Datenbankreplikation

Unter Datenbankreplikation versteht man das häufige elektronische Kopieren von Daten aus einer Datenbank auf einem Computer oder Server in eine Datenbank auf einem anderen, so dass alle Benutzer den gleichen Informationsstand haben. Das Ergebnis ist eine verteilte Datenbank, in der die Benutzer schnell auf die für ihre Aufgaben relevanten Daten zugreifen können, ohne die Arbeit der anderen zu beeinträchtigen. Zahlreiche Elemente tragen zum Gesamtprozess der Erstellung und Verwaltung der Datenbankreplikation bei.
Wie die Datenbankreplikation funktioniert
Die Datenbankreplikation kann entweder ein einmaliges Ereignis oder ein fortlaufender Prozess sein. Sie bezieht alle Datenquellen in der verteilten Infrastruktur eines Unternehmens ein. Das verteilte Managementsystem des Unternehmens wird verwendet, um die Daten zu replizieren und ordnungsgemäß auf alle Quellen zu verteilen.
Insgesamt sorgen verteilte Datenbankverwaltungssysteme (DDBMS) dafür, dass Änderungen, Hinzufügungen und Löschungen von Daten an einem bestimmten Ort automatisch mit den an allen anderen Orten gespeicherten Daten abgeglichen werden. DDBMS ist im Wesentlichen die Bezeichnung für die Infrastruktur, die die Datenbankreplikation ermöglicht oder durchführt - das System, das die verteilte Datenbank verwaltet, die das Produkt der Datenbankreplikation ist.
Der klassische Fall der Datenbankreplikation umfasst eine oder mehrere Anwendungen, die einen primären Speicherort mit einem sekundären Speicherort verbinden, der häufig außerhalb des Standorts liegt. Bei diesen primären und sekundären Speicherorten handelt es sich heute meist um einzelne Quelldatenbanken - wie Oracle, MySQL, Microsoft SQL und MongoDB - sowie um Data Warehouses, die Daten aus diesen Quellen zusammenführen und Speicher- und Analysedienste für größere Datenmengen anbieten. Data Warehouses werden häufig in der Cloud gehostet.
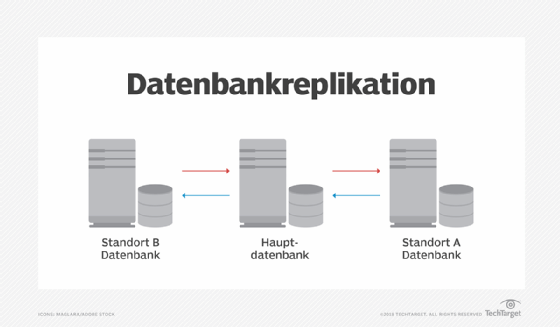
Techniken der Datenbankreplikation
Es gibt mehrere Möglichkeiten, eine Datenbank zu replizieren. Die verschiedenen Techniken bieten unterschiedliche Vorteile, da sie sich in ihrer Gründlichkeit, Einfachheit und Geschwindigkeit unterscheiden. Welche Technik am besten geeignet ist, hängt davon ab, wie Unternehmen Daten speichern und welchem Zweck die replizierten Informationen dienen sollen.
Was den Zeitpunkt der Datenübertragung betrifft, so gibt es zwei Arten der Datenreplikation:
- Bei der asynchronen Replikation werden die Daten vom Client an den Modellserver - den Server, von dem die Replikate Daten beziehen - gesendet. Anschließend sendet der Modellserver ein Ping an den Client mit der Bestätigung, dass die Daten empfangen wurden. Von dort aus werden die Daten in einem nicht spezifizierten oder überwachten Tempo in die Replikate kopiert.
- Bei der synchronen Replikation werden die Daten vom Client-Server auf den Modellserver kopiert und dann auf alle Replikationsserver repliziert, bevor der Client darüber informiert wird, dass die Daten repliziert wurden. Die Verifizierung dauert länger als bei der asynchronen Methode, hat aber den Vorteil, dass man weiß, dass alle Daten kopiert wurden, bevor man fortfährt.
Die asynchrone Datenbankreplikation bietet Flexibilität und Benutzerfreundlichkeit, da die Replikationen im Hintergrund ablaufen. Es besteht jedoch ein größeres Risiko, dass Daten ohne Wissen des Kunden verloren gehen, da die Bestätigung vor dem eigentlichen Replikationsprozess erfolgt. Die synchrone Replikation ist starrer und zeitaufwändiger, bietet aber eine höhere Wahrscheinlichkeit, dass die Daten erfolgreich repliziert werden. Der Kunde wird gewarnt, wenn dies nicht der Fall ist, da die Bestätigung erst nach Abschluss des gesamten Prozesses erfolgt.
Es gibt auch mehrere Arten der Datenbankreplikation, die auf der Art der Serverarchitektur basieren. Der Begriff „Leader“ bedeutet bei diesen Typen dasselbe wie das „Modell“ in den vorherigen Beispielen für asynchrone und synchrone Replikation:
- Bei der Single-Leader-Architektur empfängt ein Server die Schreibzugriffe der Clients, und die Replikate beziehen die Daten von diesem Server. Dies ist die gängigste und klassischste Methode. Es handelt sich um eine synchronisierte Methode, die jedoch etwas unflexibel ist.
- Die Multi-Leader-Architektur besteht aus mehreren Servern, die Schreibzugriffe empfangen und als Modell für Replikate dienen können. Sie ist vorteilhaft, wenn die Replikate weit verstreut sind und der Leader sich in der Nähe aller Replikate befinden muss, um Latenzzeiten zu vermeiden.
- Bei der No-Leader-Architektur kann jeder Server Schreibzugriffe empfangen und als Modell für Replikate dienen. Diese Architektur wurde von Amazons DynamoDB eingeführt. Sie bietet zwar ein Höchstmaß an Flexibilität, stellt jedoch eine Herausforderung für die Synchronisierung dar.
Vor- und Nachteile
Die Datenbankreplikation wird häufig von einem Datenbank- oder Replikationsadministrator beaufsichtigt. Ein ordnungsgemäß implementiertes Replikationssystem kann mehrere Vorteile bieten, darunter die folgenden:
- Da die replizierten Daten auf mehrere Server verteilt werden können, ist es unwahrscheinlich, dass ein einzelner Server mit den Datenabfragen der Benutzer überlastet wird.
- Höhere Effizienz. Server, die weniger mit Abfragen belastet sind, können weniger Benutzern eine bessere Leistung bieten.
- Hohe Verfügbarkeit. Der Einsatz mehrerer Server mit denselben Daten gewährleistet eine hohe Verfügbarkeit, das heißt wenn ein Server ausfällt, kann das gesamte System immer noch eine akzeptable Leistung erbringen.
Viele Nachteile der Datenbankreplikation ergeben sich aus schlechten allgemeinen Datenverwaltungspraktiken. Zu diesen Nachteilen gehören die folgenden:
- Datenverluste können während der Replikation auftreten, wenn fehlerhafte Daten oder Iterationen oder Aktualisierungen einer Datenbank kopiert werden und folglich wichtige Daten gelöscht oder nicht berücksichtigt werden. Dies kann passieren, wenn der Primärschlüssel, der zur Überprüfung der Datenqualität in der Replik verwendet wird, nicht richtig funktioniert oder falsch ist. Es kann auch vorkommen, wenn Datenbankobjekte in der Quelldatenbank falsch konfiguriert sind.
- Ebenso können fehlerhafte oder veraltete Replikate dazu führen, dass verschiedene Quellen nicht mehr miteinander synchronisiert sind. Dies kann zu vergeudeten Data-Warehouse-Kosten führen, die unnötig für die Analyse und Speicherung irrelevanter Daten ausgegeben werden.
- Mehrere Server. Der Betrieb mehrerer Server ist mit Wartungs- und Energiekosten verbunden. Um diese Kosten muss sich entweder das Unternehmen selbst oder ein Dritter kümmern. Wenn ein Dritter diese Kosten übernimmt, läuft das Unternehmen Gefahr, sich an einen bestimmten Anbieter zu binden oder Serviceprobleme zu bekommen, die sich der Kontrolle des Unternehmens entziehen.
Entwicklung der Datenbankreplikation
Frühe Instanzen der Datenbankreplikation wurden in der Regel als Master-Slave-Konfigurationen beschrieben, aber vergleichbare Beschreibungen enthalten heute eher Begriffe wie Master-Replica, Leader-Follower, Primary-Secondary und Server-Client.
Replikationstechniken, die sich auf relationale Datenbankmanagementsysteme konzentrierten, haben sich mit dem Aufkommen der virtuellen Maschine und des verteilten Cloud-Computing auf nichtrelationale Datenbanktypen ausgeweitet. Auch hier variieren die Replikationsmethoden zwischen nichtrelationalen Datenbanken wie Redis oder MongoDB.
Während die Replikation von Remote-Office-Datenbanken viele Jahre lang das klassische Beispiel für die Replikation war, haben sich auch ausfallsichere und fehlertolerante Datenbank-Backup-Schemata als Treiber für die Replikationsaktivität herauskristallisiert - ebenso wie horizontal skalierende verteilte Datenbankkonfigurationen, sowohl vor Ort als auch auf Cloud-Computing-Plattformen. Die Details der Replikation variieren zwischen relationalen Systemen wie IBM Db2, Microsoft SQL Server, Sybase, MySQL und PostgreSQL.
In allen Fällen ist die Gestaltung der Datenreplikation ein Balanceakt zwischen Systemleistung und Datenkonsistenz. Die Datenbankreplikation kann auf mindestens drei verschiedene Arten durchgeführt werden. Bei der Snapshot-Replikation werden die Daten eines Servers einfach auf einen anderen Server oder in eine andere Datenbank auf demselben Server kopiert. Bei der Merging-Replikation werden die Daten aus zwei oder mehr Datenbanken in einer einzigen Datenbank kombiniert. Und bei der transaktionalen Replikation erhalten die Benutzersysteme zunächst vollständige Kopien der Datenbank und dann regelmäßige Aktualisierungen, wenn sich Daten ändern.
Datenbankreplikation vs. Spiegelung
Während die Datenspiegelung manchmal als Alternative zur Datenreplikation dargestellt wird, handelt es sich dabei eigentlich um eine Form der Datenreplikation. Bei der Spiegelung von relationalen Datenbanken werden vollständige Backups der Datenbanken für den Fall aufbewahrt, dass die primäre Datenbank ausfällt. Die Spiegelungen dienen in der Tat als Hot-Standby-Datenbanken. Die Datenspiegelung hat in der Microsoft SQL-Server-Gemeinschaft große Verbreitung gefunden.
Bei der Datenbankreplikation liegt der Schwerpunkt in der Regel auf der Skalierung der Datenbank für Abfragen, das heißt für Datenanfragen. Die Datenbankspiegelung, bei der Protokollauszüge die Grundlage für inkrementelle Datenbankaktualisierungen vom Hauptserver bilden, wird in der Regel implementiert, um Hot-Standby- oder Disaster-Recovery-Funktionen bereitzustellen. Einfach ausgedrückt, konzentriert sich die Spiegelung auf die Sicherung der vorhandenen Daten und die Replikation auf die Verbesserung der Betriebseffizienz als Ganzes, wozu auch die Aufrechterhaltung sicherer Datensicherungen durch Spiegelung gehört.
Tools für die Datenbankreplikation
Unternehmen können entweder das von ihrem Datenbanksoftwareanbieter angebotene Datenbankreplikations-Tool verwenden oder in Replikations-Tools von Drittanbietern investieren, um Datenbankreplikationsprozesse auszuführen und zu verwalten. Die letztere Option bietet Flexibilität: Tools von Drittanbietern sind in der Regel herstellerunabhängig und können verwendet werden, um Datenrepliken für mehrere Arten von Datenbanken in einem Unternehmen zu erstellen.
Erfahren Sie mehr über Datenbanken
-
![]()
Longhorn: Blockspeicher im Cluster ohne externes SAN
Von: Thomas Joos
-
![]()
Leistung optimieren: Vier Tipps für virtualisierten Speicher
Von: Ulrike Rieß-Marchive
-
![]()
Open-Source-Datenbanken im Vergleich: MySQL versus PostgreSQL
Von: Walker Aldridge
-
![]()
So verwalten Sie das Disaster Recovery für SQL Server
Von: Robert Sheldon



