
Wimon - stock.adobe.com
Data Lake versus Data Warehouse: Die wichtigsten Unterschiede
Data Lakes und Data Warehouses unterscheiden sich in Struktur, Verarbeitung und Anwendungsfällen – und bieten jeweils spezifische Vorteile für Analysen und Datenstrategien.

Die riesigen Datenmengen, die Unternehmen heute sammeln, übersteigen zunehmend die Kapazitäten herkömmlicher relationaler Datenbanken. Zudem wird die Vielfalt der Datenquellen – von strukturierten Log-Dateien bis hin zu unstrukturierten Inhalten – immer größer. Klassische Business-Intelligence-, Analytics- und Data-Science-Anwendungen stoßen damit an ihre Grenzen.
Vor diesem Hintergrund steiogt der Bedarf an Data Lakes und Data Warehouses . Sie sollen auch sehr große und unkonventionelle Daten effizient speichern, verwalten, und für Analysezwecke nutzbar machen. Das wirft die Frage auf, wann welches System verwendet werden sollte und wie sie sich voneinander unterscheiden.
Beide Data Repositorys haben Gemeinsamkeiten, unterscheiden sich jedoch auch. Sowohl Data Warehouses als auch Data Lakes speichern Geschäftsdaten für Analysen und Berichte, setzen jedoch hinsichtlich Zweck, Struktur, unterstützter Datentypen, Datenquellen und typischer Benutzergruppen andere Schwerpunkte. Wer die Unterschiede kennt, versteht auch besser die jeweilige Rolle von Data Lakes und Data Warehouses innerhalb der Analysestrategien von Unternehmen.
Grundsätzlich speisen die verschiedenen Systeme, die Daten generieren, beide Repositorys. Zu diesen datengenerierenden Systemen gehören beispielsweise: CRM-, ERP-, HR- und Finanzanwendungen sowie mobile Apps, Echtzeit-Datenströme, Netzwerk- und Website-Protokolle, Sensoren und andere Quellen. Die Daten werden gemäß den jeweiligen Geschäftsregeln aufbereitet und anschließend zur dauerhaften Ablage und Verwaltung in ein Data Lake oder Data Warehouse übertragen.
Sobald die Daten aus unterschiedlichen Geschäftsanwendungen, IoT-Geräten und externen Quellen integriert sind, können Unternehmen diese analysieren und Trends erkennen, Erkenntnisse gewinnen und fundierte Geschäftsentscheidungen treffen.
Auf konzeptioneller Ebene enthält ein Data Lake in der Regel verschiedene Arten von Big Data, darunter Rohdaten, halbstrukturierte Daten und Streaming-Daten, und wird häufig für fortgeschrittene Analysen, Machine-Learning-Modelle oder Data-Science-Projekte genutzt. Ein Data Warehouse hingegen speichert in erster Linie strukturierte Transaktionsdaten und dient klassischen BI-, Analyse- und Reporting-Zwecken.
Sehen wir uns im Folgenden die beiden Datenspeicher und ihre Unterschiede genauer an.
Was ist ein Data Lake?
Ein Data Lake ist ein zentraler Speicherort, in dem Rohdaten in ihrem ursprünglichen, nativen Format abgelegt werden. Der große Vorteil eines Data Lakes besteht darin, dass er Daten unterschiedlichster Struktur speichern kann – nicht nur klassische, strukturierte Daten. Jedes gespeicherte Datenelement wird dabei mit einer eindeutigen Kennung und Metadaten versehen, um spätere Abfragen und Analysen zu erleichtern.
Ein weiteres zentrales Merkmal von Data Lakes ist, dass sie zum Zeitpunkt der Datenerfassung kein vordefiniertes Schema erfordern. Stattdessen legen Datenwissenschaftler und Analysten erst nach Abschluss des Erfassungsprozesses ein Schema an, filtern die Daten und bereiten sie für spezifische Analysezwecke auf.
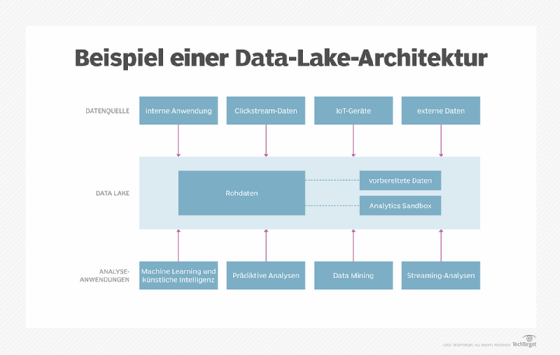
Ursprünglich wurden Data Lakes vor allem mit dem Hadoop-Framework für verteilte Datenverarbeitung umgesetzt. Mit dem steigenden Datenaufkommen in Unternehmen haben sich die Architekturoptionen jedoch erweitert. Heute kommen auch andere Big-Data-Plattformen sowie Cloud-Lösungen zum Einsatz, häufig in Kombination mit Spark-Processing-Engines und Cloud-Objektspeicher-Diensten.
Was ist ein Data Warehouse?
Ein Data Warehouse dient als Speicher für Daten, die von Geschäftsanwendungen generiert oder erfasst und für vorab festgelegte Analysezwecke aufbereitet werden. Die meisten Data Warehouses basieren auf relationalen Datenbanken und nutzen ein festgelegtes Schema, in das die Daten geladen werden. Vor der Speicherung werden die Daten in der Regel bereinigt, konsolidiert und strukturiert.
Da die Daten in einem Data Warehouse bereits aufbereitet sind, lassen sich damit hochwertige Analysen vergleichsweise einfach durchführen. Geschäftsführer und andere Mitarbeiter, die keine erfahrenen Daten- oder Analyseexperten sind, können beispielsweise Self-Service-BI-Tools verwenden, um selbst auf die Daten zuzugreifen und Auswertungen erstellen.
Eine weitere Differenzierung gilt es zu beachten: Ein Enterprise Data Warehouse bietet ein zentrales Daten-Repository für das gesamte Unternehmen. Kleinere Data Marts hingegen können auf einzelne Abteilungen zugeschnitten sein. Wie bei Data Lakes setzen Unternehmen zunehmend auf cloud-basierte DataWarehouses als Alternative zu lokalen Systemen.
Data Lake versus Data Warehouse: 8 wichtige Unterschiede
Unternehmen setzen in der Regel ein Data Warehouse ein, wenn sie über umfangreiche operative Datenbestände verfügen, die für Analysen und Berichte zur Unterstützung des Tagesgeschäfts jederzeit verfügbar sein müssen. Data Warehouses fungieren dabei häufig als zentrale, vertrauenswürdige Datenquelle eines Unternehmens. Sie speichern historische Geschäftsdaten, die zuvor bereinigt, strukturiert und kategorisiert wurden – und stellen damit eine verlässliche Basis für Business Intelligence (BI), Reporting und strategische Entscheidungen dar.
Ein Data Lake hingegen ist deutlich offener konzipiert. Er speichert Daten aus einer größeren Vielfalt an Quellen, häufig sowohl interne als auch externe Datenströme – von klassischen Geschäftssystemen über IoT-Sensoren bis hin zu Social Media Feeds.
Im Kern ist eine Data-Lake-Plattform eine Sammlung verschiedener Rohdatenbestände, die noch nicht aufbereitet wurden und deshalb flexibel für unterschiedliche Analysezwecke genutzt werden können – etwa für Machine-Learning-Modelle, explorative Datenanalysen oder fortgeschrittene KI-Anwendungen.
Die folgende Tabelle zeigt die acht wichtigsten Unterschiede zwischen Data Lakes und Data Warehouses im Überblick.
| Data Lake | Data Warehouse | |
| Unterstützte Datentypen | Data Lakes können eine Kombination aus strukturierten, semi-strukturierten und unstrukturierten Daten verarbeiten, die in der Regel in ihrem nativen Format gespeichert werden. Dadurch stehen die vollständigen Rohdatensätze für Analysen zur Verfügung. | Data Warehouses speichern in der Regel strukturierte Daten aus Transaktionsverarbeitungssystemen und anderen Geschäftsanwendungen. In den meisten Fällen bereinigen und kuratieren Unternehmen die Daten, bevor sie diese in ein Data Warehouse laden. |
| Analysen | Unternehmen nutzen Data Lakes in erster Linie für Data-Science-Anwendungen, die maschinelles Lernen, prädiktive Modellierung und andere fortschrittliche Analysetechniken umfassen. Die Analyseziele sind oft explorativ und nicht immer vordefiniert. | Data Warehouses unterstützen weniger komplexe BI-, Ad-hoc-Analyse-, Berichts- und Datenvisualisierungsanwendungen, in der Regel mit einem vordefinierten Zweck zur Analyse von Geschäftsabläufen und zur Verfolgung von KPIs. |
| Anwender | Hauptnutzer von Data Lakes sind Datenwissenschaftler und Datenanalysten der unteren Ebene. Unterstützt werden sie häufig von Dateningenieuren beim Aufbau von Datenpipelines und bei der Vorbereitung der Daten für die Analyse nach Bedarf. | Business-Analysten, Führungskräfte und operative Mitarbeiter setzen Data Warehouses über Self-Service-BI-Tools ein. Oft führen auch BI-Analysten und Entwickler Abfragen in Data Warehouses für Geschäftsanwender durch. |
| Methoden zur Datenverarbeitung | Data Lakes unterstützen herkömmliche ETL-Prozesse (Extract, Transform, Load), aber Unternehmen verwenden zunehmend ELT-Prozesse (Extract, Load, Transform). Bei letzteren werden zuerst Rohdaten geladen und diese später für bestimmte Anforderungen transformiert. | Datenteams verwenden in der Regel ETL-Prozesse für die Datenintegration und -aufbereitung in Data Warehouses. Sie finalisieren die Datenstruktur, bevor sie Datensätze laden, um geplante BI- und Analyseanwendungen zu unterstützen. |
| Schema-Ansatz | Das Schema wird erst beim Lesen der Daten definiert. Datenteams können das Schema für Datensätze nach deren Speicherung in einem Data Lake mithilfe eines Schema-on-Read-Ansatzes festlegen. | Das Schema wird vor dem Laden der Daten festgelegt. Datenteams definieren Schemata in Data Warehouses vor dem Laden von Datensätzen gemäß Schema-on-Write-Verfahren. |
| Datenspeicherung | Daten werden in der Regel auf anderen Plattformen als relationalen Datenbanken gespeichert. Beispielsweise im Hadoop Distributed File System, in Cloud-Objektspeicherdiensten oder in NoSQL-Datenbanken. | Unternehmen speichern Daten in der Regel in relationalen Datenbanken unter Verwendung herkömmlicher Server- und Festplattenspeicher. Sie können Data Warehouses auch auf spaltenorientierten Datenbanken aufbauen. |
| Kosten | Die Hardwarekosten sind in der Regel geringer, da Data Lakes kostengünstigere Server und Speicher verwenden. Auch die Datenverwaltung kann preiswerter sein. Die Größe einiger Data Lakes kann jedoch die Kostenvorteile zunichte machen. | Im Allgemeinen sind Data Warehouses aufgrund der erforderlichen großen Server und Festplattenspeichersysteme teurer in der Bereitstellung als Data Lakes. Auch die Verwaltung eines Data Warehouse kann kostspieliger sein. |
| Geschäftsnutzen | Data Lakes ermöglichen es Data-Science-Teams, vielfältige strukturierte und unstrukturierte Datensätze zu analysieren und Analysemodelle zu erstellen, die Erkenntnisse für die strategische Planung und geschäftliche Entscheidungen liefern. | Unternehmen nutzen Data Warehouses als zentrales Repository für konsolidierte und kuratierte Datensätze, um die Geschäftsleistung zu analysieren und operative Entscheidungen zu unterstützen. |
Um sich den Unterschied zwischen einem Data Lake und einem Data Warehouse einzuprägen, hilft ein einfaches Bild: Ein Data Warehouse gleicht einem geordneten Lagerhaus, während ein Data Lake eher einem verzweigten See ähnelt.
Im Data Warehouse werden Daten sorgfältig ausgewählt, bereinigt und in klar definierten Strukturen abgelegt – so wie in einem Warenlager nur geprüfte und etikettierte Produkte in die Regale kommen. Die gespeicherten Informationen sind kuratiert, konsistent und direkt für Analysen nutzbar.
Ein Data Lake hingegen nimmt alles auf, was ihm zufließt – vergleichbar mit einem See, der von vielen Flüssen, Bächen und Quellen gespeist wird. Hier landen Daten in ihrer Rohform: unstrukturiert, halbstrukturiert oder strukturiert, aus unterschiedlichsten Quellen. Diese Vielfalt erlaubt maximale Flexibilität für Machine-Learning-Modelle, Data Science und explorative Analysen, erfordert aber auch mehr Aufwand bei der Aufbereitung und Pflege.
Auswahl der richtigen Plattform basierend auf den Unternehmenszielen
Ob sich ein Unternehmen für ein Data Lake oder ein Data Warehouse entscheidet, hängt maßgeblich davon ab, wie die Daten genutzt werden sollen.
Data Warehouses enthalten bereits bereinigte und strukturierte historische Daten, die für wiederkehrende Analysen aufbereitet sind. Sie eignen sich daher besonders für Anwender mit geringeren technischen Kenntnissen: Business-Analysten, Führungskräfte und Fachabteilungen können über Self-Service-BI-Tools direkt auf die Daten zugreifen.
Das Design von Data Warehouses erleichtert oft auch verschiedenen Teams und Abteilungen den Zugriff auf die darin gespeicherten Daten. Aus diesem Grund ist eine gut aufgebaute Data-Warehouse-Architektur der Schlüssel zum Aufbrechen von Datensilos in Unternehmenssystemen.
Ein Data Lake hingegen ist ideal für Organisationen, die kontinuierlich große Mengen an Daten aus unterschiedlichsten Quellen aufnehmen – etwa Logdaten, IoT-Ströme oder Sensordaten. Die Speicherung ist unkompliziert, da Rohdaten direkt übernommen werden können. Allerdings ist der Datenbestand oft komplexer zu durchsuchen und zu verarbeiten als die bereits kuratierten Daten im Warehouse.
Data Scientists nutzen Data Lakes daher bevorzugt für fortgeschrittene Analysen, Modelltraining oder Machine Learning. Die Flexibilität, die sie beim Erstellen verschiedener Analysemodelle aus denselben Datensätzen bieten, macht Data Lakes auch zu einer beliebten Wahl für Unternehmen mit vielfältigen Analyseanforderungen.
Viele Unternehmen setzen heute parallel auf beide Plattformen, um verschiedene Analyseanforderungen zu unterstützen. In einigen Fällen kann auch die Kombination eines Data Lakes und eines Data Warehouses in einer einheitlichen Umgebung die beste Option sein. Beispielsweise können Daten aus einem Data Warehouse in einen Data Lake eingespeist werden, um von Datenwissenschaftlern genauer analysiert zu werden.
Darüber hinaus sind neue Plattformen entstanden: Data Lakehouses sind Plattformen, die die Flexibilität und Skalierbarkeit eines Data Lakes mit den Datenmanagement- und Abfragefunktionen eines Data Warehouses kombinieren. Sie vereinen beide Welten und bieten damit eine einheitliche, performante Umgebung für Reporting, Analyse und KI-Anwendungen.







