
adam121 - stock.adobe.com
Warum Latenz-Messungen in der Cloud so wichtig sind
Um bestmögliche Zugriffszeiten in der Cloud zu erreichen, sollten wichtige Kennzahlen wie die Storage-Latenz und Congestion gemessen werden. StorPool veranschaulicht, warum.
Unternehmen, die Daten in der Public Cloud lagern oder verarbeiten, müssen auf einige Kriterien achten, damit Daten und Anwendungen gemäß der Firmenerwartungen verarbeitet, abgerufen oder gespeichert werden können. Eine der wichtigsten Kennzahlen hierbei ist die Latenz der jeweiligen Cloud-Umgebung.
Aber warum ist die Latenz der wohl wichtigste Faktor und wie erreicht man die möglichst niedrigste Latenzzeit für die Cloud?
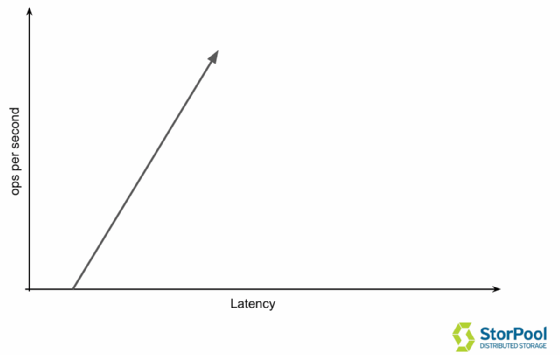
Jedes Transaktionsverarbeitungssystem hat spezifische Merkmale. Ob es sich nun um einen Webserver, eine Datenbank, ein Speichersystem oder so ziemlich jedes andere System handelt, es hat die gleichen Eigenschaften – bei einer geringen Anzahl von Transaktionen pro Sekunde erhalten Sie eine geringe Latenz.
Wenn Sie die Anzahl der Transaktionen erhöhen, steigt entsprechend auch die Latenzzeit. Dies kann in der folgenden Grafik sehr einfach veranschaulicht werden.
In einem idealen System, das es in Wirklichkeit natürlich nicht gibt, führt die Erhöhung der Operationen pro Sekunde (IOPS) jedoch nicht zu einer Änderung der Latenzzeit. Das Interessante dabei ist, dass, wenn man über 4 Tasks auf 4 CPU-Kernen hinausgeht, zum Beispiel bei 6 Tasks, diese in 1,5 Sekunden statt einer Sekunde verarbeitet werden. Hier verändert sich das lineare Eigenschaftsverhalten des Systems auf und arbeitet völlig anders.
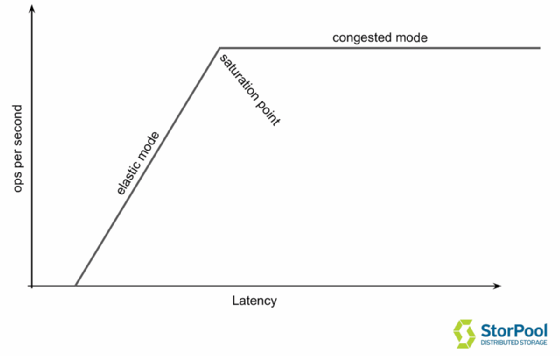
Elastischer Modus vs. Congestion-Modus
Die meisten Transaktionsverarbeitungssysteme haben zwei sehr unterschiedliche Betriebsarten. Wir haben sie als elastischen und Congested (zu deutsch: überlastet) Modus bezeichnet, die durch einen Auslastungspunkt getrennt sind. Mit anderen Worten, bis zu einer bestimmten Anzahl von Ladungen fordern Sie mehr vom System an und erhalten im Gegenzug mehr davon. Aber sobald Sie den Auslastungspunkt überschritten haben, fordern Sie mehr vom System an, aber Sie erhalten einfach mehr Latenz zurück.
Im Idealfall möchten Sie Ihre Operationen im elastischen Modus durchführen. In diesem Teil der Kurve werden die Operationen in angemessener Zeit durchgeführt und die Latenzzeit ist gering. Die niedrigsten Kosten pro gelieferter Ressource können am Ende des elastischen Modus (90 Prozent Last), kurz vor der Trennstelle, erreicht werden. Wenn Sie dagegen die Trennstelle passieren, verzehnfacht sich die Ladezeit.
Ein interessantes Leistungsmerkmal ist auch der Systemdurchsatz, der zeigt, wie hoch der Auslastungspunkt ist und wie viele Transaktionen pro Sekunde das System in einem Modus verarbeiten kann. Sie wird in der Regel in Transaktionen pro Sekunde, geöffneten Seiten pro Sekunde und so weiter ausgedrückt.
Die geringste Latenzzeiten erreicht ein Unternehmen natürlich, wenn es weit unter dem Auslastungspunkt bleibt, allerdings ist dies eine Verschwendung von Ressourcen und somit Kosten. Optimal ist es, wenn die Workload bis kurz an Auslastungspunkt gelangt, denn hier erreicht der Anwender das beste Preis-Leistungsverhältnis, da er hier das Optimum an Performance erzielt wird.
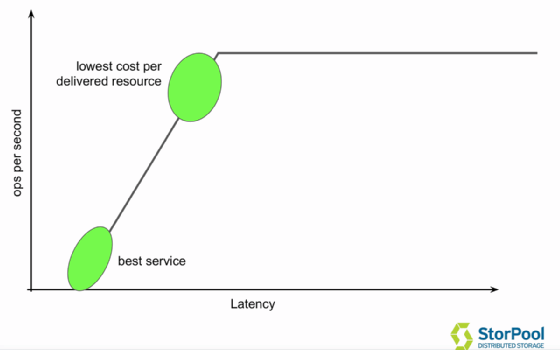
Gerade für Cloud-Services ist es wichtig, diesen Punkt und somit die Transaktionslast korrekt zu bestimmen, da sonst die (fehlende) Performance den Preis des Systems nicht mehr rechtfertigt. Da die meisten Cloud-Anbieter die Kosten nicht nur pro Speicherplatz, sondern eben auch pro Transaktion beziehungsweise Durchsatz (teuer) berechnen, möchte man als Kunde natürlich das Meiste aus seinem Service herausholen.
Ein System kann noch so gute Leistungsparameter haben, wenn der Congestion-Modus erreicht wird, kann das System seine Leistungen nicht abrufen beziehungsweise an die Workload bringen. Für beste Services ist es also wünschenswert, dass die Transaktionen immer im elastischen Modus ablaufen und den so genannten Saturation Point (Auslastungspunkt) nicht überschreiten. Den geringsten Kostenpunkt pro Performance erreicht man allerdings, je näher man am Sättigungspunkt ankommt, da hier viele Transaktionen bei noch vertretbarer Latenz verarbeitet werden können. Das entspricht in etwa 90 Prozent der Auslastung des Systems.
Liegen die Anfragen, also der Datendurchsatz, über dem Sättigungspunkt, so kann dies zu „schmerzhaften“ Auswirkungen für den Anwender führen: das Nutzererlebnis und die generelle Performance brechen zusammen, das System kann die geforderte Leistung nicht mehr abliefern.
Berechnung der Latenzzeit
Oftmals fokussieren sich Benchmark-Tests auf den Durchsatz von Systemen, verschweigen aber auch, dass dies quasi in Latenzen „bezahlt“ wird. Die IOPS werden hier höher gewertet als die Latenz. Das ist nicht unbedingt repräsentativ für diese Systeme. Allerdings ist diese Erkenntnis nicht neu. Bereits Mitte der 1990er Jahre gab es Grafiken, die diese Entwicklung bei der Auslastung von Systemen sehr deutlich widerspiegelten.
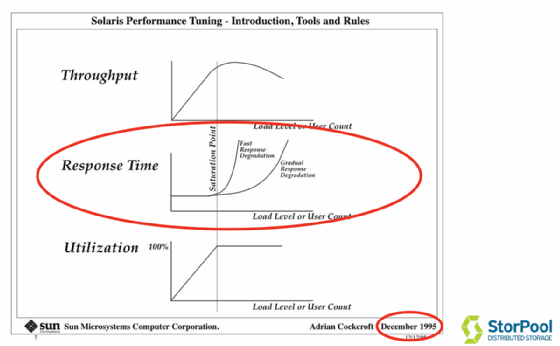
Viele Unternehmen, die Public Cloud anbieten, wie AWS, Digital Ocean, Google, OVH (Ceph) oder DreamHost verkaufen Festplatten beziehungsweise Services mit einer bestimmten Anzahl von IOPS in ihrer Spezifikation. Oftmals werden in den Spezifikationen zu einzelnen Services eben nur die Werte für IOPS und Throughput (in MByte/s) angegeben. Wie bereits erwähnt, ist IOPS jedoch nur eines der vielen Leistungsmerkmale. Aber auf den Websites der oben genannten Unternehmen können Sie nur die IOPS und den Durchsatz sehen, die nicht annähernd so wichtig sind wie die Latenz. Dennoch gibt es eine einfache Möglichkeit, diese zu berechnen.
In diesem dedizierten Test, durchgeführt wurde die Workload von 50 Prozent Reads und 50 Prozent Writes in 4 KByte großen Blöcken in mehreren Cloud-Umgebungen ausgeführt. Der Anbieter DreamHost/DreamCompute kam auf eine Latenz von 4,5 ms, Digital Ocean kam auf 1,75 ms. Der Service Amazon EBS, der etwa 250 US-Dollar pro Monat kostet, kann 0,29 ms bieten, der Provider eApps (50 US-Dollar pro Monat) kommt auf eine Latenz von 0,41 ms. StorPool BCP selbst erreichte in diesem Test 0,17 ms. StorPool verwendete für jeden einzelnen Test die gleiche Menge an Speicher, CPUs, die gleiche Methodik und die gleiche Datenbank verwendet. Dream Host und Digital Ocean, beide basierend auf CEPH, sind nicht in der Lage, 1000 TPS zu bedienen. Der Grund dafür ist die hohe Latenzzeit. AWS hingegen kann diesen Service zu einem vernünftigen Preis anbieten.
StorPool prüfte auch das eigene Angebot, BCP und kam auf eine höhere Anzahl an Transaktionen pro Sekunde (7500 TPS). Die einzigen beiden Dinge, die hier geändert wurden, waren der Einsatz von NVMe-SSDs verwendet und statt eines 10-GbE-Netzwerks wurde mit einer 25-GbE-Umgebung gearbeitet.
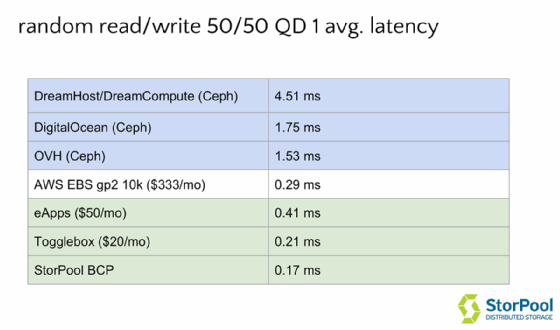
In einem direkten Vergleichstest mit zwei identischen virtuellen Disks, zeigt sich, dass ein schnelles Volume doppelt so viele Transaktionen zulässt als ein langsames Volume, aufgrund der steigenden Latenz pro Transaktion. In realen Cloud-Umgebungen führt das zu einer schlechten Nutzererfahrung, verlangsamten Arbeitsprozessen und Leistungseinbußen.
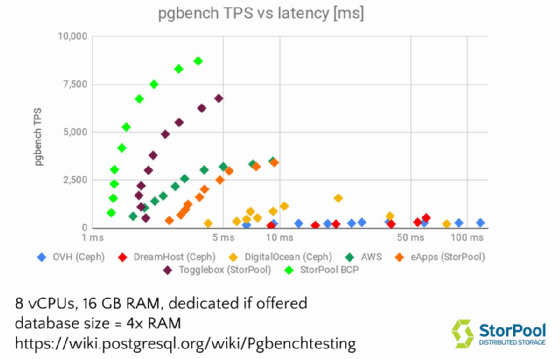
Public Cloud Provider geben normalerweise nicht die Latenzzeiten, die sie Kunden eventuell garantieren könnten (oder auch nicht). Im bereits erwähnten Test unter pgbench sieht man, dass eine Empfehlung für die Anzahl der Transaktionen und /oder die Datenbankgröße zu optimalen Ergebnissen führen kann, die eine ausgewogene Balance zwischen hoher Transaktionsdichte und geringer Latenz bieten. Ein schnelleres Storage-System kann hier den entscheidenden Unterschied und bessere Applikations-Performance bringen.

„Unternehmen, die Daten in der Public Cloud lagern oder verarbeiten, müssen auf einige Kriterien achten, damit Daten und Anwendungen gemäß der Firmenerwartungen verarbeitet, abgerufen oder gespeichert werden können. Eine der wichtigsten Kennzahlen hierbei ist die Latenz der jeweiligen Cloud-Umgebung.“
Boyan Krosnov, StorPool Storage
Ein weiterer wichtiger Faktor, der für einen optimalen Cloud-Betrieb eine Rolle spielt, ist das Verständnis, zwischen Oversubscription und Congestion zu unterscheiden. Wer zwischen diesen beiden Punkten unterscheiden kann, der kann letztlich seine Workload sinnvoll planen beziehungsweise die notwendigen Cloud-Ressourcen dafür. Während eine Oversubscription, also das Allokieren von mehr Ressourcen als tatsächlich vorhanden, keinen Einfluss auf die Nutzererfahrung hat, beeinträchtigt eine Congestion sehr wohl die Arbeitsprozesse.
Über den Autor:
Boyan Krosnov ist Mitbegründer und Chief of Product bei StorPool Storage. Boyan baut seit 1999 IT-Infrastrukturen. Er hat die Implementierung mehrerer Triple-Play-Betreiber in Großbritannien, Irland, Island, Bulgarien und Malaysia von Grund auf geleitet. Davor war Boyan Mitbegründer eines Start-up-Unternehmens, das ultrahochleistungsfähige Netzwerksoftware entwickelte.
Die Autoren sind für den Inhalt und die Richtigkeit ihrer Beiträge selbst verantwortlich. Die dargelegten Meinungen geben die Ansichten der Autoren wieder und entsprechen nicht unbedingt denen von ComputerWeekly.de.







