
ipuwadol - stock.adobe.com
Föderierte Datenzugriffe als Antwort auf verteilte Daten
Unternehmen setzen zunehmend auf föderierte Datenarchitekturen. Der Beitrag zeigt die Hintergründe und erklärt am Beispiel der Starburst-Plattform die verfügbaren Ansatzoptionen.

Unternehmen müssen ihre Datenarchitekturen zunehmend an verteilte Datenbestände anpassen. Daten liegen heute häufig nicht mehr in einem zentralen Warehouse, sondern verteilt über Cloud-Speicher, Data Lakes, Datenbanken, SaaS-Anwendungen und lokale Systeme. Gleichzeitig steigen die Anforderungen an Self‑Service‑Analytics, operative Berichte und KI‑Anwendungen, während IT‑Teams mit Compliance, Kosten, Latenz und Datenhoheit umgehen müssen. In dieser Gemengelage verlieren klassische Großprojekte zur vollständigen Zentralisierung an Attraktivität. Stattdessen rückt ein Ansatz in den Vordergrund, der Daten dort belässt, wo sie entstehen, und sie über eine gemeinsame Zugriffsschicht nutzbar macht.
Der Trend ist mehr als ein technischer Wechsel. Er spiegelt eine neue Logik im Datenmanagement wider: Nicht jede Information muss physisch verschoben werden, damit sie wertvoll wird. Unternehmen wollen schneller auf Daten zugreifen, aber sie wollen dafür weder monatelange Migrationsprojekte noch zusätzliche Kopien in immer neuen Zielsystemen in Kauf nehmen. Gerade in regulierten Branchen oder in Organisationen mit historisch gewachsenen IT‑Landschaften ist das kaum noch praktikabel. Deshalb gewinnen föderierte Modelle an Bedeutung, in denen Zugriff, Governance und Kontext über eine zentrale Ebene organisiert werden, ohne die verteilte Architektur komplett umzubauen.
Warum Zentralisierung an Grenzen stößt
Die Zentralisierung von Daten in Warehouses oder Data Lakes galt lange als bevorzugter Ansatz für Analysen und Reporting. Sie versprach einheitliche Modelle, bessere Analysemöglichkeiten und eine klarere Betriebsführung. In der Praxis ist dieses Modell jedoch immer schwerer umzusetzen, weil Unternehmensdaten nicht nur umfangreicher, sondern auch heterogener geworden sind. Ein moderner Datenbestand besteht häufig aus transaktionalen Systemen, Cloud‑Speichern, Event‑Streams, Fachanwendungen, externen Partnerquellen und analytischen Plattformen, die jeweils eigene Formate, Zugriffsregeln und Performance‑Eigenschaften mitbringen. Die vollständige Konsolidierung solcher Datenbestände kann Integrationsaufwand, Datenkopien und Betriebsaufwand erheblich erhöhen.
Hinzu kommt, dass sich die Anforderungen an Daten heute viel schneller ändern als die klassischen Integrationszyklen. Fachbereiche wollen neue Use Cases kurzfristig testen, KI‑Projekte brauchen Zugriff auf aktuelle Datenbestände, und operative Teams möchten Entscheidungen möglichst in Echtzeit treffen. Klassische ETL‑Ketten, Data‑Warehouse‑Ladefenster und aufwendige Replikationsprozesse sind dafür oft zu träge. Gleichzeitig steigen die Anforderungen an Datenschutz und Datenresidenz. Nicht jeder Datensatz darf oder soll in eine zentrale Umgebung migriert werden. Genau an diesem Punkt wird deutlich, warum die Debatte um Datenarchitektur nicht mehr nur um mehr Zentralisierung kreist, sondern um die Frage, wie sich verteilte Daten systematisch nutzbar machen lassen.
Föderierte Modelle und Data Mesh
Als mögliche Antwort auf diese Entwicklung diskutieren viele Unternehmen föderierte Datenarchitekturen und Data-Mesh-Konzepte. Der Kern des föderierten Modells ist einfach: Daten bleiben an ihrem Ursprungsort, werden aber über eine logische Zugriffsschicht auffindbar und abfragbar gemacht. Statt alle Informationen zuerst in ein Zielsystem zu verschieben, nimmt eine SQL‑ oder Abfrageschicht die Anfragen entgegen, verteilt sie auf mehrere Quellen und führt die Ergebnisse zusammen. Für die Anwender entsteht damit ein einheitlicher Zugriff, auch wenn die physische Datenhaltung verteilt bleibt.
Data Mesh ergänzt diesen technischen Ansatz um eine organisatorische Perspektive. Hier liegt die Verantwortung nicht allein bei einem zentralen Plattformteam, sondern auch bei den Domänen, die ihre Daten als Produkte bereitstellen. Das bedeutet: klare Zuständigkeiten, definierte Schnittstellen, dokumentierte Metadaten und ein gemeinsames Governance‑Gerüst. Befürworter sehen die Stärke des Modells in der Kombination aus dezentraler Verantwortung und zentral definierten Governance-Regeln. Es verspricht mehr Geschwindigkeit, weil Fachbereiche näher an ihren Daten arbeiten können, und zugleich mehr Verlässlichkeit, weil zentrale Leitplanken für Sicherheit, Qualität und Auffindbarkeit bestehen bleiben.
Wichtig ist allerdings, Föderation nicht mit Beliebigkeit zu verwechseln. Das Modell funktioniert nur dann gut, wenn Metadaten gepflegt, Semantiken sauber definiert und Zugriffe kontrolliert werden. Sonst entsteht keine flexible Datenarchitektur, sondern lediglich ein neuer, technisch eleganter, aber fachlich unscharfer Zugriff auf fragmentierte Systeme. Genau deshalb ist die Diskussion um föderierte Architekturen eng mit Governance und Datenkontext verknüpft. Die Technik kann den Zugriff vereinfachen, aber sie ersetzt keine inhaltliche Datenarbeit.
Starburst im Überblick
Starburst positioniert sich als Plattform für föderierten SQL-Zugriff auf verteilte Datenquellen und adressiert damit Unternehmen, die Daten aus unterschiedlichen Systemen gemeinsam auswerten wollen. Der Hersteller beschreibt das Angebot als Enterprise‑Intelligence‑Plattform mit Zugriff auf Cloud‑ und On‑Prem‑Quellen, die sich über eine einheitliche Abfrageschicht miteinander verbinden lassen. Nach Angaben des Herstellers liegt der Schwerpunkt der Plattform auf Datenzugriff, Governance und Performance, nicht auf der zentralen Speicherung von Daten. Ziel ist es, Daten direkt in den Quellsystemen nutzbar zu machen und den Bedarf an zusätzlichen Datenkopien zu reduzieren.
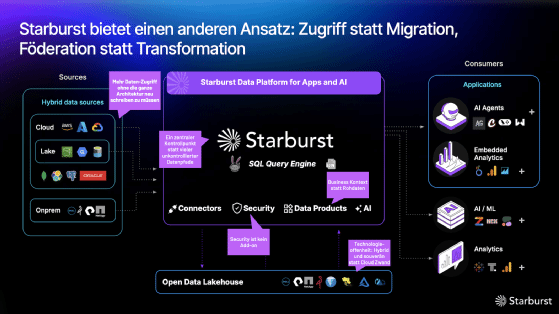
Die technische Basis von Starburst ist Trino, die Open‑Source‑SQL‑Engine für verteilte analytische Abfragen. Die Produktdokumentation beschreibt Starburst Enterprise als vollständig unterstützte Enterprise‑Distribution von Trino, die Integrationen ergänzt, die Performance verbessert, Sicherheitsfunktionen erweitert und die Bereitstellung sowie Verwaltung von Clustern erleichtert. Starburst Galaxy ist die verwaltete SaaS‑Variante der Plattform und zielt auf Nutzer, die ohne eigenen Betriebsaufwand auf eine leistungsfähige Trino‑Umgebung zugreifen wollen.
Die historische Entwicklung ist für die Einordnung relevant. Presto wurde 2012 bei Facebook entwickelt, um interaktive, niedriglatente Analysen auf sehr großen Datenbeständen zu ermöglichen. Später wurde das Projekt offengelegt, weiterentwickelt und schließlich in Trino umbenannt; Starburst selbst entstand 2017, um das Ökosystem kommerziell und technisch weiterzutreiben. Diese Herkunft erklärt, warum die Plattform bis heute stark auf verteilte SQL‑Abfragen und auf hohe Parallelisierung ausgerichtet ist.
Technische Grundlagen
Die Architektur hinter Starburst lässt sich als MPP‑basierte Query‑Engine beschreiben. MPP steht für Massively Parallel Processing und bedeutet, dass Abfragen parallel über viele Rechenknoten verteilt werden. Das ist besonders wichtig, wenn Daten aus verschiedenen Quellen zusammengeführt oder große Analysen auf Cloud‑Speichern und Data Lakes ausgeführt werden. Statt Daten zunächst vollständig in einen zentralen Speicher zu laden, kann die Engine die Anfrage aufteilen, Teilmengen dort verarbeiten, wo sie liegen, und die Ergebnisse anschließend zusammenführen.
Für Unternehmen kann sich daraus ein praktischer Nutzen ergeben. Wenn Daten in mehreren Systemen verbleiben sollen oder aus Gründen der Governance nicht repliziert werden dürfen, lässt sich mit einer föderierten SQL‑Schicht dennoch ein gemeinsames Analyseerlebnis schaffen. Einsatzmöglichkeiten reichen von klassischen BI-Anwendungen über Datenprodukte bis hin zu KI-Projekten, die auf Daten aus mehreren Quellen zugreifen müssen. Der Hersteller adressiert damit vor allem Unternehmen, die keine Architektur vom Grund auf neu bauen, sondern ihre vorhandene Landschaft schrittweise besser nutzbar machen wollen.
Wichtig ist allerdings die technologische Grenze: Eine föderierte Engine ist keine Abkürzung, wenn Datenqualität, Konsistenz oder Semantik fehlen. Sie kann Zugriffe vereinheitlichen und Latenzen reduzieren, aber sie macht schlechte Daten nicht besser. In vielen Fällen ist deshalb ein Hybridansatz sinnvoll, bei dem besonders häufig genutzte oder Performance-kritische Daten materialisiert werden, während andere Quellen föderiert abgefragt werden. Genau an dieser Stelle wird der Unterschied zwischen einem eleganten Konzept und einer tragfähigen Betriebsarchitektur sichtbar.
Governance und Kontext
Neben der Abfragefunktion hebt Starburst insbesondere Governance- und Sicherheitsfunktionen hervor. Der Hersteller betont Sicherheitsfunktionen, Zugriffskontrolle und die Fähigkeit, Datenquellen zentral kontrollierbar zu machen. Das ist für viele Unternehmen entscheidend, weil eine rein technische Föderation sonst schnell zu einem unübersichtlichen Netz von Zugriffswegen werden würde. Im Idealfall gibt die Plattform damit nicht nur SQL‑Zugriff, sondern auch einen Rahmen für Nachvollziehbarkeit, Berechtigungen und kontrollierte Nutzung.
Besonders relevant ist dieser Punkt im Zusammenhang mit künstlicher Intelligenz (KI). Das Unternehmen möchte auch als Baustein für KI‑Workloads verstanden werden will. Der Ansatz folgt der Annahme, dass KI-Systeme nur dann verlässliche Ergebnisse liefern können, wenn sie auf kontrollierte und kontextualisierte Daten zugreifen. Wenn diese über mehrere Systeme verteilt sind, wird eine Zugriffsschicht mit Governance schnell zum Wegbereiter. Sie ersetzt nicht das Modell, aber sie verbessert die Datenbasis, auf der Modelle und Agents arbeiten.
Als praktische Anwendung dieser Strategie präsentiert Starburst AIDA, einen KI-Assistenten für den Zugriff auf Unternehmensdaten in natürlicher Sprache. Die Leistungsfähigkeit solcher Systeme hängt jedoch maßgeblich von Datenqualität, Kontext und Governance ab.
Gerade hier lohnt sich eine nüchterne Einordnung. Viele Anbieter sprechen im KI‑Kontext von schnellen Ergebnissen und hoher Produktivität. Für die Praxis gilt jedoch: Der Nutzen solcher Plattformen hängt stark von Datenqualität, Metadatenpflege, Domänenverantwortung und Betriebsdisziplin ab. Wer die organisatorische Seite vernachlässigt, bekommt auch mit einer modernen Query‑Schicht keine verlässlichen Ergebnisse.
Typische Einsatzszenarien
Ein Ansatz wie der von Starburst ist besonders dort interessant, wo Daten nicht ohne Weiteres verschoben werden können oder sollen. Das betrifft etwa regulierte Branchen, in denen bestimmte Informationen im Ursprungsystem bleiben müssen. Es betrifft auch Unternehmen mit historisch gewachsenen IT‑Landschaften, die über Jahre unterschiedliche Plattformen aufgebaut haben und nicht alles neu konsolidieren wollen. Ebenso relevant ist der Ansatz für Analysen, bei denen aktuelle Daten aus mehreren Quellen schnell kombiniert werden müssen, etwa in operativen Dashboards, kundenbezogenen Analysen oder KI‑Szenarien mit Live‑Datenzugriff.
Ein typisches Szenario ist die Analyse von Kundendaten, die gleichzeitig in einem CRM-System, einem Cloud-Data-Lake und einem ERP-System liegen. Statt die Daten vollständig zu replizieren, können sie über eine föderierte Abfrageschicht gemeinsam ausgewertet werden.
Darüber hinaus passt der föderierte Zugriff gut zu Data‑Mesh‑Strategien. Wenn Domänen ihre Datenprodukte eigenständig verantworten, ist eine Plattform hilfreich, die den Zugriff über Domänengrenzen hinweg vereinheitlicht, ohne zentrale Engpässe aufzubauen. Genau hier kann eine solche Plattform als technische Schicht dienen, die unterschiedliche Quellen zusammenbringt und zugleich Governance‑Vorgaben durchsetzt. Das macht den Ansatz nicht nur technisch interessant, sondern auch organisatorisch anschlussfähig.
Trotzdem bleibt die Einordnung wichtig: Föderierter Zugriff ist kein Ersatz für jedes Warehouse, und auch kein vollständiger Ersatz für ETL. In Szenarien mit klaren Latenzanforderungen, komplexen Transformationen oder sehr hohem Bedarf an historischen Daten kann eine gezielte Konsolidierung weiterhin sinnvoll sein. Der Nutzen liegt deshalb weniger im Alles‑ersetzt‑Alles, sondern in der gezielten Ergänzung bestehender Architekturen.
Wettbewerb und Marktumfeld
In diesem spezifischen Marktsegment gibt es verschiedene Klassen von Wettbewerbern. Zu den Marktbegleitern zählen unter anderem Denodo, das traditionell stark im Bereich Datenvirtualisierung positioniert ist, sowie Dremio, das föderierte Abfragen mit einer Lakehouse-Strategie kombiniert. Snowflake, Databricks oder BigQuery sind breitere Plattformen, die teils andere Architekturprinzipien verfolgen, aber dennoch in verwandten Entscheidungsprozessen auftauchen. Die Wettbewerbsfrage lautet deshalb nicht nur, welches Produkt ähnliche Funktionen hat, sondern auch, welcher Plattformtyp zur jeweiligen Datenstrategie passt.
Für die Marktposition von Starburst ist vor allem die klare Rolle als Zugriffsschicht relevant. Das Unternehmen will bestehende Datenlandschaften nicht komplett ersetzen, sondern sie über einen föderierten Ansatz schneller und kontrollierter nutzbar machen. Diese Position ist im Markt attraktiv, weil viele Organisationen weder bei null anfangen noch ihre gesamten Bestände in ein neues Zielsystem migrieren wollen. Starburst besetzt damit eine Position zwischen klassischer Datenvirtualisierung und umfassenden Datenplattformen wie Snowflake oder Databricks mit weniger Datenbewegung, mehr Zugriff, mehr Governance und ein höheres Maß an Architekturflexibilität.
Fazit
Die Diskussion um moderne Datenarchitekturen verschiebt sich zunehmend von der Frage der Speicherung hin zur Frage des Zugriffs, der Governance und der Nutzung verteilter Datenbestände. Unternehmen denken Daten heute stärker als verteiltes Gut, das über Governance, Metadaten und föderierte Zugriffsebenen nutzbar gemacht werden muss. Starburst ist ein konkretes Beispiel für diesen Trend: technologisch verwurzelt in Presto und Trino, funktional ausgerichtet auf föderierten SQL‑Zugriff, und organisatorisch relevant für hybride, regulierte oder historisch gewachsene Umgebungen. Für Unternehmen wird damit wichtiger, wie sich verteilte Daten sicher, nachvollziehbar und effizient nutzen lassen, ohne bestehende Architekturen vollständig neu aufzubauen.






