
Scale Across: Qumolo definiert File Storage neu
Startup Qumolo glaubt, dass modernes File Storage einen hybriden Ansatz braucht und hat seine Produkte entsprechend konzipiert. Wir erklären, was der Hersteller anbietet.

Das junge Unternehmen Qumulo verfolgt einen neuen Ansatz für File Storage und will Firmen wie Netapp, Isilon oder Pure Storage Konkurrenz machen. Auch Marktbegleiter für Objektspeicher könnten ins Visier gelangen, wie die Pläne des Unternehmens zeigen werden.
Qumulo fokussiert sich auf eine „Flash-first“ hybride Architektur, die Dateien über unterschiedliche Hardware und in die Cloud verteilen und verwalten. Mittels Echtzeitanalysen lassen sich zudem zusätzliche Informationen aus den Daten gewinnen und das Management entsprechend anpassen. Das Unternehmen selbst bezeichnet seine Technologie als „Scale across hybrid architecture“ und ist letztlich eine Mischung aus Scale-out-NAS mit Datenmanagement, Analysen und Storage-Ressourcen-Management. Dabei lassen sich reine Flash-Systeme, hybride Speicher und vor allem auch die Cloud einbeziehen. Möglich wird dieser Ansatz durch das File System, das dafür konzipiert wurde: Qumulo File Fabric (QF2).
Das Herz der Lösung: File System QF2
Qumulo File Fabric (QF2) ist ein hochskalierbares Dateispeichersystem, welches Rechenzentren und die Public Cloud umfasst. Es skaliert laut Herstellerangaben auf Milliarden von Dateien. QF2 verschiebt Dateidaten dorthin, wo sie gebraucht werden, wenn sie benötigt werden, z.B. zwischen lokalen Clustern und Clustern, die in der Cloud ausgeführt werden. Mit QF2 lassen sich umfangreiche Datensätze in mehreren Umgebungen und an jedem Ort der Welt speichern und verwalten. Die Software von QF2 läuft auf Standardhardware vor Ort oder auf Cloud-Instanzen und Cloud-Speicherressourcen.
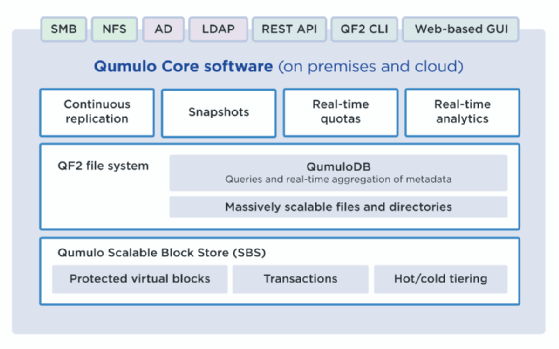
Das File System hat eine verteilte Architektur, bei der viele einzelne Nodes zu einem Cluster mit skalierbarer Leistung und einem einzigen, einheitlichen Dateisystem verbunden werden. QF2-Cluster wiederum arbeiten zusammen, um eine global verteilte, hoch vernetzte Speicherstruktur zu bilden, die mit kontinuierlichen Replikationen verbunden ist. Die QF2-Clustern können über branchenübliche Dateiprotokolle, die QF2 REST-API und eine webbasierte grafische Benutzeroberfläche (GUI) angesprochen werden.
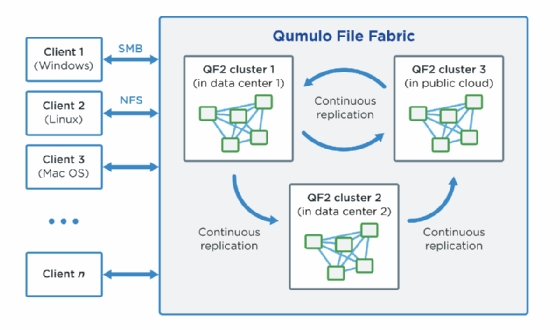
Die Architektur ist modular und bei Bedarf lassen sich Nodes in einer linearen Skalierung hinzufügen, unabhängig davon ob im eigenen RZ oder in der Cloud. Zu den Funktionen gehören Echtzeitanalysen und Kapazitäts-Quotas sowie kontinuierliche Replikation und Snapshots sowie eine integrierte Echtzeit-Aggregation von Datei-Metadaten.
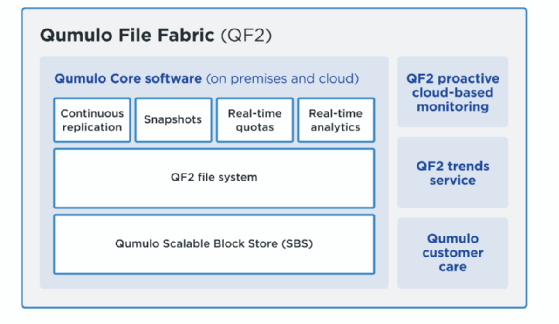
Das Dateisystem basiert auf einem Datenmanagementsystem namens Qumulo Scalable Block Store (SBS). SBS nutzt die Prinzipien massiv skalierbarer verteilter Datenbanken und ist für die speziellen Anforderungen dateibasierter Daten optimiert. Der Scalable Block Store ist die Blockschicht des QF2-File Systems, die dieses Dateisystem einfacher zu implementieren und robust macht.
QF2 bietet Cloud-basiertes Monitoring und Trendanalysen. Das Cloud-Monitoring umfasst die proaktive Erkennung von Ereignissen wie Festplattenausfällen, um Probleme zu vermeiden, bevor sie auftreten. Der Zugriff auf historische Trends soll helfen, Kosten zu senken und Arbeitsabläufe zu optimieren. Das File System ist hardwareunabhängig und funktioniert auf Qumulo-Systemen ebenso wie auf HPE- oder anderen Produkten. Sowohl On-Premises als auch. In der Cloud nutzt QF2 Block Storage mit geringer Latenz vor dem Blockspeicher mit höherer Latenz (Flash-first).
Auf jeder Node eines QF2-Clusters läuft Qumulo Core im Linux User Space und nicht im Kernel. Der Kernel-Modus ist in erster Linie für Gerätetreiber gedacht, die mit bestimmter Hardware arbeiten. Durch den Einsatz im User Space kann das File System in einer Vielzahl von Konfigurationen und Umgebungen eingesetzt werden und bietet zudem Funktionen in viel kürzerer Zeit.
Wenn QF2 im User Space läuft, kann es auch eigene Implementierungen von wichtigen Protokollen wie SMB, NFS, LDAP und Active Directory haben. Beispielsweise läuft die Implementierung von NFS durch QF2 als Systemdienst und hat eigene Übersicht von Benutzern und Gruppen, die sich vom zugrunde liegenden Betriebssystem, auf dem sie läuft, unterscheiden.
Das Ausführen im User Space kann auch die Zuverlässigkeit des Systems verbessern. Als unabhängiger User-Space-Prozess ist QF2 von anderen Systemkomponenten isoliert, die zu einer Beschädigung des Speichers führen könnten, und die QF2-Entwicklungsprozesse können fortschrittliche Speicherverifikations-Tools nutzen, die es ermöglichen, speicherbezogene Kodierungsfehler vor der Softwarefreigabe zu erkennen. Durch die Verwendung einer Doppelpartition für Software-Upgrades kann der Hersteller sowohl das Betriebssystem als auch die Core-Software automatisch aktualisieren, um schnelle und zuverlässige Upgrades zu ermöglichen.
Sind zahlreiche Files zu bewältigen, so werden die Verzeichnisstruktur und die Dateiattribute selbst zu Big Data. Folglich sind sequentielle Prozesse wie so genannte Tree Walks die für die Legacy-Storage von grundlegender Bedeutung sind, nicht mehr machbar. Stattdessen erfordert die Abfrage eines großen Dateisystems und dessen Verwaltung einen neuen Ansatz, der parallele und verteilte Algorithmen verwendet, weswegen QF2 entwickelt wurde. Das Design basiert auf Prinzipien, die denen moderner, groß angelegter und verteilter Datenbanken ähneln. Das Ergebnis ist ein Dateisystem mit guten Skalierungseigenschaften.
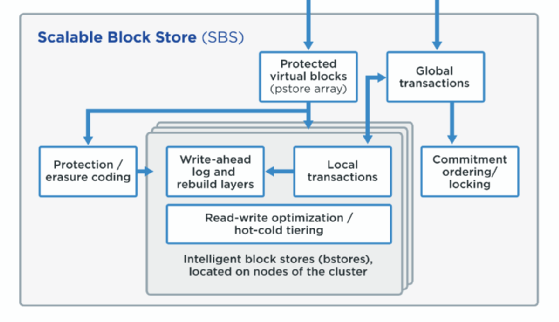
Wie erwähnt liegt das File System auf einer virtualisierten Blockschicht namens SBS. Die virtualisierte Block Data Protection von SBS ist ein Vorteil für das QF2-Dateisystem. In älteren Speichersystemen ohne SBS erfolgt der Schutz dateiweise oder über feste RAID-Gruppen, was lange Wiederherstellungszeiten, ineffiziente Speicherung kleiner Dateien und kostspielige Verwaltung von Festplattenlayouts mit sich bringen kann. Ohne eine virtualisierte Blockschicht müssen Legacy-Speichersysteme auch Data Protection innerhalb der Metadatenschicht selbst implementieren, und diese zusätzliche Komplexität schränkt die Fähigkeit dieser Systeme ein, verteilte Transaktionen für ihre Verzeichnisdatenstrukturen und Metadaten zu optimieren.
Für die Skalierbarkeit von Dateien und Verzeichnissen nutzt das QF2 weitgehend Indexdatenstrukturen, die als B-Trees bekannt sind. B-Trees eignen sich besonders gut für Systeme, die eine große Anzahl von Datenblöcken lesen und schreiben, da es sich um „flache“ Datenstrukturen handelt, die mit zunehmender Datenmenge die für jeden Vorgang erforderliche I/O-Menge minimieren. Mit B-Trees als Grundlage wachsen die Rechenkosten für das Lesen oder Einfügen von Datenblöcken mit zunehmender Datenmenge nur sehr langsam, was sie ideal für Dateisysteme und sehr große Datenbankindizes macht.
Die Qumulo Datenbank
Die QumuloDB umfasst vor allem Echtzeit-Aggregation von Metadaten und Metadaten Queries und Sampling. Die QumuloDB-Analysen sind im File System vollständig integriert. In älteren Systemen werden Metadatenabfragen oft außerhalb des Kerndateisystems von einer unabhängigen Softwarekomponente beantwortet. Da das Dateisystem auf B Trees basiert, kann QumuloDB Analytics ein System von Echtzeit-Aggregaten verwenden. Die QumuloDB-Analysen sind möglich, da das Dateisystem durch die Verwendung der B-Tree-Indizes und der virtualisierten geschützten Blöcke und Transaktionen des Qumulo Scalable Block Store (SBS) ein optimiertes Design aufweist.
In QF2 werden Metadaten wie verwendete Bytes und Anzahl der Dateien aggregiert, während Dateien und Verzeichnisse erstellt oder geändert werden. Dies bedeutet, dass die Informationen für eine zeitnahe Verarbeitung ohne teure Dateisystem-Tree Walks zur Verfügung stehen. Die Datenbank pflegt aktuelle Metadatenzusammenfassungen. Es verwendet die B-Trees des Dateisystems um Informationen über das Dateisystem zu sammeln, wenn Änderungen vorgenommen werden. Verschiedene Metadatenfelder werden innerhalb des Dateisystems zusammengefasst, um einen virtuellen Index zu erstellen. Die Performance-Analysen, die in der GUI erscheinen und mit der REST-API abrufbar sind, basieren auf Stichprobenmechanismen, die in das Dateisystem integriert sind. Statistisch valide Sampling-Techniken sind durch die Verfügbarkeit aktueller Metadatenzusammenfassungen möglich, die es ermöglichen, Algorithmen zu samplen, um größeren Verzeichnissen und Dateien mehr Gewicht zu verleihen. Die Aggregation von Metadaten in QF2 erfolgt nach einem Bottom-up- und Top-down-Ansatz.
Wenn jede Datei (oder jedes Directory) mit neuen aggregierten Metadaten aktualisiert wird, wird ihr übergeordnetes Verzeichnis als „dirty“, also schmutzig, markiert und ein weiteres Update-Ereignis für das übergeordnete Verzeichnis in die Warteschlange gestellt. Auf diese Weise werden Dateisysteminformationen gesammelt und aggregiert, während sie im Tree weitergegeben werden. Die Metadaten verbreiten sich von der einzelnen Node auf der untersten Ebene bis zur Wurzel des Dateisystems, da auf die Daten in Echtzeit zugegriffen wird. Jede Datei- und Verzeichnisoperation wird berücksichtigt, und diese Informationen werden schließlich bis zum Kern des Dateisystems weitergegeben.
Für die Queries und Samples der Metadaten musste der Hersteller auch einen neuen Ansatz finden, da die Darstellung aller Durchsatzoperationen und IOPS innerhalb der GUI nicht möglich wäre aufgrund der Größe des Dateisystems. Stattdessen verwenden QumuloDB-Abfragen Wahrscheinlichkeits-Sampling, um eine statistisch valide Annäherung an die benötigten Informationen bereit zu stellen. IOPS-Lese- und Schreibvorgänge sowie Lese- und Schreibvorgänge für den I/O-Durchsatz werden aus Samples generiert, die aus einem In-Memory-Puffer mit 4.096 Einträgen gesammelt wurden, der alle paar Sekunden aktualisiert wird.
So wie die Echtzeit-Aggregation von Metadaten die Echtzeit-Analyse von QF2 ermöglicht, so garantiert sie auch Echtzeit-Kapazitätsquoten (Quotas). Diese Quotas ermöglichen es Administratoren, festzulegen, wie viel Kapazität ein bestimmtes Verzeichnis für Dateien verwenden darf. Wenn ein Administrator beispielsweise sieht, dass ein betrügerischer Benutzer ein Unterverzeichnis zu schnell wachsen lässt, kann der Administrator die Kapazität des Verzeichnisses dieses Benutzers sofort begrenzen.
Das Produktportfolio
Das Unternehmen offeriert verschiedene Produktlinien: die Capacity-Serie, die High-Performance-Serie sowie Nearline Archives. Die High-Performance-Serie umfasst die Modelle Qumulo P-Series 23T mit 23 TByte und Qumulo P-Series 92T mit 92 TByte Speicherkapazität. Beide Systeme sind All-Flash-Produkte und sollen Wettbewerbern wie Isilon und Pure Storage das Leben schwer machen.
Die Capacity-Serie ist umfassender und enthält Hardware-Lösungen von Qumulo, Dell und HPE sowie eine SDS-Lösung. Qumulo bietet hier sieben unterschiedliche Systeme an, die jeweils einen Mix aus SSDs und Festplatten aufweisen. Die Kapazitäten reichen von 24 Tbyte bis hin zu 360 TByte in einem Array. In der Regel verfügt eine Einstiegskonfiguration über vier Nodes, damit Ausfallsicherheit gegeben ist. Darüber hinaus gehören der Dell EMC Server PowerEdge R740xd und die HPE Apollo Gen 9 Server zur Capacity-Produktlinie.
Als Nearline Archiv ist ein Sechs-Node-Einstiegs-Array von Qumulo. Erhältlich, dass sich in 144 TByte-Inkrementen erweitern lässt (1-U-Chassis mit 12x 12-TByte-HDDs). Auch in dieser Produktlinie ist ein HPE-System zu finden, der HPE Apollo 4200 Gen 9 Server.
Als Cloud-Lösungen werden derzeit AWS und Google unterstützt, aber das Unternehmen bestätigte Pläne, auch Microsofts Cloud-Angebote zu unterstützen, um eine größere Service-Auswahl bieten zu können.
In Kürze werden auch vermehrt Object-Storage-Projekte ins Auge gefasst. In einem ersten. Schritt soll das API erweitert werden und Firmen wie Cloudian als Erweiterung des Scale-Acrosss-Gedanken hinzufügen. Langfristig plant Qumulo allerdings, ein eigenes API zu entwickeln, mit dem sich Object Storage direkt ansprechen lässt. Keine guten Nachrichten für Firmen wie Scality.
Das Unternehmen im Kurzüberblick
Qumulo wurde 2012 von Peter Godman, Aaron Passey, und Neal Fachan gegründet. Alle drei Gründer waren maßgeblich an der Entwicklung des Scale-out-NAS von Isilon beteiligt. Im März 2015 ging das Unternehmen offiziell an den Markt. CEO Godman verließ die Firma 2018, Passey bereits 2016. Passey arbeitet nun als Principal Engineer bei Dropbox, Godmans Pläne sind bislang nicht bekannt.
Die Firma kann vier erfolgreiche Funding-Runden verzeichnen, die insgesamt rund 219 Millionen US-Dollar einbrachten. Das Unternehmen ist in Seattle, Washington, ansässig und verfügt über Büros in Minneapolis, Minnesota, und Vancouver, Canada sowie weitere internationale Präsenz, beispielsweise in Europa, so auch in Deutschland. Auch zum deutschen Team gehören „alte Hasen“ der Branche: Dr. Thore Rabe, General Manager EMEA (ehemals Data Domain und Dell EMC), Dr. Stefan Radtke, Technical Director EMEA (vormals Isilon/Dell EMC und IBM) und Ingmar Loeke, Director Sales DACH (davor Isilon/Dell EMC, NetApp und Pure Storage).
Für die ersten Erfolge der Firma waren sicher nicht nur das Produkt und ein gutes Team verantwortlich, sondern auch maßgeblich Partner wie HPE oder Dell EMC.







