
Suriyo - stock.adobe.com
Generative Modelle: VAE, GAN, Diffusion, Transformer, NeRF
Von der Bereitstellung von Chatbots bis hin zu realistischen Bildgeneratoren – generative Modelle sind für viele KI-Anwendungen von entscheidender Bedeutung.

Generative Modelle – eine Art von Machine-Learning-Modellen, die auf der Grundlage von Trainingsdaten neue Inhalte erstellen können – stehen heute im Mittelpunkt der KI-Entwicklung. Sie sind die Technologie, die generative KI und agentenbasierte KI möglich macht.
Die Ansätze für das Design und die Implementierung generativer Modelle variieren. Je nach Anwendungsfall oder Verfügbarkeit von Trainingsdaten kann ein bestimmter Typ generativer Modelle besser geeignet sein als ein anderer.
Es gibt fünf Haupttypen von generativen Modellen, die heute weit verbreitet sind: Variational Autoencoder (VAE), Generative Adversarial Networks (GAN), Diffusionsmodelle, Transformer und neuronale Strahlungsfelder (Neural Radiance Fields, NeRF). Um zwischen den verschiedenen generativen Modellen zu wählen, müssen Unternehmen untersuchen, wie jedes einzelne funktioniert, sowie ihre Stärken, Grenzen und Anwendungsfälle.
Die 5 wichtigsten Arten generativer Modelle
Generative Modelle identifizieren Muster in den Trainingsdaten und verwenden diese Muster, um durch einen als Inferenz bezeichneten Prozess neue Daten zu generieren. Die neuen Daten ähneln in Form und Inhalt den Trainingsdaten, sind jedoch nicht identisch.
Betrachten wir zum Beispiel ein Modell, das durch die Analyse Tausender Katzenbilder trainiert wurde, um die Formen und Farben von Katzen zu verstehen. Wenn ein Benutzer das Modell auffordert, ein neues Katzenbild zu erstellen, kann das Modell ein Bild auf der Grundlage dieser visuellen Attribute erstellen, aber das Bild wäre nicht identisch mit einem bestimmten Katzenbild aus den Trainingsdaten des Modells.
Obwohl alle generativen Modelle Muster verwenden, die sie in den Trainingsdaten identifiziert haben, um neue Inhalte zu generieren, variiert die Art und Weise, wie sie die Trainingsdaten verarbeiten und verwenden.
Hier sind fünf gängige Arten von generativen Modellen:
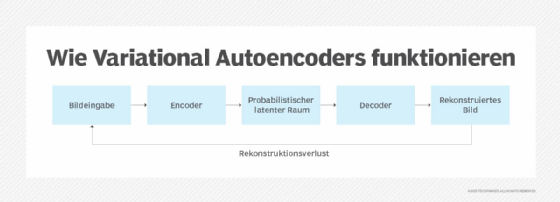
1. Variational Autoencoders (VAE)
Variational Autoencoders arbeiten nach folgendem Prinzip:
- Ein Encoder verarbeitet jeden Trainingsdatenpunkt und erstellt dann eine Wahrscheinlichkeitsverteilung, die eine Reihe potenziell relevanter Merkmale darstellt.
- Die Daten werden zufällig aus der Wahrscheinlichkeitsverteilung entnommen und mit den ursprünglichen Trainingsdaten verglichen.
- Das Modell weist eine Punktzahl zu, die angibt, wie ähnlich die Stichprobendaten und die Originaldaten sind. Bei einer hohen Punktzahl – das heißt wenn die Daten ähnlich sind – markiert das Modell den Stichprobendatenpunkt und den entsprechenden Bereich der Wahrscheinlichkeitsverteilung als relevante Daten, die das Modell speichern soll.
- Um neue Inhalte zu erstellen, vergleicht das Modell neue Dateneingaben mit den Daten, die es aus Stichprobenwerten gespeichert hat. Anschließend erstellt es neue Inhalte, die den akzeptierten Stichprobeninhalten ähneln, die es gespeichert hat.
Vorteile von VAE
Ein wesentlicher Vorteil von VAEs besteht darin, dass sie einen quantitativen Ansatz zur Bewältigung von Unsicherheiten verwenden. Sie nutzen Wahrscheinlichkeitsverteilungen und Vergleichswerte, um die Wahrscheinlichkeit von Beziehungen zwischen zwei oder mehr Datenpunkten zu bestimmen. Dies ist in Situationen von Vorteil, in denen die Trainingsdaten die Daten, die ein Modell generieren oder bewerten soll, nicht vollständig repräsentieren. VAEs füllen die Lücken zwischen Trainingsdaten und Inferenz-Input, indem sie anhand von Wahrscheinlichkeiten erraten, wie die Werte aussehen sollten.
Aus diesem Grund sind VAEs besonders nützlich in Situationen, in denen die Trainingsdaten begrenzt oder von geringer Qualität sind. VAEs erzielen mit schlechten Trainingsdaten tendenziell bessere Ergebnisse als andere Arten von generativen Modellen. Sie sind auch in Situationen nützlich, in denen die Attribute der einzelnen Datenproben tendenziell stark variieren, zum Beispiel bei der Verarbeitung medizinischer Bilder oder der Analyse der chemischen Strukturen von Arzneimittelmolekülen.
Nachteile von VAEs
Die wahrscheinlichkeitsorientierte Strategie von VAEs bedeutet, dass sie feine Details übersehen können. Sie sind weniger geeignet als einige andere Modelltypen, wie zum Beispiel GANs, um Situationen zu identifizieren, in denen die Trainingsdaten perfekt zu den neuen Daten passen, die ein Benutzer vom Modell generiert haben möchte.
Wenn beispielsweise die Aufforderung lautet, den Satz „1492 segelte Kolumbus über den [Leerstelle] Ozean“ zu vervollständigen, ist es weniger wahrscheinlich, dass ein VAE mit „blauen“ antwortet, da es eher dazu neigt, eine Reihe möglicher Antworten in Betracht zu ziehen, anstatt zu erkennen, dass „blauen“ diesen Satz vervollständigt.
Wann sollte ein VAE verwendet werden?
VAEs eignen sich am besten für die folgenden Szenarien:
- Wenn die Trainingsdaten in Umfang oder Menge begrenzt sind.
- Wenn Ungenauigkeiten in der Ausgabe, wie zum Beispiel unscharfe Bilder, toleriert werden können.
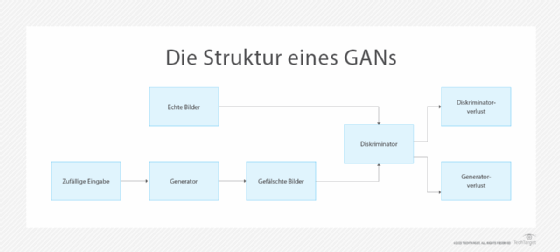
2. Generative Adversarial Networks (GAN)
Generative Adversarial Networks basieren auf einem Trainingsprozess, bei dem zwei Funktionen als Gegner gegeneinander antreten. Der Prozess funktioniert wie folgt:
- Wenn ein Generator mit Trainingsdaten konfrontiert wird, erstellt er neue Daten.
- Ein Diskriminator vergleicht die vom Generator erzeugten Daten mit den tatsächlichen Trainingsdaten.
- Der Diskriminator berechnet eine Punktzahl, in der Regel im Bereich von 0 bis 1, die angibt, ob die generierten Daten den Trainingsdaten ähneln.
- Der Generator erhält Feedback darüber, wie hoch seine Daten bewertet wurden. Anhand dieses Feedbacks generiert er eine neue Iteration der Daten, die der Diskriminator erneut bewertet.
Zu Beginn des Trainings sind die vom Generator erstellten Daten im Wesentlichen zufällig. Mit der Zeit erkennt der Diskriminator jedoch Fälle, in denen die Daten des Generators den Trainingsdaten ähneln. Durch Wiederholung dieses Prozesses lernen GAN-Modelle nach und nach, wie sie neue Daten erzeugen können, die den Trainingsdaten sehr ähnlich sind.
Wie VAEs vergleichen auch GANs generierte Daten mit Trainingsdaten. Während ein VAE jedoch probabilistische Zuordnungen verwendet, um die Ähnlichkeit zwischen Trainingsdaten und generierten Daten vorherzusagen, erzeugt ein GAN iterativ generierte Daten, die mit der Zeit nicht mehr von den Trainingsdaten zu unterscheiden sind. Dadurch wird sichergestellt, dass die neuen Daten die Trainingsdaten genau widerspiegeln.
Vorteile von GANs
Ein wesentlicher Vorteil von GANs ist ihre Genauigkeit. Wenn der Trainingsprozess lange genug andauert, lernen GANs nuancierte Details über die Trainingsdaten, die sie zur Erstellung hochrealistischer Inhalte verwenden. Beispielsweise sind von GANs erzeugte Bilder in der Regel schärfer und detailreicher als die von VAEs generierten.
GANs können auch schneller neue Inhalte generieren. Das liegt daran, dass sie bei der Generierung neuer Daten keine probabilistische Bewertung durchführen müssen, sodass die Inferenz weniger Rechenaufwand erfordert.
Nachteile von GANs
GANs erfordern in der Regel mehr Trainingszeit, da der Trainingsprozess zusätzliche Iterationen erfordert, um ein zuverlässiges und genaues Modell zu erstellen. Außerdem verbrauchen sie während des Trainings mehr Rechenressourcen, was das GAN-Training zeitaufwändig und teuer machen kann.
GANs sind auch nicht besonders gut im Umgang mit Trainingsdatensätzen mit einer großen Anzahl von Ausreißern. Sie ignorieren Ausreißer in der Regel, da der Generator niemals eine Ausgabe erzeugt, die den Ausreißern ähnlich genug ist, um vom Diskriminator eine hohe Punktzahl zu erhalten.
Wann sollte ein GAN verwendet werden?
Ziehen Sie ein GAN-Modell für die folgenden Szenarien in Betracht:
- Wenn eine hochpräzise Ausgabe erforderlich ist.
- Wenn umfangreiche Rechenleistung für das Training zur Verfügung steht.
- Wenn eine vergleichsweise kostengünstige, schnelle Inhaltserstellung erforderlich ist.
3. Diffusionsmodelle
Diffusionsmodelle funktionieren wie folgt:
- Sie fügen Rauschen in die Trainingsdaten ein und wiederholen diesen Vorgang, bis keine erkennbare Beziehung mehr zwischen den Originaldaten und den modifizierten Daten besteht.
- Um neue Inhalte zu erstellen, entfernen sie das Rauschen schrittweise. Dieser Entrauschungsprozess ist jedoch keine einfache Umkehrung des Prozesses, durch den das Rauschen ursprünglich eingefügt wurde. Das Ergebnis ist, dass die neuen Inhalte den ursprünglichen Inhalten ähnlich, aber nicht identisch sind.
In der Vergangenheit wurden Diffusionsmodelle hauptsächlich zur Erzeugung von Bildern, Videos und Audiodateien verwendet. In den letzten Jahren haben Forscher begonnen, Diffusion auch als Option für die Textanalyse und -erzeugung zu untersuchen.
Vorteile von Diffusionsmodellen
Diffusionsmodelle erzeugen hochpräzise visuelle und akustische Inhalte – in einigen Fällen sogar präziser als die von GANs generierten Inhalte. Sie sind auch einfacher zu trainieren als GANs, da sie weniger anfällig für Risiken sind, wie zum Beispiel abweichende Datenpunkte, die zum Zusammenbruch des Modells beitragen können.
Nachteile von Diffusionsmodellen
Ein Nachteil von Diffusionsmodellen ist, dass die Prozesse des Hinzufügens und Entfernens von Rauschen erhebliche Rechenleistung erfordern. Daher kann das Training dieser Modelle kostspielig und zeitaufwändig sein.
Darüber hinaus sind Diffusionsmodelle trotz ihrer hohen Genauigkeit anfälliger für Probleme wie das Übersehen von Details bei der Generierung neuer Inhalte. Beispielsweise können sie bei der Erstellung eines Bildes einer Person zusätzliche Finger hinzufügen. Dies liegt vor allem daran, dass der Prozess der Rauschunterdrückung weniger gut geeignet ist, Nuancen zuverlässig zu erfassen.
Die wichtigste Abhilfe hierfür besteht darin, sicherzustellen, dass die Trainingsdaten ausreichend groß und vielfältig sind, um alle wesentlichen Details zu repräsentieren, die für eine zuverlässige Inhaltsgenerierung erforderlich sind. Diffusionsmodelle übersehen in der Regel Details, die in den Trainingsdaten nicht häufig vorkommen.
Wann sollten Diffusionsmodelle verwendet werden?
Diffusionsmodelle funktionieren am besten in den folgenden Szenarien:
- Wenn ein großer, vielfältiger Satz von Trainingsdaten vorhanden ist.
- Wenn umfangreiche Rechenleistung für das Training zur Verfügung steht.
- Wenn die Anwendungsfälle auf die Generierung von visuellen oder akustischen Inhalten beschränkt sind. Wie oben erwähnt, haben Diffusionsmodelle auch Potenzial für die Arbeit mit textuellen Inhalten, aber dies ist derzeit noch kein ausgereifter Anwendungsfall.
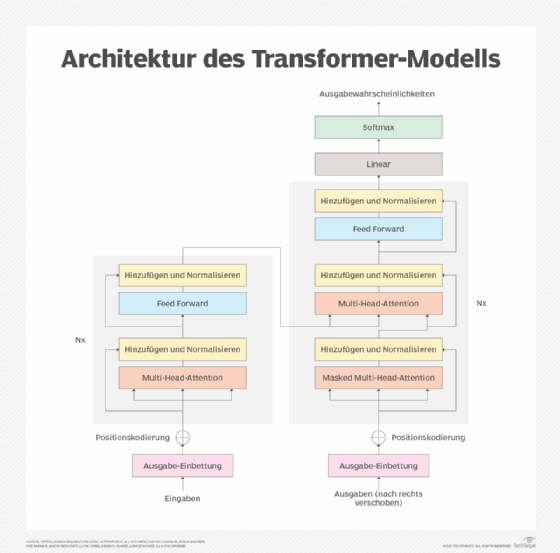
4. Transformer
Transformer-Modelle sind die wichtigste Art von generativen Modellen, die hinter den meisten bekannten generativen KI-Produkten stehen, wie ChatGPT von OpenAI und Gemini von Google. Transformer verwenden den folgenden Aufmerksamkeitsmechanismus, der die Trainingsdaten analysiert:
- Die Eingabedaten werden in Token unterteilt, die Teile der Daten darstellen. Wenn es sich bei den Eingabedaten beispielsweise um einen Satz handelt, können die Token einzelne Wörter innerhalb des Satzes sein.
- Das Modell berechnet die Bedeutung der Beziehungen zwischen den Token. Auf diese Weise bestimmt das Modell, welche Token die größte Aufmerksamkeit erhalten sollten – daher der Begriff Aufmerksamkeitsmechanismus.
Um eine Ausgabe zu generieren, verwenden Transformer-Modelle die Ergebnisse des Aufmerksamkeitsprozesses, um zu bestimmen, welche Tokens auf andere Tokens folgen sollten. Auf diese Weise konstruieren sie neuartigen Text.
Vorteile von Transformer-Modellen
Der herausragende Vorteil von Transformern gegenüber anderen generativen Modellen besteht darin, dass sie sich hervorragend für die Interpretation von Kontexten und die Identifizierung von Fernbeziehungen eignen und Verbindungen zwischen Datenpunkten herstellen, die sonst möglicherweise nicht offensichtlich wären.
Transformer tun dies, indem sie Token innerhalb verschiedener Stichproben aus den Trainingsdaten vergleichen und analysieren, wie sich die Beziehungen zwischen den Token unterscheiden.
Nachteile von Transformer-Modellen
Transformer-Modelle sind zwar leistungsstark, erfordern jedoch große Datensätze, um effektiv trainiert zu werden. Außerdem stellen sie sowohl während des Trainings als auch während der Inhaltsgenerierung hohe Anforderungen an die Rechenleistung. Schließlich weisen sie einen geringen Grad an Modellerklärbarkeit auf, was bedeutet, dass es schwierig sein kann, zu bestimmen, welche Trainingsdaten zu welcher Ausgabe geführt haben.
Wann sollten Transformer-Modelle verwendet werden?
Transformer-Modelle sind in den folgenden Fällen ideal:
- Bei einem sehr großen Satz von Trainingsdaten.
- Wenn die Anwendungsfälle sehr unterschiedlich sind, das heißt wenn Sie in der Lage sein müssen, eine breite Palette von Inhalten zu produzieren.
- Wenn umfangreiche Rechenressourcen sowohl für das Modelltraining als auch für die Inferenz zur Verfügung stehen.
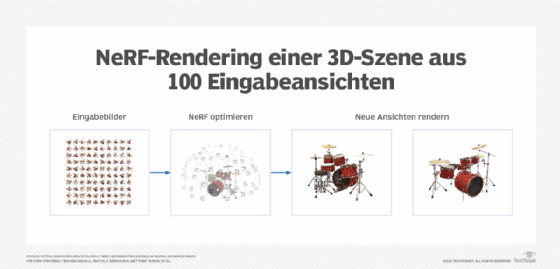
5. Neuronale Strahlungsfelder (Neural radiance fields, NeRF)
Neuronale Strahlungsfelder (Neural radiance fields, NeRF) sind in erster Linie für die Erzeugung von 3D-Videos aus Standbildern konzipiert. Sie funktionieren wie folgt:
- Auf der Grundlage von Standbildern erzeugt das Modell eine Reihe von Strahlen. Jeder Strahl ist eine Linie, die sich vom Blickpunkt der Kamera durch einen bestimmten Pixel im 3D-Inhalt erstreckt.
- Mithilfe eines neuronalen Netzwerks sagt das Modell voraus, welche Farbe und Dichte jeder Punkt entlang jedes Strahls haben sollte.
- Das Modell vergleicht die von ihm generierten Strahlen mit den Originalbildern, um zu bestimmen, welche beibehalten werden sollen.
Durch die Wiederholung dieses Prozesses erzeugen NeRFs 3D-Inhalte, die den Inhalt der Standbilder genau widerspiegeln.
Vorteile von NeRFs
Obwohl auch andere Modelltypen, wie beispielsweise Diffusionsmodelle, 3D-Inhalte auf der Grundlage von Standbildern generieren können, benötigen NeRFs dafür vergleichsweise wenig Trainingsdaten. Außerdem benötigen sie keine Trainingsdaten, die 3D-Inhalte enthalten, sondern können 3D-Inhalte konstruieren, indem sie anhand des Inhalts von 2D-Bildern erraten, welche Strahlen einbezogen werden sollen.
Nachteile von NeRFs
NeRFs erfordern erhebliche Rechenressourcen, und der Prozess der Generierung neuer Inhalte ist oft langsam. Daher eignen sich NeRFs schlecht für Anwendungsfälle, die eine Echtzeit-Inhaltsgenerierung erfordern, wie z. B. die Erstellung dynamischer Szenerien für ein 3D-Spiel oder eine virtuelle Welt. Allerdings funktionieren NeRFs gut in Situationen, in denen 3D-Inhalte im Voraus produziert werden können, zum Beispiel bei der Generierung von Grafiken, die in ein Videospiel geladen werden können, anstatt dynamisch zur Laufzeit generiert zu werden.
Wann sollten NeRFs verwendet werden?
Ziehen Sie NeRFs für die folgenden Szenarien in Betracht:
- Wenn die Erstellung von 3D-Inhalten der einzige Anwendungsfall ist; NeRFs eignen sich nicht für andere Arten von Aufgaben.
- Wenn nur begrenzte Trainingsdaten zur Verfügung stehen.
- Wenn keine schnelle Inhaltsgenerierung erforderlich ist.
Wie wählt man zwischen generativen Modellen aus?
Um das richtige generative Modell für ein Projekt auszuwählen, sollten Sie Folgendes berücksichtigen:
- Verwendungszweck. Einige Modelle sind auf bestimmte Anwendungsfälle beschränkt, wie zum Beispiel Diffusionsmodelle, die in der Regel nur für die Bilderzeugung geeignet sind. GANs und Transformer sind offener und flexibler.
- Umfang und Qualität der Trainingsdaten. Wenn die Trainingsdaten in Umfang oder Qualität begrenzt sind, ist ein Modelltyp wie VAE möglicherweise besser geeignet, um diese Einschränkungen zu umgehen.
- Trainingszeit. Einige Modelle benötigen weniger Zeit für das Training, wie zum Beispiel VAEs. Die Trainingszeit hängt davon ab, wie viele Rechenressourcen das Modell benötigt und wie viele Trainingsdaten es analysieren muss.
- Trainingsrisiken. Bei einigen Modellen ist die Wahrscheinlichkeit geringer, dass sie während des Trainings ausfallen oder ein Neustart des Trainingsprozesses erforderlich ist. Beispielsweise haben VAEs und Diffusionsmodelle in der Regel geringere Trainingsrisiken als GANs, die hohe Trainingsausfallraten aufweisen können.
- Inferenzzeit. Bei einigen Modellen ist die Inferenz schneller als bei anderen. Beispielsweise sind GANs in der Regel schneller bei der Generierung von Inhalten als VAEs.
Tabelle 1: Vergleichstabelle verschiedener generativer Modelle
| Modelltyp | Vorteile | Nachteile | Beispiele |
| VAE | Das Training ist relativ einfach und mit geringem Risiko verbunden. Kann gut mit Lücken in den Trainingsdaten umgehen. |
Die Inferenz ist tendenziell langsam. Die Genauigkeit kann eingeschränkt sein. |
Verarbeitung von Bildern mit sehr unterschiedlichen Inhalten, zum Beispiel Ergebnisse medizinischer Scans. |
| GAN | Hohe Genauigkeit. Generiert schnell und mit geringem Rechenaufwand neue Inhalte. |
Das Training kann komplex sein und weist eine hohe Fehlerquote auf. |
Bild- und Videogenerierung, die ein hohes Maß an Genauigkeit erfordert. |
| Diffusion | Risikoarmer Trainingsprozess. Inhalte sind sehr genau. |
Kann ungenau sein, insbesondere wenn die Trainingsdaten begrenzt sind. Training und Inferenz sind rechenintensiv. |
Hochwertige Bild-, Video- und Audiogenerierung. |
| Transformer |
Kann Beziehungen zwischen Datenpunkten erkennen, die andere Modelltypen übersehen. Sehr flexibel und unterstützt eine Vielzahl von Anwendungsfällen. |
Erfordert einen großen Trainingsdatensatz. Training und Inferenz sind beide rechenintensiv. |
Textzusammenfassung und -interpretation. |
| NeRF | Erstellt realistische 3D-Inhalte auf der Grundlage relativ kleiner Trainingsdatensätze. |
Unterstützt nur die Generierung von 3D-Inhalten. |
Generierung von 3D-Inhalten. |





