
Jenseits von RDBMS: Data Warehouse, Data Lake und Data Mart
Die Datenmassen lassen sich mit relationalen Datenbanken nicht mehr verarbeiten. An deren Stelle treten Data Warehouses, Data Lakes und Data Marts.

Die Datenmengen, die Organisationen heute aus verschiedenen Quellen sammeln, übersteigt das, was herkömmliche relationale Datenbanken verarbeiten können. Dies führt zu der Frage, welchen Datenspeicher man an deren Stelle nutzen kann: Data Warehouse oder Data Lake? In welchen Fällen kann man welchen Datenspeicher einsetzen? Und wie hängen diese beiden Systeme mit Data Marts, operativen Datenspeichern und relationalen Datenbanken zusammen?
Alle diese Datenspeicher haben eine ähnliche Kernfunktion: sie speichern Daten für Geschäftsberichte und Analysen. Aber ihr Zweck, die Art der Daten, die sie speichern, aus welchen Quellen sie stammen dürfen und wer Zugriff darauf hat, unterscheiden sie.
In der Regel kommen Daten in diese Speicher aus Systemen, die Daten generieren – CRM-, ERP-, HR-, Finanzanwendungen und andere Quellen. Auf die in diesen Programmen erzeugten Datensätze werden Geschäftsregeln angewendet und dann an ein Data Warehouse, einen Data Lake oder einen anderen Datenspeicher gesendet.
Sobald alle Daten aus den verschiedenen Geschäftsanwendungen auf einer Datenplattform abgelegt sind, können sie in Business Analytics Tools verarbeitet werden. Mit diesen lassen sich Trends erkennen oder Erkenntnisse liefern, die bei Geschäftsentscheidungen helfen.
Data Warehouse versus Data Lake
Unternehmen präferieren in der Regel ein Data Warehouse vor einem Data Lake, wenn sie eine große Menge an Daten aus operativen Systemen besitzen, die für die Analyse leicht verfügbar sein muss. Data Warehouses sind oft die Single Source of Truth, da diese Plattformen historische Daten speichern, die bereinigt und kategorisiert wurden.
Während ein Data Warehouse große Datenmengen aus operativen Systemen aufnimmt, speichert ein Data Lake Daten aus mehreren Quellen. Bei diesen Daten handelt es sich im Wesentlichen um eine Sammlung unterschiedlicher Rohdatenbestände, die aus den operativen Systemen und anderen Quellen eines Unternehmens stammen.
Da die Daten in den Data Lakes normalerweise nicht bearbeitet werden und möglicherweise von Quellen von externen Unternehmenssystemen stammen, sind sie für den durchschnittlichen Business-Analytics-Anwender nicht geeignet. Dafür sind Data Lakes das El Dorado für Data Scientists und anderen Datenanalyseexperten.
Um den Unterschied zwischen einem Data Warehouse und einem Data Lake auf den Punkt zu bringen, orientieren Sie sich am besten an der wörtlichen Bedeutung der Begriffe: Stellen Sie sich einfach reale Lagerhäuser und Seen vor: Lagerhäuser lagern bereits bearbeitete Waren aus bestimmten Quellen. Ein See hingegen wird aus Flüssen, Bächen und anderen Quellen gespeist und der Inhalt ist unbearbeitet.
Zu den Anbietern von Data Warehouses gehören unter anderem Amazon Web Services (AWS), Cloudera, IBM, Google, Microsoft, Oracle, Teradata, SAP, SnapLogic und Snowflake. Data Lake Tools sind bei AWS, Google, Informatica, Microsoft, Teradata und anderen Datenmanagement-Providern erhältlich.
Data Warehouse versus Data Mart
Data Marts werden oft mit Data Warehouses verwechselt. Beide unterscheiden sich jedoch und dienen unterschiedlichen Zwecken.
Ein Data Mart ist typischerweise eine Teilmenge eines Data Warehouses. Die darin enthaltenen Daten stammen oft aus einem Data Warehouse – allerdings können sie auch aus einer anderen Quelle bezogen werden. Das Charakteristische an Data Marts ist: Die dort abgelegten Daten werden immer für bestimmte Zwecke – wie zum Beispiel eine Finanzanalyse – gespeichert. Die Data-Mart-Daten sind deshalb immer für eine bestimmte Nutzergemeinde bestimmt, wie zum Beispiel ein Verkaufsteam.
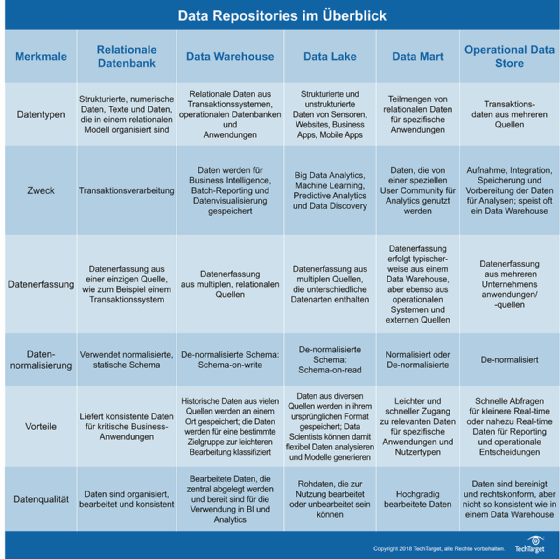
Damit die Anwender die Daten schnell finden, sind sie hochgradig bearbeitet. Data Marts sind auch viel kleiner als Data Warehouses – sie halten in der Regel nur Dutzende von Gigabyte gegenüber den Hunderten von Gigabyte bis Petabyte an Daten, die typischerweise in einem Data Warehouse gespeichert werden.
Data Marts können aus einem bestehenden Data Warehouse oder einer anderen Datenquelle gespeist werden. Der Aufbau geschieht so, dass die Datenbanktabelle entworfen und konstruiert, mit relevanten Daten gefüllt wird und dann entschieden wird, wer darauf zugreifen darf.
Data Warehouses versus ODS
Ein Operational Data Store (ODS) dient als Zwischenspeicher für alle Daten, die in das Data Warehouse gelangen sollen. Im ODS können Daten vor der Speicherung im Data Warehouse bereinigt, auf Redundanz geprüft und auf Einhaltung der Geschäftsregeln überprüft werden. Im übertragenen Sinn kann man ein OSS als die Laderampe des Warehouses betrachtet. Über diese Rampe werden die Waren angeliefert, geprüft und verifiziert.
In einem ODS können die Daten bereits abgefragt werden, sie sind jedoch flüchtig, so dass sie nur bestimmte Informationen – beispielsweise über den Status eines laufenden Kundenauftrags – liefern.
Ein ODS wird typischerweise auf einem relationalen Datenbankmanagementsystem oder auf einer Hadoop-Plattform ausgeführt. Die Datenversorgung des ODS erfolgt über Datenintegrations- und Datenerfassungswerkzeuge wie Attunity Replicate oder Hortonworks DataFlow.
Relationale Datenbanken versus Data Warehouses und Data Lakes
Was ist der Hauptunterschied zwischen einem Data Warehouse, einem Data Lake und einem relationalen Datenbanksystem? Eine relationale Datenbank wird verwendet, um strukturierte Daten aus einer einzigen Quelle – wie einem Transaktionssystem – zu speichern und zu organisieren. Data Warehouses hingegen können strukturierte Daten aus mehreren Quellen ablegen. Data Lakes wiederum unterscheiden sich von beiden dadurch, dass sie sowohl strukturierte als auch halbstrukturierte und unstrukturierte Daten speichern können.
Relationale Datenbanken sind relativ einfach zu erstellen und können genutzt werden, um Transaktionsdaten zu speichern und zu organisieren. Der Nachteil von relationalen Datenbanken ist, dass sie keine unstrukturierten Daten unterstützen. Auch mit großen Datenmengen, wie sie heute oft erzeugt werden, können sie nicht gut umgehen. Das bringt uns zur Entscheidung Data Warehouse versus Data Lake. Trotz der Nachteile relationaler Datenbanken setzen viele Unternehmen heute noch auf relationale Datenbankmanagementsysteme für Aufgaben wie operationale Datenanalyse oder Trendanalyse.
Zu den relationalen Datenbanken, die On-Premises oder in der Cloud verfügbar sind, gehören zum Beispiel Microsoft SQL Server, Oracle Database, MySQL und IBM DB2 sowie Amazon Relational Database Service und Google Cloud Spanner.







