
Sergey Nivens - stock.adobe.com
Kosten und Komplexität einer AWS-DR-Strategie reduzieren
Disaster Recovery in AWS kann schnell teuer und kompliziert werden. Bevor Sie sich entscheiden, sollten Sie daher genau überlegen, was Sie wirklich brauchen.

Cloud-Dienste haben zwar eine höhere Zuverlässigkeit als die meisten On-Premises-Systeme, aber ausfallen können sie trotzdem noch – was eine Notfallwiederherstellung, die Cloud-Anbieter häufig unter dem Namen Disaster Recovery vertreiben, unabdingbar macht.
Beim Erstellen eines Notfallwiederherstellungsplans (Disaster Recovery, DR) müssen AWS-Benutzer sich klar sein, wie viel Zeit und Geld sie zu investieren bereit sind, um Disaster Recovery umzusetzen. Sie sollten die AWS Availability Zones (AZs) und Regionen verstehen und wissen, wie diese Konzepte in die DR einfließen.
DR-Stufen in AWS
Es gibt vier Strategien für Disaster Recovery in AWS. Sie sind im Folgenden aufgeführt, beginnend mit der kostengünstigsten und am wenigsten aufwendigen Option:
- Sicherung und Wiederherstellung. Administratoren wählen diese Option in der Regel für DR-Anforderungen wie die Minimierung von Datenverlusten. Der Cloud-Dienst stellt die Daten Stunde oder Tage nach dem DR-Ereignis wieder her, da es sie aus dem kalten Speicher abruft.
- Pilot Light. Diese Option repliziert Daten von einer AWS-Region in eine andere. Es stellt zusätzlich eine Kopie der zugrunde liegenden Anwendungsinfrastruktur bereit, schaltet Ressourcen wie Server jedoch nur zu Testzwecken oder zur Ausfallsicherung ein. Es kommt zu einer gewissen Verzögerung, Workloads sind aber relativ schnell wieder online, in Minuten bis Stunden, je nachdem, wie viele Daten der Dienst replizieren muss.
- Warmes Standby. Diese Funktion erhält eine verkleinerte Version Ihrer Produktionsumgebung in einer anderen AWS-Region aufrecht. Die Ausfallzeit ist minimal, in der Regel Minuten, da die Workloads in der anderen Region funktionsfähig bleiben.
- Multi-Site Active-Active. Bei dieser Option führen Benutzer Workloads in mehreren AWS-Regionen gleichzeitig aus und sorgen für eine geringe oder gar keine Serviceunterbrechung. Sie ist zwar die komplexeste und teuerste Option, reduziert aber die Wiederherstellungszeiten auf nahezu Null.
Wenn Sie sich für eine AWS-DR-Strategie entscheiden, sollten Sie abwägen, was für Verluste für Sie verschmerzbar wären und wie schnell Sie die Daten wiederherstellen müssen, sowie das Budget, das Ihnen für die Disaster Recovery sinnvoll erscheint.
Wie Regionen und Availability Zones die DR beeinflussen
Regionen und Availability Zones sind ein wichtiger Bestandteil von DR-Projekten in AWS. Eine Region ist ein geografischer Standort, an dem sich ein AWS-Rechenzentrum befindet. Eine AZ ist eine Gruppe von logischen Rechenzentren innerhalb einer bestimmten Region.
Viele Leute denken bei DR an Hardware-Redundanz und die Notwendigkeit, Workloads auf mehrere AZs zu verteilen. Das ist größtenteils richtig. Eine AZ besteht in der Regel aus mehreren Rechenzentren, die bereits über eine eingebaute Redundanz verfügen, zum Beispiel für Stromversorgung und Netzwerke. Das bedeutet nicht, dass die Datenzentren in einer bestimmten AZ gespiegelte Klone voneinander sind. Sie können Dienste und Daten zwischen ihnen verschieben oder doppelt laufen lassen, aber eher als eine Art Failover und nicht als vollständige Synchronisierung. Dies führt zu einer teilweisen – nicht vollständigen – Redundanz.
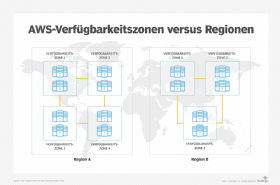
Jede AWS-Region hat normalerweise zwei oder mehr AZs. Wenn Sie Ihre Anwendung über zwei AZs überbrücken, ergeben sich geringe Latenzzeiten und somit minimale Ausfallzeiten. Jede AZ verfügt normalerweise über mehrere redundante Rechenzentren zur Ausfallsicherung, so dass die Zone geschützt ist. Eine Multi-AZ-Strategie dient häufig dem Schutz vor lokalen Katastrophen wie Erdbeben oder Überschwemmungen.
Wenn Sie sich Sorgen über ein Ereignis machen, das alle AZs in einer Region betreffen könnte, wie zum Beispiel ein massiver Stromausfall, gehen Sie einen Schritt weiter und verknüpfen zwei AWS-Regionen. Eine Strategie mit mehreren Regionen führt jedoch zu mehr Komplexität und höheren Kosten.
Nutzen Sie die Automatisierung zur Kostensenkung
Eine gründliche DR-Strategie schließt die meisten Redundanzlücken – allerdings zu einem hohen Preis. Ein Duplikat Ihrer Umgebung an einem anderen Standort kann Ihre AWS-Rechnung verdoppeln. Das sind hohe Kosten für etwas, das Sie nur selten nutzen.
Aus diesem Grund ist Infrastructure as Code (IaC) ideal für die DR. Wenn Sie einen kurzen Ausfall verschmerzen können, warum dann nicht die Infrastruktur für Ihre Daten erst dann aufbauen, wenn Sie sie benötigen? Durch Automatisierung stellen Sie die Infrastruktur bereit, wenn Sie sie brauchen und nicht nur, falls Sie sie brauchen. Dies ist ein wesentlich kostengünstigerer Ansatz für DR in AWS.
Die Bedeutung der Datenreplikation
Automatisierung und AZs sind wichtige Elemente für die AWS-Notfallplanung. Diese Taktiken funktionieren nur, wenn Ihre Daten bereit sind, das heißt, wenn Sie die erforderliche Datenreplikation durchgeführt haben.
Für ein vernünftiges Maß an DR-Reaktion müssen die Daten zeitnah zugänglich sein. Sie können sie nicht von AWS Simple Storage Service Glacier oder anderen Cold-Storage-Services abrufen und erwarten, dass Ihre Workloads schnell wieder online sind.
Sie können auch kleinere Standby-Umgebungen einsetzen, die immer in einem begrenzten Aktiv/Aktiv-Szenario verbleiben. AWS Autoscaling bringt diese Standby-Umgebungen ohne menschliches Eingreifen und mit begrenzter Ausfallzeit in eine vollständige Produktionsumgebung. Während der Wiederherstellung kann es zu einer Verzögerung bei den Services kommen, doch die Kosteneinsparungen rechtfertigen das häufig.
Die Automatisierung über IaC und AWS Autoscaling erfordert Zeit und Aufwand für das Einrichten und Testen.
Wenn es erforderlich ist, kommt auch eine Multi-AZ-Strategie in Frage. Ein Notfallplan muss nicht auf einem einzigen Ansatz beruhen. Die Anwendung einer DR-Strategie auf alle Workloads wäre wahrscheinlich zu kostspielig und einschränkend. Einige Workloads benötigen ein höheres Maß an Schutz vor Ausfallzeiten, andere weniger.
Treffen Sie als Unternehmen eine Entscheidung, die Ihre Prioritäten und Kostenpräferenzen widerspiegelt – und passen Sie diese im Laufe der Zeit an.
Erfahren Sie mehr über Cloud Computing
-
![]()
AWS Summit Hamburg 2026: Sovereign Cloud nimmt Fahrt auf
Von: Florian Fröhlich
-
![]()
Amazon EBS Storage mit CSI-Treiber in Kubernetes integrieren
Von: Ulrike Rieß-Marchive
-
![]()
10 wesentliche Merkmale des Cloud Computings
Von: Kathleen Casey
-
![]()
Was kosten die unterschiedlichen AWS-Storage-Angebote?
Von: Ulrike Rieß-Marchive



