Wie Sie mit Cloud-Designs resilientere Anwendungen erstellen
Cloud-Designmuster wie Bulkhead, Retry und Circuit Breaker helfen, Anwendungen skalierbar und resilient zu gestalten. Weitere Ansätze nutzen Service Meshes und KI.
Schnelles Wachstum ist für jede Anwendung Segen und Fluch zugleich. Es sorgt sowohl für höhere Einnahmen als auch für größere technische Herausforderungen. Um diese Herausforderungen zu bewältigen, sollten Entwickler Cloud-Designmuster in Betracht ziehen.
Designmuster, die Cloud-Anwendungen regeln, werden oft erst diskutiert, wenn Unternehmen eine bestimmte Größe erreicht haben. Es gibt zwar unzählige Designmuster zur Auswahl, aber eine der größten Herausforderungen besteht darin, mit der Skalierung umzugehen, wenn sie notwendig wird. Um Workloads besser zu skalieren, können mehrere Designmuster jede Cloud-Anwendung fehlertoleranter und widerstandsfähiger gegen Probleme aufgrund von erhöhtem Datenverkehr machen.
Diese fünf Cloud-Designmuster helfen Entwicklern dabei, unerwartete Durchsatzsteigerungen besser zu bewältigen:
Erfahren Sie außerdem mehr über verschiedene Best Practices zum Erstellen widerstandsfähiger Anwendungen.
1. Bulkhead
Das Bulkhead-Muster, benannt nach den Trennwänden eines Schiffes, die dazu dienen, Überflutungen zu isolieren, verhindert, dass ein einzelner Ausfall innerhalb einer Anwendung zu einem Totalausfall führt. Die Implementierung dieses Musters ist zwar nicht immer offensichtlich, aber es findet sich typischerweise in Anwendungen, die auch bei verminderter Leistung funktionieren können.
Eine Anwendung, die das Bulkhead-Muster implementiert, ist auf Ausfallsicherheit ausgelegt. Zwar sind nicht alle Vorgänge möglich, wenn E-Mail- oder Caching-Ebenen ausfallen, aber die Anwendung kann mit ausreichender Vorausschau und Kommunikation gegenüber dem Endbenutzer dennoch funktionieren.
Abbildung 1: Das Bulkhead-Muster gewährleistet die Anwendungsfunktionalität, indem es verschiedene Teile der App voneinander isoliert.
Durch isolierte Anwendungsbereiche, die unabhängig voneinander arbeiten können, führen Subsystemfehler lediglich zu einer sicheren Reduzierung der Gesamtfunktionalität, ohne einen Komplettausfall zu verursachen. Ein gutes Beispiel für das Bulkhead-Muster in der Praxis ist jede Anwendung, die im Offline-Modus betrieben werden kann. Während die meisten Cloud-basierten Anwendungen eine externe API benötigen, um ihr volles Potenzial auszuschöpfen, können fehlertolerante Clients ohne die Cloud arbeiten, indem sie auf zwischengespeicherte Ressourcen und andere Workarounds zurückgreifen, um sicherzustellen, dass der Client zumindest eingeschränkt nutzbar ist. Das Bulkhead-Muster wird häufig durch die Nutzung von Containern, Kubernetes-Namespaces oder die Trennung von Microservices umgesetzt, was eine noch stärkere Isolation ermöglicht.
2. Wiederholen (Retry)
In vielen Anwendungen ist ein Ausfall ein endgültiger Zustand. Bei widerstandsfähigeren Diensten kann eine fehlgeschlagene Anfrage jedoch möglicherweise erneut gesendet werden.
Das Wiederholungsmuster, ein gängiges Cloud-Entwurfsmuster für Interaktionen mit Drittanbietern, ermutigt Anwendungen, Ausfälle zu erwarten. Prozesse, die das Wiederholungsmuster implementieren, schaffen fehlertolerante Systeme, die nur minimale langfristige Wartung erfordern. Diese Prozesse werden mit der Fähigkeit implementiert, fehlgeschlagene Vorgänge sicher zu wiederholen.
Abbildung 2: Das Wiederholungsmuster ermöglicht es, fehlgeschlagene Anfragen eine begrenzte Anzahl von Malen erneut zu senden, um den Erfolg zu fördern.
Das Wiederholungsmuster ist häufig in Webhook-Implementierungen zu finden. Wenn ein Dienst versucht, einen Webhook an einen anderen Dienst zu senden, kann diese Anfrage eines von zwei Dingen bewirken:
1. Erfolgreich (Succeed): Wenn die Anfrage erfolgreich ist, wird der Vorgang abgeschlossen.
2. Fehlschlagen (Fail): Wenn die Anfrage fehlschlägt, kann der sendende Dienst den Webhook eine begrenzte Anzahl von Malen erneut senden, bis die Anfrage erfolgreich ist. Um eine Überlastung des Zielsystems zu vermeiden, verwenden viele Webhook-Implementierungen exponentielles Backoff, wodurch die Zeitverzögerungen zwischen den einzelnen Anfragen erhöht werden, um einem fehlerhaften Ziel Zeit zur Wiederherstellung zu geben, bevor es zu einem Fehler kommt. Diese Verzögerungen führen oft zu einer gewissen Zufälligkeit im Timing – dem sogenannten Jitter –, um zu verhindern, dass synchronisierte Wiederholungsversuche das System weiter überlasten.
Das Wiederholungsmuster funktioniert nur, wenn sowohl der Absender als auch der Empfänger wissen, dass fehlgeschlagene Anfragen erneut gesendet werden können. Im Webhook-Beispiel wird oft eine eindeutige Kennung für jeden Webhook bereitgestellt. Der Empfänger kann dann überprüfen, dass eine Anfrage nie mehr als einmal verarbeitet wird. Dadurch werden Duplikate vermieden, während der Absender seine eigenen Fehler erkennen kann, die zu einer fehlerhaften erneuten Übertragung redundanter Daten führen könnten. Heute übernehmen viele Frameworks und Service-Meshes wie Istio, Linkerd oder Resilience4j die Retry-Logik automatisch, inklusive adaptiver Backoff-Strategien, die sich dynamisch an Latenzen und Lastsituationen anpassen.
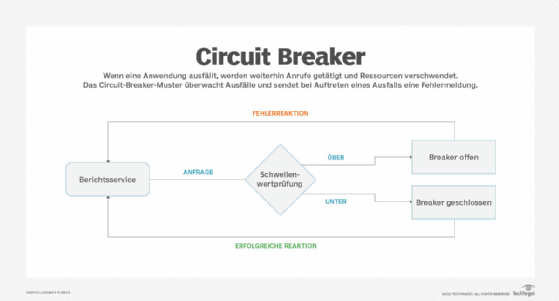
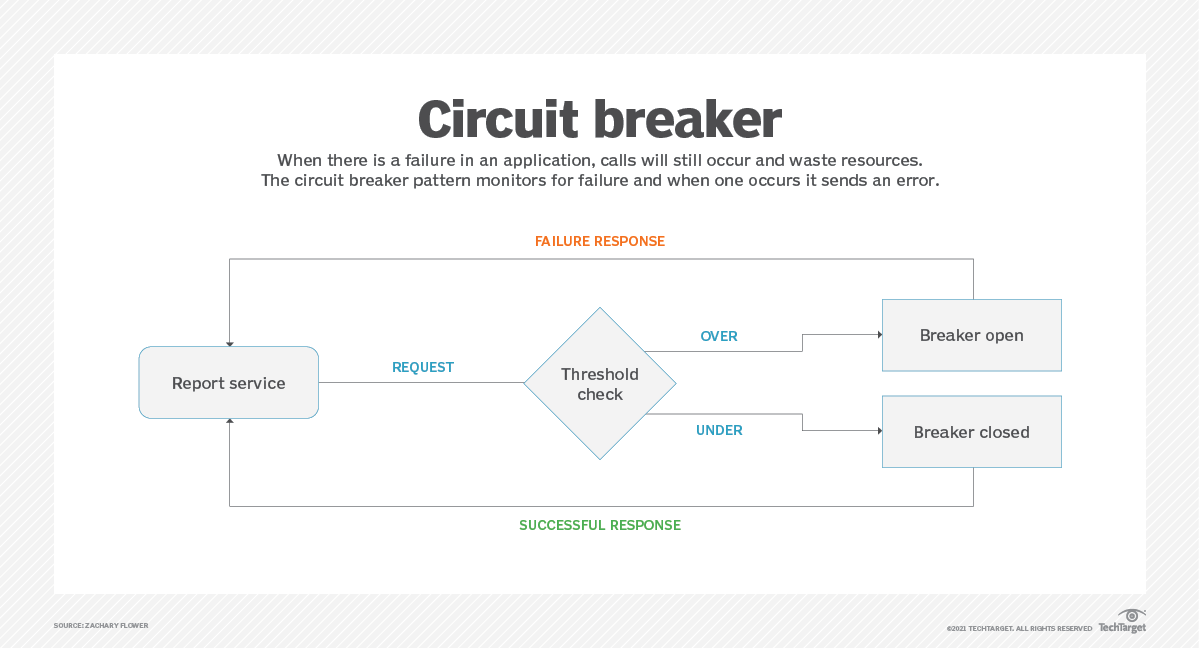
3. Circuit Breaker
Der Umgang mit Skalierung kann in Cloud-Anwendungen ein unglaublich nuanciertes Problem sein, insbesondere bei Prozessen mit unvorhersehbarer Leistung. Das Circuit-Breaker-Muster verhindert, dass Prozesse aus dem Ruder laufen, indem es sie unterbricht, bevor sie mehr Ressourcen als nötig verbrauchen.
Abbildung 3: Das Circuit-Breaker-Muster kann jede Anfrage stoppen, deren Generierung zu lange dauert.
Stellen Sie sich eine Webseite vor, die einen Bericht aus mehreren verschiedenen Datenquellen generiert. In einem typischen Szenario dauert dieser Vorgang möglicherweise nur wenige Sekunden. In seltenen Fällen kann die Abfrage des Backends jedoch viel länger dauern, wodurch wertvolle Ressourcen gebunden werden. Ein Circuit Breaker könnte die Ausführung aller Berichte, deren Erstellung länger als zehn Sekunden dauert, unterbrechen und so verhindern, dass lang laufende Abfragen die Anwendungsressourcen monopolisieren.
Diese Verfahren gehören zu den drei möglichen zuständen eine Circuit Breakers:
1. Geschlossen (Closed)
In diesem Zustand werden alle Anfragen normal weitergeleitet. Auftretende Fehler werden nur gezählt.
2. Offen (Open)
Hierbei werden neue Anfragen nach einer konfigurierten Fehleranzahl sofort abgelehnt, meist mit einer Fallback-Antwort oder einem Fehlercode. Dies vermeidet eine erneute Belastung des fehlerhaften Dientes.
3. Halb-offen (Half-open)
In diesem Fall lässt der Circuit Breaker nach einer bestimmten Zeit testweise einzelne Anfragen durch, um zu prüfen, ob der Zielservice sich erholt hat. Wenn diese Anfragen erfolgreich sind, wechselt er wieder in den Closed-Zustand.
Circuit-Breaker-Implementierungen kombinieren Schwellenwerte mit Telemetriedaten aus Observability-Plattformen und passen ihre Reaktionszeiten dynamisch an. Zudem übernehmen API-Gateways oder Service-Mesh-Komponenten diese Funktion häufig automatisch.
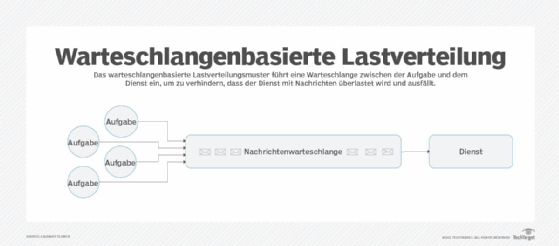
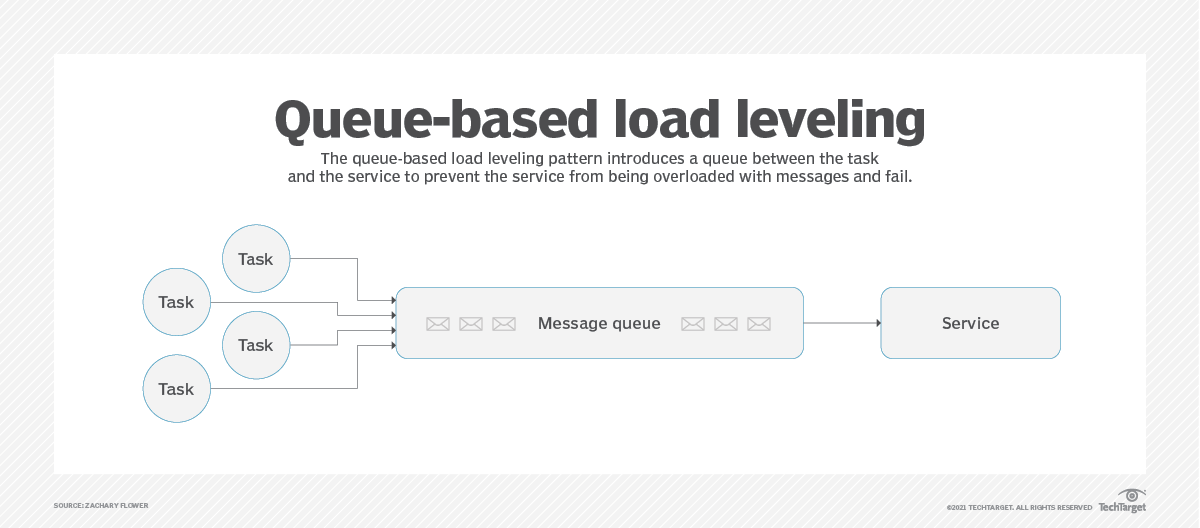
4. Queue-basierte Lastverteilung (QBLL)
Queue-basierte Lastverteilung (QBLL) ist ein gängiges Cloud-Designmuster, bei dem Queues zur Ausführung von Anfragen verwendet werden. Anstatt mehrere komplexe Vorgänge zum Zeitpunkt der Anfrage auszuführen – was zu einer zusätzlichen Latenz bei den für den Benutzer sichtbaren Funktionen führt –, werden diese Vorgänge in eine Queue gestellt. Diese Queue führt innerhalb eines bestimmten Zeitraums weniger Anfragen aus. Dieses Designmuster ist in Systemen von Vorteil, in denen viele Vorgänge keine sofortigen Ergebnisse liefern müssen, wie zum Beispiel das Versenden von E-Mails oder die Berechnung von Gesamtwerten.
Abbildung 4: Das Queue-basierte Lastenausgleichsmuster organisiert Anfragen in einer Warteschlange, um die Ausführung zu verwalten.
Betrachten wir einen API-Endpunkt, der bei jeder Ausführung rückwirkende Änderungen an einem großen Datensatz vornehmen muss. Dieser Endpunkt wurde zwar unter Berücksichtigung einer bestimmten Verkehrsschwelle entwickelt, aber ein starker Anstieg der Anfragen oder ein rasantes Wachstum der Nutzerzahlen könnte sich negativ auf die Latenz der Anwendung auswirken. Durch die Auslagerung dieser Funktion in ein QBLL-System kann die Anwendungsinfrastruktur den erhöhten Durchsatz leichter bewältigen, da jeweils eine feste Anzahl von Vorgängen verarbeitet wird.
Heute werden Queue-basierte Systeme häufig durch ereignisgesteuerte Architekturen mit Diensten wie Kafka, RabbitMQ oder Cloud-Pub/Sub ergänzt, die eine nahezu unbegrenzte horizontale Skalierung und dynamische Lastverteilung ermöglichen.
Im Cloud-Kontext werden für QBLL auch häufig die Begriffe Queue-based Load Leveling oder Queue-based Throttling verwendet.
5. Drosselung (Throttling)
Ein alternatives Designmuster zu QBLL ist das Drosselungsmuster, das in Bezug auf das Noisy-Neighbor-Problem funktioniert. Während das QBLL-Muster überschüssige Arbeitslasten zur besser verwaltbaren Verarbeitung in eine Warteschlange auslagert, legt das Drosselungsmuster Grenzen fest und erzwingt diese hinsichtlich der Häufigkeit, mit der ein einzelner Client einen Dienst oder Endpunkt nutzen kann, um zu verhindern, dass ein einzelner Noisy Neighbor das System für alle anderen negativ beeinflusst. Das Drosselungsmuster kann auch das QBLL-Muster ergänzen. Dies ermöglicht die verwaltete Verarbeitung von überschüssigen Arbeitslasten und stellt sicher, dass die Warteschlangentiefe nicht voll wird.
Abbildung 5: Das Drosselungsmuster erzwingt Beschränkungen hinsichtlich der Häufigkeit, mit der ein Client einen Dienst oder Endpunkt nutzt.
Zurück zum QBLL-Beispiel: Stellen Sie sich vor, das API-Endpoint konnte ursprünglich nur etwa 100 Anfragen pro Minute verarbeiten, bevor die aufwändigen Aufgaben an eine Warteschlange ausgelagert wurden. Die API selbst könnte nun zwar eine maximale Durchsatzrate von 10.000 Anfragen pro Minute unterstützen – ein gewaltiger Sprung im Vergleich zu 100. Die Warteschlange selbst ist jedoch so dimensioniert, dass sie nur etwa 100 Anfragen pro Minute verarbeiten kann, ohne dass der Endnutzer es merkt. Das bedeutet in der Praxis: 1.000 API-Anfragen könnten 10 Minuten zur Bearbeitung benötigen, und 10.000 API-Anfragen könnten bis zu zwei Stunden in Anspruch nehmen.
In einem System mit gleichmäßig verteilten Anfragen erlebt jeder Benutzer gleichermaßen eine langsamere Verarbeitung. Wenn jedoch ein einzelner Benutzer alle 10.000 Anfragen sendet, müssen alle anderen Benutzer eine Verzögerung von zwei Stunden in Kauf nehmen, bevor ihre Arbeitslasten beginnen. Ein Drosselungsschema, das alle Benutzer auf 1.000 Anfragen pro Sekunde beschränkt, stellt sicher, dass kein einzelner Benutzer die Anwendungsressourcen auf Kosten anderer Benutzer monopolisieren kann.
Zusätzlich kommen adaptive Throttling-Mechanismen und Token-Bucket-Modelle zum Einsatz, die ihre Grenzen dynamisch anpassen und so für eine gleichmäßigere Ressourcennutzung sorgen. Dieses Rate Limiting ist ein Verfahren, mit dem die Anzahl von Anfragen an ein System innerhalb eines bestimmten Zeitraums begrenzt wird – etwa 100 Anfragen pro Minute pro Nutzer oder Anwendung. Ziel ist es, Systeme vor Überlastung zu schützen, Missbrauch zu verhindern und eine faire Ressourcennutzung sicherzustellen. Durch solche Begrenzungen kann verhindert werden, dass einzelne Clients – absichtlich oder unbeabsichtigt – die Leistung eines Dienstes für andere beeinträchtigen. In der Praxis wird Rate Limiting mit verschiedenen Verfahren umgesetzt, etwa durch feste oder gleitende Zeitfenster oder durch Modelle wie den Token Bucket, bei dem eine bestimmte Anzahl von Tokens pro Zeitraum verfügbar ist. Diese können kurzfristige Lastspitzen zulassen, werden aber kontinuierlich wieder aufgefüllt. So sorgt Rate Limiting für Stabilität, Sicherheit und gerechte Lastverteilung in verteilten Systemen und APIs.
Bewährte Verfahren für resiliente Anwendungen
Beim Erstellen resilienter Anwendungen geht es nicht nur um die Muster. Es geht auch darum, wie Entwickler über die Anwendungsentwicklung denken und wie sie mit Risk Management, Architektur und Anwendungsdesign umgehen. Im Folgenden finden Sie einige Best Practices, mit denen Sie die oben genannten Muster erfolgreich in Geschäftssystemen anwenden können.
Plan für den Ausfall
Wenn es um Technologie geht, ist ein Ausfall nie eine Frage des Ob, sondern des Wann.
Ein wichtiger Bestandteil der Entwicklung resilienter Anwendungen ist es, davon auszugehen, dass jede Komponente irgendwann ausfällt. Aus dieser Perspektive lässt sich ein Aktionsplan erstellen, indem Bereiche identifiziert werden, in denen eine Anwendung anfällig oder anderweitig anfällig für Skalierungsprobleme sein könnte.
Beschränken Sie sich nicht nur auf einen Plan für den Fall eines Ausfalls. Verursachen Sie Ausfälle mit einer Technik namens Chaos Engineering. Chaos Engineering ist der Prozess der absichtlichen Einführung von Fehlern, Störungen und anderen Ausfällen in ein laufendes System, um die Toleranzen dieses Systems besser zu verstehen. Bekannt geworden durch Netflix ist dies eine gängige Methode, um die Ausfallsicherheit eines Systems zu testen und Anwendern zu helfen, besser zu verstehen, wie sie es verbessern können.
Entkoppelte und isolierte Dienste
Es gibt ein gängiges Muster in der Softwareentwicklung, das als Trennung von Anliegen bezeichnet wird. Bei diesem Muster wird eine Codebasis in verschiedene Komponenten mit jeweils einem Schwerpunktbereich organisiert. Diese lose Kopplung ermöglicht es Entwicklern, skalierbarere und wartungsfreundlichere Systeme zu erstellen. Da die einzelnen Aufgabenbereiche jeder Komponente berücksichtigt werden, verringert sich die Wahrscheinlichkeit, dass ein Ausfall einer Komponente zu einem Ausfall der gesamten Anwendung führt.
Während das Bulkhead-Muster dies auf der Ebene der Infrastruktur erreicht, ist es wichtig, bei der Skalierung andere, fortgeschrittenere Techniken in Betracht zu ziehen. Ereignisgesteuerte Architektur, Datenbank-Sharding und Workload-Partitionierung können Ausfälle eindämmen und die Gesamtstabilität eines Systems erhöhen.
Automatisierte Wiederherstellung
Wiederherstellung ist der Vorgang, bei dem ein ausgefallenes System wieder in einen funktionsfähigen Zustand versetzt wird. Die Wiederherstellung kann jedoch zeitaufwändig sein und Ressourcen und Energie verbrauchen. Der Aufbau einer widerstandsfähigen Anwendung erfordert eine Kultur der ständigen Verbesserung, bei der die Behebung von Ausfällen Priorität hat und die Wiederherstellung für die Zukunft automatisiert wird.
In jedem System gibt es für jeden bekannten Fehlerzustand eine entsprechende Wiederherstellungsmethode. Dies kann eine Skalierung der Ressourcen, das Beenden von außer Kontrolle geratenen Prozessen oder die Umleitung des Datenverkehrs erfordern. Sobald Entwickler ihre Fehlerzustände und Lösungsverfahren identifiziert haben, können sie mithilfe intelligenter Zustandsprüfungen und anderer Überwachungstechniken damit beginnen, die Bedingungen zu identifizieren, die zu diesen Fehlerzuständen führen. Auf diese Weise können Entwickler ein umfassendes System aufbauen, das sich von einem Fehler erholen kann, bevor dieser überhaupt auftritt.
Auslagerung der Resilienzmaßnahmen
Auch wenn einige dieser Entwurfsmuster komplex erscheinen mögen, müssen sie nicht alle von Grund auf selbst entwickelt werden. Oft lohnt es sich, Teile der Resilienz an einen spezialisierten Drittanbieter mit mehr Erfahrung und Expertise auszulagern – beispielsweise an ein API-Gateway, einen Load Balancer oder einen Application Cache. Viele Cloud-Dienste und -Funktionen können den Verwaltungsaufwand und die Komplexität reduzieren und gleichzeitig die Stabilität und Widerstandsfähigkeit einer Anwendung erhöhen.
Ein häufig in diesem Zusammenhang eingesetztes Muster ist das Ambassador Pattern. Dabei dient ein Ambassador – etwa ein API-Gateway – als Proxy zwischen dem Anwendungscode oder Clients und den benötigten Dienstleistungen. In diesem Modell übernimmt der Ambassador die Circuit-Breaker- und Wiederholungslogik, sodass sich die Entwickler auf die Geschäftslogik konzentrieren können.
Austauschbar, nicht einzigartig
In DevOps bedeutet der Ausdruck Rinder, nicht Haustiere (Cattle, not pets) so viel wie austauschbare und nicht einzigartige (komplexe Komponenten. Das heißt, dass die Infrastruktur so aufgebaut sein sollte, dass jeder Dienst und jede Komponente ersetzbar ist und nicht als unersetzbar behandelt wird. Mit anderen Worten: Kümmern Sie sich nicht um die Infrastruktur, wenn sie in einen schlechten Zustand gerät, sondern schaffen Sie einfach eine neue Ressource.
Dies wird als unveränderliche Infrastruktur (Immutable Infrastructure) bezeichnet, bei der der Schwerpunkt auf dem Ersetzen von Anwendungsinstanzen und anderen Diensten liegt, anstatt sie zu patchen. Diese Art der Infrastrukturverwaltung stellt nicht nur sicher, dass nichts jemals veraltet ist, sondern hat auch den zusätzlichen Vorteil, dass sie fortgeschrittenere Bereitstellungstechniken wie Blue-Green- und Canary-Releases ermöglicht. Diese können dazu beitragen, Ausfallzeiten zu vermeiden und den Release-Prozess wesentlich stabiler zu gestalten.
Echte Ausfallsicherheit bedeutet, den physischen Standort Ihrer Infrastruktur zu berücksichtigen und entsprechend zu planen.
Auslegung auf echte Resilienz
Vereinfacht ausgedrückt ist die Cloud eine Ansammlung von Computern, die irgendwo auf der Welt stehen. Kein noch so ausgeklügeltes Chaos Engineering und QBLL kann eine Anwendung vor einem physischen Ausfall in einem Rechenzentrum in Frankfurt schützen. Wahre Ausfallsicherheit und Resilienz bedeutet, den physischen Standort Ihrer Infrastruktur zu berücksichtigen und entsprechend zu planen.
Die Bereitstellung über mehrere Regionen oder Verfügbarkeitszonen hinweg kann zu einem sicheren Failover beitragen, falls das primäre Rechenzentrum eines Unternehmens ausfällt. Entwickler, die auf Nummer sicher gehen wollen, sollten eine Multi-Cloud-Strategie verfolgen, um nicht nur den Ausfall eines regionalen Rechenzentrums, sondern auch den eines gesamten Cloud-Anbieters zu überstehen.
Die 6-Monats-Regel
Es kann unglaublich schwierig sein, eine Cloud-Anwendung zu skalieren. Oft müssen IT-Teams zwischen der Implementierung eines Designmusters wählen, das das Wachstum der Anwendung für weitere sechs Monate unterstützt, oder einem Designmuster, das das Wachstum der Anwendung für weitere sechs Jahre unterstützt.
Meiner Erfahrung nach sind Optionen, die unter die Sechsmonatsfrist fallen, am kostengünstigsten. Verbringen Sie ein paar Wochen damit, sich für sechs Monate einzukaufen, um die Anforderungen des Unternehmens und der Benutzer zu erfüllen. Das ist effektiver, als ein Jahr damit zu verbringen, ein umfangreicheres System aufzubauen, das schwieriger zu ändern ist.
Ein mittelfristiger Fokus ist nicht dasselbe wie kurzsichtige Hacks und Notlösungen. Die sorgfältige Implementierung gängiger Designmuster kann die langfristige Wartung einer Anwendung unterstützen und ist gleichzeitig flexibel genug, um sich an veränderte Umstände anzupassen.
Diese Regel ist aber eher als eine Empfehlung als eine etablierte Designregel anzusehen.
Aktuelle Entwicklungen
In den letzten Jahren haben sich mehrere neue Ansätze etabliert, die klassische Cloud-Designmuster erweitern oder automatisieren. Eine zentrale Rolle spielen dabei Service-Meshes wie Istio oder Linkerd, die Funktionen wie Retry, Circuit Breaking oder Timeouts ohne Anpassung des Anwendungscodes übernehmen. Auch eventgesteuerte Architekturen sind heute Standard: Sie ermöglichen eine dynamische Lastverteilung und Skalierung in nahezu Echtzeit, insbesondere bei Microservices und serverlosen Architekturen. Trotz dieser Optionen muss der Admin in der Praxis bei Setup und Konfiguration mit Aufwand rechnen. Ganz ohne Mühe geht es nicht.
Darüber hinaus gewinnen KI-gestützte Ansätze an Bedeutung. Mit Hilfe von AIOps und Machine-Learning-basierten Observability-Tools können Systeme Lastspitzen vorausschauend erkennen und automatisch skalieren, bevor Engpässe entstehen. SLO- und SLA-gesteuertes Design sorgt zudem dafür, dass Anwendungen ihre Resilienzziele kontinuierlich und messbar einhalten. Allerdings stehen diese Technologien noch am Anfang ihrer Entwicklung.
Ein weiterer Trend ist die tiefere Integration von Infrastruktur und Code: Infrastructure as Code (IaC) und Policy as Code machen es möglich, Resilienzanforderungen von Anfang an in den Entwicklungsprozess einzubetten. Schließlich wächst der Fokus auf Multi-Cloud- und Hybrid-Szenarien, bei denen Ausfallsicherheit nicht mehr nur innerhalb einer Cloud, sondern über verschiedene Anbieter und Regionen hinweg geplant wird. Zusammen führen diese Entwicklungen dazu, dass klassische Muster nicht verschwinden, sondern als Teil eines größeren, automatisierten Resilienz-Ökosystems betrachtet werden.
Cloud-Designmuster für skalierbare und resiliente Anwendungen
Schnelles Wachstum bringt Chancen und technische Herausforderungen. Cloud-Designmuster wie Bulkhead, Retry, Circuit Breaker, Queue-based Load Leveling und Drosselung erhöhen die Ausfallsicherheit und Skalierbarkeit von Anwendungen deutlich. Ergänzt durch Chaos Engineering, entkoppelte Dienste und automatisierte Wiederherstellung entstehen Systeme, die auf Fehler vorbereitet sind. Service Meshes, Event-gesteuerte Architekturen und KI-gestützte Skalierung erweitern diese Ansätze und sorgen für mehr Resilienz und Flexibilität.









{kind=link}
{kind=link}
{kind=link}