
xyz+ - stock.adobe.com
So optimieren Sie Netzwerkleistung und -zuverlässigkeit
Die Netzwerkzuverlässigkeit ist wichtig für die Netzwerk-Performance. Unsere Best Practices helfen Administratoren dabei, stabile Netzwerke aufzubauen und zu pflegen.

Die Netzwerkzuverlässigkeit ist für das Networking von entscheidender Bedeutung. Zuverlässigkeit gewährleistet minimale Unterbrechungen, was für Unternehmen unerlässlich ist, um finanzielle Verluste und Produktivitätseinbußen zu vermeiden.
Dieser Artikel befasst sich mit Best Practices, um die Netzwerkzuverlässigkeit sicherzustellen und die Leistung zu verbessern. Dazu gehören Netzwerkprotokolle, Strategien zur Performance-Optimierung, Quality of Service (QoS), Microservices und Konfigurations-Tools. Netzwerkfachleute können mithilfe dieser Richtlinien Netzwerk-Downtime vermeiden und Leistungseinbußen minimieren.
Netzwerkprotokolle, die für Zuverlässigkeit sorgen
Netzwerkprotokolle sind eine kritische Komponente der Netzwerkkommunikation und für die Aufrechterhaltung der Netzwerkzuverlässigkeit unerlässlich. Netzwerkprotokolle legen Regeln fest, die angeben, wie Daten über ein Netzwerk übertragen werden. Diese Regeln ermöglichen es Geräten, innerhalb eines Netzwerks effizient zu kommunizieren und Informationen auszutauschen.
Zu den wichtigsten Netzwerkprotokollen, die die Zuverlässigkeit gewährleisten, gehören:
Das First Hop Redundancy Protocol
Redundanz bedeutet, dass ein zusätzlicher Mechanismus hinzugefügt wird, der im Falle eines Ausfalls als Backup fungiert. Es ist wichtig, zu bestimmen, ob es sich bei dem Point of Failure um einen Punkt mit geringem oder hohem Risiko im Netzwerk handelt.
FHRP bietet Redundanz, indem es den Traffic bei einem Ausfall automatisch auf ein Backup-Gerät umleitet. Es gibt anbieterspezifische und anbieterunabhängige Implementierungen, wie das Virtual Router Redundancy Protocol (VRRP).
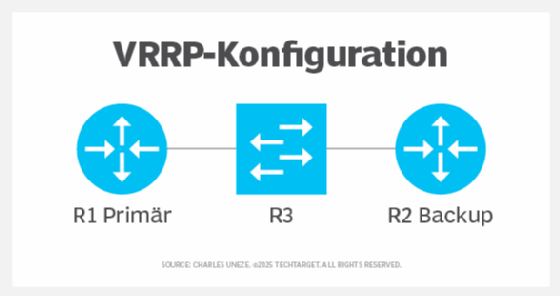
VRRP wird auf der Schnittstelle des primären und des Backup-Geräts konfiguriert. Das primäre und das Backup-Gerät teilen sich eine virtuelle IP-Adresse. Das primäre Gerät kümmert sich üblicherweise um den Traffic. Wenn jedoch das primäre Gerät ausfällt, weist VRRP die virtuelle IP-Adresse neu zu und leitet den Datenverkehr an das Backup-Gerät um. Wenn das primäre Gerät wieder funktionsfähig ist, übernimmt es wieder seine ursprüngliche Rolle.
Läuft VRRP auf einem Layer 3 Switch in einem Data-Center-Netzwerk, sollten Sie eine STP-Konfiguration (Spanning Tree Protocol) in Betracht ziehen. Der primäre VRRP-Switch sollte als STP-Root-Switch dienen, um die Netzwerkstabilität zu gewährleisten. Darüber hinaus überwacht das Objekt-Tracking den Status von Nicht-VRRP-Schnittstellen. Das Backup-Gerät übernimmt bei einem Ausfall die Funktion, was die Zuverlässigkeit weiter erhöht.
Open Shortest Path First
OSPF kann Fehler auf einer Router-Verbindung schnell erkennen und mit dem Shortest-Path-First-Algorithmus optimale Routen neu berechnen. Anschließend teilt es diese Routen über ein LSA-Paket (Link State Advertisement) allen benachbarten OSPF-Routern mit.
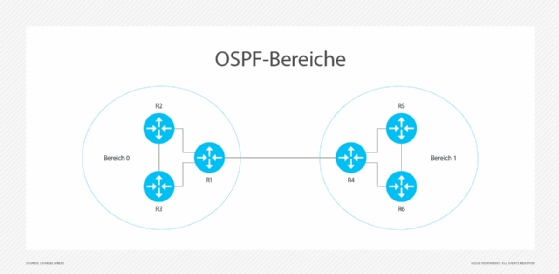
Allerdings kann es bei OSPF Probleme mit der Skalierbarkeit geben. Router belegen Bandbreite, wenn sie LSA-Pakete versenden und Routen neu berechnen, was die CPU des Routers belastet. In einem großen Unternehmensnetzwerk mit Hunderten von Routern kann eine einzige Topologieänderung – zum Beispiel ein Verbindungsausfall – eine Flut von LSA-Paketen auslösen und dazu führen, dass jeder Router die Routen neu berechnet. Damit es nicht zu diesem Problem kommt, fassen Sie Router in OSPF-Bereichen zusammen, um unnötige Aktualisierungen zu reduzieren.
Das Border Gateway Protocol
BGP ist das Rückgrat des Internet-Routings. Netzwerkfachleute können Router gruppieren und sie einer gemeinsamen administrativen Kontrolle und Routing-Richtlinie unterstellen, so dass sie ein autonomes System (AS) bilden. Jedes AS, das in der Regel von einem ISP verwaltet wird, besitzt eine eindeutige Nummer. Diese eindeutigen Nummern beziehungsweise ASNs (Autonomous System Number) ermöglichen es mehreren autonomen Systemen, sich miteinander zu verbinden und die Routing-Kontrolle zu übernehmen.
Eine Best Practice bei der Konfiguration von BGP besteht darin, eine BGP-Nachbarschaft innerhalb eines AS mit einer Loopback-Schnittstelle anstelle einer physischen Schnittstelle zu bilden.
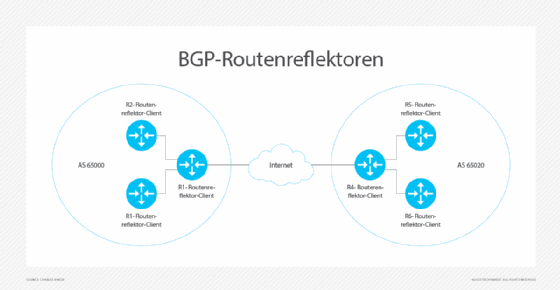
BGP hat jedoch ein Skalierbarkeitsproblem, denn alle Router müssen untereinander BGP-Nachbarschaften bilden. Folgende Werkzeuge können bei diesem Problem helfen:
- Routenreflektor: Ein designierter Router bildet Nachbarschaften und gibt Routen an andere Router weiter. Anstatt beispielsweise drei Router einzusetzen, die drei Verbindungen benötigen, reduziert ein Routenreflektor dies auf zwei Verbindungen.
- BGP-Konföderationen: Netzwerkexperten können ein großes AS in kleinere Subsysteme unterteilen, die als BGP Confederations oder BGP-Konföderationen bezeichnet werden, um das Routing übersichtlicher zu gestalten. Ein ISP kann dies in größerem Maßstab tun, indem er ein kontinentweites Netzwerk in regionale autonome Subsysteme unterteilt, um das Routing zu vereinfachen.
Strategien zur Optimierung der Netzwerk-Performance
Strategien zur Optimierung der Netzwerkleistung können nicht nur die Performance verbessern, sondern auch die Zuverlässigkeit gewährleisten. Um die Netzwerkleistung zu steigern, können Sie beispielsweise folgende Strategien nutzen:
- Bidirectional Forwarding Detection (BFD)
- Route Summarization
- Load Sharing
Bidirectional Forwarding Detection
OSPF legt standardmäßig ein Dead-Time-Intervall von 40 Sekunden fest. Das bedeutet, ein Router muss so lange warten, bevor er einen Nachbarn als offline deklarieren kann. Netzwerkfachleute können dieses Intervall auf eine Sekunde reduzieren, um die Fehlererkennung zu verbessern. Dies erhöht aber die CPU-Auslastung erheblich. Die Control Plane muss häufige HELLO-Pakete verarbeiten, die Nachbarschaftstabelle aktualisieren und die Routen ständig neu berechnen.
BFD arbeitet jedoch mit Routing-Protokollen zusammen und erreicht eine Fehlererkennung im Bereich von unter einer Sekunde (bis zu 50 Millisekunden), ohne die CPU zu überlasten. BFD läuft auf Data-Plane-Ebene und lagert die Fehlererkennung auf dedizierte Hardware aus, so dass die Hardware schnell und ohne übermäßigen Computing-Aufwand reagieren kann.
Route Summarization
Route Summarization konsolidiert verschiedene Schnittstellenadressen auf einem Gerät zu einem einzigen Präfix. Anschließend wird diese Zusammenfassung einem Gerät in einem anderen Teil des Netzwerks bekannt gegeben, etwa in einem OSPF-Bereich, einem BGP-AS oder einer Rechenzentrumsebene.
Route Summarization verbessert die Performance, da sie die Größe der Routing-Tabelle reduziert. Wenn ein Geräteausfall zu einer Neuberechnung der Route führt, minimiert sie die CPU-Auslastung des Routers. Durch die Zusammenfassung wird die Anzahl der einzelnen Routenaktualisierungen verringert, die der Router verarbeiten muss.
Route Summarization sorgt außerdem für Zuverlässigkeit und verbessert die Leistung, indem sie mehrere Routen zusammenfasst. Allerdings kann sie Routing-Schleifen verursachen. Um dies zu verhindern, empfiehlt es sich, das AS-Pfadattribut zu erhalten. Wenn beispielsweise AS 65001 eine Route zusammenfasst und AS 65002 sie zurückmeldet, kann AS 65001 sein eigenes AS im Attribut AS_PATH erkennen und ablehnen.
Load Sharing
Load Sharing stellt sicher, dass der Traffic mehrere Ausgangspunkte gleichzeitig nutzen kann. Dies unterscheidet sich von VRRP, das ein Gerät am Ausgangspunkt verwendet, bis es ausfällt.
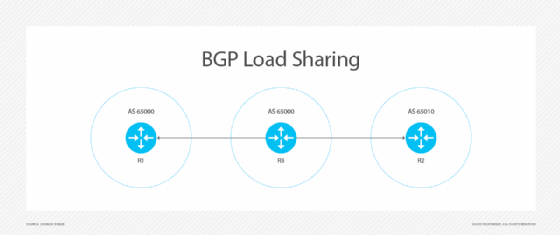
Load Sharing ist bei BGP nur möglich, wenn BGP Multipath aktiviert ist. Diese Funktion fügt mehrere Equal-Cost-BGP-Routen in die Routing-Tabelle ein. OSPF arbeitet ähnlich, wenn die Kosten zu mehreren Zielschnittstellen gleich sind.
Quality of Service
QoS gewährleistet die Netzwerkzuverlässigkeit und verbessert die Performance, indem sie Überlastungen verhindert und kritischen Traffic priorisiert. QoS nutzt unter anderem folgende Verfahren, damit es nicht zu einer Überlastung kommt:
- Queue Management
- Traffic Shaping
- Bandwidth Policing (Bandbreitenüberwachung)
Queue Management
Queue Management optimiert den Datenfluss bei Überlastung, indem es einen Teil des Traffics puffert und den Rest durchlässt. Es gibt viele Queuing-Typen, zum Beispiel Low Latency Queuing, das Echtzeit-Traffic (wie VoIP) gegenüber anderem Datenverkehr priorisiert.
Traffic Shaping
Traffic Shaping steuert den Datenverkehr, indem es zu viele eintreffende Datenpakete vorübergehend puffert und sie dann mit kontrollierter Geschwindigkeit weiterleitet. Auf diese Weise lassen sich plötzliche Traffic-Spitzen verhindern, die Router überlasten könnten.
Um zu überprüfen, ob eine QoS-Richtlinie korrekt funktioniert, nutzen Sie die I/O-Diagramme von Wireshark. Damit können Sie Traffic-Muster visualisieren und Anomalien, wie Paketverluste und Latenzspitzen, erkennen.
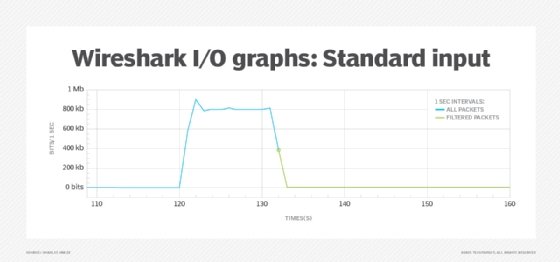
Abbildung 5 simuliert das Shaping in einem virtuellen Labor. Legen Sie auf einem Router die Durchsatzgrenze auf 800 KBit/s fest. Dies ist ein niedriger Durchsatz. In einer realen Umgebung ist mit einem höheren Wert zu rechnen. Führen Sie als Nächstes einen iPerf-Durchsatztest zwischen zwei Endgeräten mit einer Bandbreite von über 800 KBit/s durch. Verwenden Sie zum Schluss die Paketfilterung von Wireshark für iPerf-Pakete.
Nach der anfänglichen Traffic-Spitze nach knapp 120 Sekunden stabilisiert sich der Durchsatz bei rund 800 KBit/s. Dies deutet darauf hin, dass die QoS-Richtlinie den Traffic-Fluss aktiv steuert.
Bandwidth Policing
Bandwidth Policing erzwingt Bandbreitenbeschränkungen und verwirft oder markiert Pakete neu, die dieses Limit überschreiten. Bandwidth Policing unterstützt keine Pufferung.
Beispielsweise könnte ein ISP zusätzliche Gebühren verlangen, wenn bei einem Internetanschluss die gebuchte Bandbreite von 100 MBit/s überschritten wird. Um zusätzliche Kosten zu vermeiden, sollte das Policing so konfiguriert werden, dass es die Obergrenze von 100 MBit/s strikt einhält.
Microservices
Mikroservices sind für die Kommunikation auf schnelle und stabile Netzwerke angewiesen. Zu den häufigsten Problemen, die zu einem unzuverlässigen Netzwerk mit geringer Performance führen, gehören nicht erkannte Ausfälle, unkontrollierte IP-Adresszuweisung und hohe Latenz. Mit den folgenden Maßnahmen lassen sich Zuverlässigkeit und Leistung verbessern:
- Überwachen der Workloads.
- Kontrolle der IP-Adressvergabe durch Kontingente.
- Optimieren der Netzwerkkarten (Network Interface Card, NIC) bei Cloud-Bereitstellungen.
Überwachen der Workloads
Metriken, Protokolle und Traces können IT-Teams beim Troubleshooting ein vollständiges Bild des gesamten Netzwerks vermitteln. Metriken bieten Einblicke in den Zustand und die Leistung des Netzwerks sowie seiner Anwendungen. Protokolle zeichnen diese Ereignisse auf, um einen detaillierten Überblick zu liefern, wann Ereignisse auftreten, vergangene Aktivitäten zu analysieren sowie das zukünftige Netzwerkverhalten zu identifizieren und vorherzusagen. Traces verfolgen den Datenfluss im Netzwerk, um sicherzustellen, dass Daten zwischen Geräten ordnungsgemäß übertragen werden können.
Kontrolle der IP-Adressvergabe
In großen Kubernetes-Bereitstellungen führt eine unkontrollierte IP-Adressvergabe zu einem Adressmangel. Ohne verfügbare IP-Adressen können IT-Teams keine neuen Pods planen, die Netzwerkkommunikation bricht zusammen, und kritische Services fallen aus. Dies beeinträchtigt letztlich die Zuverlässigkeit und Leistung des gesamten Clusters.
Um Abhilfe zu schaffen, nutzen Sie IPv6, sofern der Cluster dies unterstützt. Ist das nicht der Fall, verwenden Sie einen IPv4/8-Präfix, zum Beispiel 10.0.0.0/8. Wenn das Netzwerk ein Container Network Interface (CNI) nutzt, etwa Calico oder Cilium, kontrollieren Sie die IP-Adresszuweisung, indem Sie bestimmte IP-Adressbereiche pro Knoten in einem Cluster festlegen.
Optimieren der Cloud-VM-NICs
In einem Kubernetes-Cluster mit mehreren Knoten tauschen die auf den Knoten (Cloud-VM) laufenden Microservices häufig Daten aus. Ohne High-Performance Networking durchläuft jedes Paket den Hypervisor, was die Latenz erhöht.
Wenn Netzwerkadministratoren über eine VM verfügen, die eine erweiterte Networking-Funktion wie Single-Root I/O-Virtualisierung unterstützt, können sie diese nutzen, um die Performance zu verbessern. Dadurch umgehen Pakete den Hypervisor und fließen direkt zwischen der NIC und der VM.
Konfigurations-Tools und Troubleshooting-Techniken
Bestimmte Tools erweisen sich als äußerst praktisch, wenn Admins Probleme mit der Netzwerkzuverlässigkeit und -leistung beheben müssen. Zu den nützlichsten Tools für das Netzwerk-Troubleshooting gehören:
- Ipconfig und ifconfig: Diese Tools finden sich in der Regel auf Endgeräten wie Laptops und PCs mit einer Befehlszeile. Nachdem sie den Internetzugang eingerichtet und eine Endgeräteschnittstelle sowie ein Standard-Gateway konfiguriert haben, können Netzwerkadministratoren die Kommandos ipconfig (Windows) und ifconfig (Linux) verwenden, um die Konfigurationen zu überprüfen.
- Ping: Mit diesem Kommandozeilenwerkzeug lässt sich testen, ob Pakete ihr Zielgerät im Netzwerk erreichen.
- Wireshark: Ein Tool zur Paketaufzeichnung, mit dem man Pakete während ihrer Übertragung über das Netzwerk erfassen kann.





