprobleme zu eliminieren. Anstatt wie bei S3-Speicher üblich, eine Datei als ein Objekt zu behandeln, wird die Datei einfach in viele Objekte aufgeteilt.
Für eine äußerst umfangreiche Datei bestehen Verbindungen zu den einzelnen Objekten, aus denen sie sich zusammensetzt. Insbesondere werden Metadaten und Nutzdaten getrennt. Der Austausch der Metadaten durch die veralteten Protokolle findet nicht länger zwischen Cloud-Speicher und lokalem Endgerät statt, sondern wird weitgehend auf das Endgerät verlagert – was die Latenz auf nahe null reduziert.
Und da nicht mehr die gesamte Datei synchronisiert werden muss, lassen sich nun genau die Bits der Datei, die gegenwärtig benötigt werden, zur Anwendung streamen. Prefetching und Caching sorgen zusätzlich für eine verzögerungsfreie Benutzererfahrung.
Endanwender haben so durchweg das Gefühl, eine lokale Datei zu nutzen – egal, ob sie sich im lokalen Unternehmensnetzwerk befinden oder beispielsweise extern aus dem Ausland darauf zugreifen. Sie können zum Beispiel ein Full-HD-Video oder CAD-Bauplan einfach über ihr lokales Verzeichnis aufrufen und sie ohne Verzögerungen einsehen und bearbeiten.
Sämtliche vorgenommenen Änderungen werden direkt in einem Filespace auf dem Server hinterlegt. Auf den Endgeräten werden im Gegensatz zu File-Sharing-Ansätzen nur die Metadaten synchronisiert. Mit einem verteilten Dateisystem behalten Unternehmen darüber hinaus bessere Kontrolle über ihre Daten, da der Download der vollständigen Datei auf lokale Endgeräte entfällt.

„Ein besseres Datenlayout ermöglicht es, die damit verbundenen Latenzprobleme zu eliminieren. Anstatt wie bei S3-Speicher üblich, eine Datei als ein Objekt zu behandeln, wird die Datei einfach in viele Objekte aufgeteilt.“
Peter Thompson, LucidLink
Der Ansatz des verteilten Dateisystems ist speziell für Objektspeicher entwickelt und lässt sich innerhalb eines Tages implementieren. Unternehmen, die Objektspeicher bereits für Backup oder Archivierung nutzen, können damit im Handumdrehen S3 als Primärspeicher nutzen.
Über den Autor:
Peter Thompson ist CEO von LucidLink. Das in San Francisco ansässige Unternehmen hat er 2016 zusammen mit George Dochev (CTO) gegründet. Beide Gründer waren zuvor in führenden Positionen bei DataCore tätig.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder.
Erfahren Sie mehr über Cloud Storage
-
![]()
Diese Storage-Fachbegriffe sollten Sie kennen
Von: Paul Kirvan
-
![]()
Block, File und Object Storage verstehen: Welcher Speichertyp für welchen Bedarf?
Von: Brien Posey
-
![]()
Eröffnet die KI-Technologie Object Storage neue Marktchancen?
Von: Simon Robinson
-
![]()
Was im Jahr 2025 für die Storage-Branche wichtig ist
Von: Brien Posey



