
Gorodenkoff - stock.adobe.com
Fehlerbehebung mit kdump bei Linux Kernel Panic
Kernel Panic ist ein Absturz eines Linux-Systems aufgrund eines Fehlers auf Kernel-Ebene. Mit einem NFS-Server und kdump können Sie Absturzberichte lesen und die Ursache finden.

Eine sogenannte Kernel Panic ist ein kritisches Systemereignis, das zu einem Absturz führt. Der Kernel ist der Kern eines Betriebssystems; zum Beispiel ist bei Linux-Distributionen Linux eigentlich der Kernel und Entwickler können darauf verschiedenen Distributionen aufbauen.
Ist ein Fehler auf Kernel-Niveau schwerwiegend genug, löst das eine sogenannte Kernel Panic aus. Kernel Panic ist vergleichbar mit dem gefürchteten Blue Screen of Death (BSOD) in Windows. Anstelle eines blauen Bildschirms sehen Sie bei Linux jedoch eine Log-Ausgabe auf einem schwarzen Hintergrund.
Eine Kernel Panic kann durch kaputten Arbeitsspeicher, Treiberfehler, Malware oder Softwarefehler ausgelöst werden. Wollen Sie der Ursache einer Kernel Panic auf den Grund gehen, können Sie den Service kdump einsetzen. Er sammelt Absturzberichte anhand derer Sie Ursachenforschung betreiben und das Problem im System finden können.
In dieser Anleitung verwenden wir für einen Test zwei virtuelle Maschinen (VMs) mit CentOS 8 als Linux-Distribution, sowohl für den NFS-Server (Network File System) als auch den Client.
Konfigurieren Sie den Client so, dass er die Absturzberichte für den NFS-Server freigibt, können Sie die Daten zentral sammeln und analysieren. So können Sie vermeiden, das System auszuführen, auf dem die Kernel Panic aufgetreten ist.
Nachfolgend finden Sie die IP-Adressen von NFS-Server und Client. Je nach Netzwerkkonfiguration unterscheiden sie sich vielleicht von Ihren Adressen. Für die Fehlersuche sollten diese in Erfahrung bringen:
| NFS-Server |
192.168.99.1 |
| Client |
192.168.99.71 |
Bei Veröffentlichung dieses Beitrags setzte CentOS 8 auf Kernel-Version 4.18.0-147.5.1.el8_1.x86_64. Wollen Sie die Kernel-Version Ihres Linux-Systems herausfinden, führen Sie den Befehl uname -r aus.
NFS installieren
Nachdem Sie Ihre virtuellen Maschinen eingerichtet haben und die IP-Adressen für NFS-Server und Client wissen, installieren Sie ein paar zusätzliche Komponenten:
-
Führen Sie den Befehl yum install -y nfs-utils aus. Damit installieren Sie das NFS-Paket und können sich mit einem NFS-Server verbinden.
-
Erstellen Sie das Verzeichnis für das NFS: mkdir /nfs-share
-
Editieren Sie die Datei /etc/exports und gestatten Sie dem Client, sich mit dem NFS Share zu verbinden. Die nachfolgende IP-Adresse gehört zum Client:
/nfs-share 192.168.99.71(rw,sync,no_root_squash) -
Erstellen Sie auf dem Client ein Verzeichnis, in dem Sie die Absturzberichte ablegen möchten. Der Standard für kdump ist /var/crash. Sie können mit nachfolgendem Befehl aber auch im root-Verzeichnis ein Verzeichnis crash-dump erstellen:
mkdir /crash-dump -
Binden Sie die neue NFS-Freigabe in das Dateiverzeichnis des Clients ein. Die nachfolgende IP-Adresse gehört zum NFS-Server.
mount /-t nfs 192.168.99.1:/nfs-share /crash-dump
Überprüfen Sie, ob alles funktioniert. Dafür führen Sie den Befehl df -h aus. Ist die Konfiguration korrekt, sollten Sie eine Ausgabe erhalten wie in Abbildung 1.
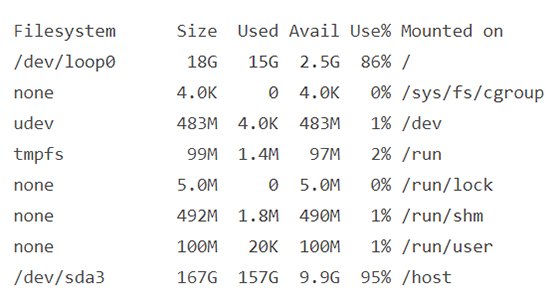 "Abbildung 1: Nachdem Sie die Logfile-Ausgabe über den NFS-Server eingerichtet haben, prüfen Sie das Setup mit df-h."
"Abbildung 1: Nachdem Sie die Logfile-Ausgabe über den NFS-Server eingerichtet haben, prüfen Sie das Setup mit df-h."
Überprüfen und Installieren von kdump und Crash Tool
Sie haben nun einen dedizierten Server, auf dem sich alle Absturzberichte sammeln lassen. Installieren Sie nun das Tool kdump und gehen Sie sicher, dass Sie wissen, wo die Absturzberichte gespeichert werden.
Überprüfen Sie, ob kdump auf dem Client läuft
Kdump ist bei CentOS 7 und 8 vorinstalliert. Führen Sie den Befehl systemctl status kdump aus, um den Status zu überprüfen. Sie sollten eine Ausgabe wie in Abbildung 2 erhalten.
Um das Paket kernel-dbuginfo auf Client und Server zu installieren, bearbeiten Sie mit einem Texteditor die Datei /etc/yum.repos.d/CentOS-Debuginfo.repo. Setzen Sie den Parameter enabled=1.
Durch kernel-debuginfo können Sie die Absturzberichte mit dem Crash Tool inspizieren. Installieren Sie es mit diesem Befehl: yum install -y kernel-debuginfo.
Modifizieren Sie im Anschluss den Standard-Upload-Ordner von kdump. Dafür editieren Sie die Daten /etc/kdump.conf. Ändern Sie hier den Standard-Pfad von /var/crash auf /crash-dump mit folgender Eingabe:
#path /var/crash
path /crash-dump
Ab hier beginnt der Spaß: Sie müssen den Kernel auf dem Client zum Absturz bringen.
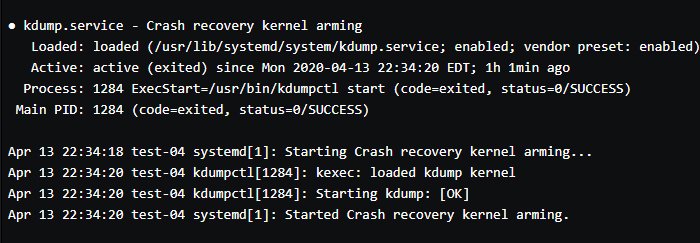 Abbildung 2: Die Ausgabe bestätigt, dass kdump installiert ist und läuft.
Abbildung 2: Die Ausgabe bestätigt, dass kdump installiert ist und läuft.
Führen Sie auf dem Client die beiden nachfolgenden echo-Befehle aus:
echo 1 > /proc/sys/kernel/sysrq
echo c > /proc/sysrq-trigger
Mit echo 1 > /proc/sys/kernel/sysrq bekommen Sie Zugriff auf alle SysRq-Funktionen. Nun können Sie Low-Level-Kernel-Befehle ausführen und an den Linux-Kernel schicken.
Mit echo c > /proc/sysrq-trigger schicken Sie einen sysrq-Befehl und erzwingen damit einen Absturz. Weil Sie die Kernel Panic mit echo-Befehlen erzwingen, sollte kdump die entsprechenden Absturzdateien an die NFS-Freigabe schicken.
Verbinden Sie sich wieder mit dem NFS-Server, um herauszufinden, was auf dem Client passiert ist. Überprüfen Sie zunächst, ob die Absturzberichte auf dem NFS-Server gespeichert wurden.
Führen Sie im Verzeichnis /crash-dump den Befehl ls -lh aus und sollten Sie bemerken, dass ein neues Verzeichnis angelegt wurde (Abbildung 3).
 Abbildung 3: Wenn alles funktioniert, legt kdump ein neues Verzeichnis an.
Abbildung 3: Wenn alles funktioniert, legt kdump ein neues Verzeichnis an.
Das neue Verzeichnis – 192.168.99.71-2020-04-14-12:20:47 – stammt vom Client und wurde während des Absturzes angelegt.
Suchen sie im Verzeichnis nach den beiden Dateien vmcore und vmcore-dmesg.txt. Vmcore-dmesg.txt ist die Log-Datei von dmesg und wurde zum Zeitpunkt des Absturzes im Klartext gespeichert. Mit dem Crash Tool können Sie vmcore weiter unter die Lupe nehmen und finden möglicherweise Hinweise, welche Prozesse und Dateien für den Absturz verantwortlich sein könnten.
Sie finden die Dateien wie in Abbildung 4:
 Abbildung 4: Die Konsole zeigt an, wo sich die Dateien vmcore und vmcore-dmesg.text befinden.
Abbildung 4: Die Konsole zeigt an, wo sich die Dateien vmcore und vmcore-dmesg.text befinden.
Um die Inhalte der Datei vmcore-dmesg.txt schnell zu überfliegen, öffnen Sie die Dateien in einem Text-Editor oder nutzen grep in Verbindung mit dem Wort crash, also folgendem Befehl: cat vmcore-dmesg.txt | grep -i crash
Wie Sie in Abbildung 5 sehen, hat SysRq einen Absturz ausgelöst, nachdem Sie die beiden echo-Befehle ausgeführt hatten.
Das Crash Tool nutzen
Mit dem Crash Tool können Sie einen Absturzbericht analysieren. Es ist bei CentOS 8 vorinstalliert. Mit den zugehörigen Befehlen können Sie herausfinden, welche Prozesse zum Zeitpunkt des Absturzes ausgeführt wurden.
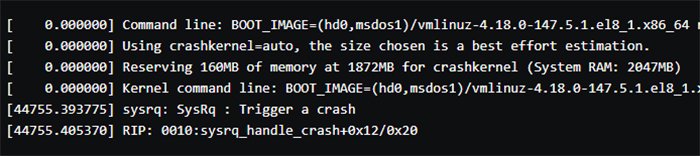 Abbildung 5: In der Datei finden Sie Informationen zum von Ihnen absichtlich ausgelösten Crash wieder.
Abbildung 5: In der Datei finden Sie Informationen zum von Ihnen absichtlich ausgelösten Crash wieder.
Starten Sie das Crash Tool auf den NFS-Server und benutzen die entsprechende vmcore-Datei:
crash /nfs-share/vmcore /usr/lib/debug/lib/modules/4.18.0-147.5.1.el8_1.x86_64/vmlinux
Nun ändert sich der Shell-Befehl zum Crash-Befehl (crash>). Prüfen Sie jetzt mit ps, welche Prozesse gelaufen sind (Abbildung 6).
Der Befehl vm zeigt alles an, was zum Zeitpunkt des Absturzes im virtuellen Arbeitsspeicher lief und mit files können Sie weitere Nachforschungen durchführen sowie einsehen, welche Dateien zum Zeitpunkt des Absturzes geöffnet waren.
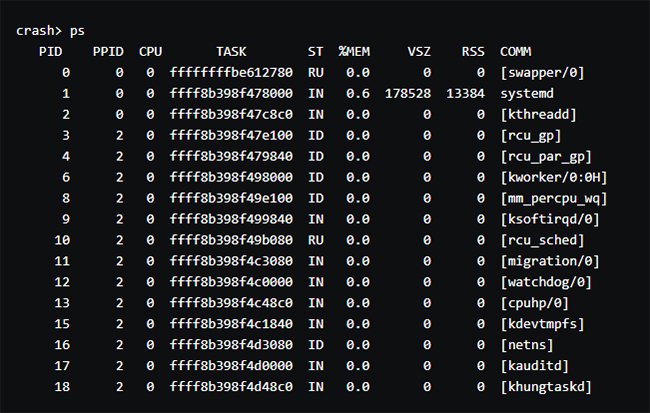 Abbildung 6: In der Konsole werden sämtliche Prozesse zum Zeitpunkt der Kernel Panic ausgegeben.
Abbildung 6: In der Konsole werden sämtliche Prozesse zum Zeitpunkt der Kernel Panic ausgegeben.
Führen Sie den Befehl log aus, um Einblicke in die Logs zu bekommen. Die Ausgabe ist identisch zu der von vmcore-dmesg.txt.
Mit den Informationen, die Sie mit den Befehlen ps, vm, files und log bekommen, finden Sie mit kdump und dem Crash Tool heraus, was die Kernel Panic bei Linux ausgelöst hat.
Dank des NFS-Servers können Sie die Absturzberichte auf einer unabhängigen Maschine speichern und müssen nicht auf dem betroffenen Computer nach dem Fehler suchen. Durch die beiden Dateien vmcore-dmesg.txt und vmcore bekommen Sie Informationen über den Zustand des Systems zum Zeitpunkt des Absturzes und damit hoffentlich die Gründe für diesen.







