Neuronale Strahlungsfelder (Neural Radiance Field, NeRF)

Was sind neuronale Strahlungsfelder (Neural Radiance Field, NeRF)?
Neuronale Strahlungsfelder (Neural Radiance Field, NeRF) sind eine Technik, die mit fortschrittlichem maschinellem Lernen 3D-Darstellungen eines Objekts oder einer Szene aus 2D-Bildern generiert. Bei dieser Technik wird das gesamte Objekt oder die gesamte Szene in ein künstliches neuronales Netz (KNN) kodiert, das die Lichtintensität – oder Strahlung – an jedem Punkt im 2D-Bild vorhersagt, um neuartige 3D-Ansichten aus verschiedenen Blickwinkeln zu erzeugen.
Der Prozess ist vergleichbar mit der Art und Weise, wie Hologramme verschiedene Perspektiven kodieren können, die durch das Einstrahlen eines Lasers aus verschiedenen Richtungen freigeschaltet werden. Im Fall von NeRFs sendet eine App anstelle des Lichteinfalls eine Anfrage, die die gewünschte Betrachtungsposition und die Größe des Ansichtsfensters angibt, und das neuronale Netzwerk generiert die Farbe und Dichte jedes Pixels im resultierenden Bild.
NeRFs sind äußerst vielversprechend, da sie 3D-Daten effizienter darstellen als andere Techniken. Sie können neue Wege zur automatischen Erzeugung hochrealistischer 3D-Objekte eröffnen. In Kombination mit anderen Techniken haben NeRFs ein unglaubliches Potenzial, 3D-Darstellungen der Welt von Gigabyte auf Dutzende Megabyte massiv zu komprimieren. Das Time Magazine bezeichnete eine NeRF-Implementierung des Chipherstellers Nvidia als eine der Top-Erfindungen des Jahres 2022. Alexander Keller, Forschungsleiter bei Nvidia, sagte gegenüber Time, dass NeRFs für 3D-Grafiken genauso wichtig sein könnten wie Digitalkameras für die moderne Fotografie.
Anwendungen neuronaler Strahlungsfelder
NeRFs können zur Erstellung von 3D-Modellen von Objekten sowie zur Darstellung von 3D-Szenen für Videospiele und für virtuelle und erweiterte Realitätsumgebungen im Metaverse verwendet werden.
Google hat bereits damit begonnen, NeRFs zu verwenden, um Straßenkartenbilder in Google Maps in immersive Ansichten zu übersetzen. Das Unternehmen für Konstruktionssoftware Bentley Systems hat NeRFs auch als Teil seines iTwin Capture-Tools verwendet, um hochwertige 3D-Darstellungen von Objekten mit einer Handykamera zu analysieren und zu generieren.
In Zukunft können NeRFs andere Techniken zur Darstellung von 3D-Objekten im Metaverse, in Augmented Reality und digitalen Zwillingen effizienter, genauer und realistischer ergänzen.
Ein großer Vorteil von NeRFs ist, dass sie mit Lichtfeldern arbeiten, die Formen, Texturen und Materialeffekte direkt charakterisieren – beispielsweise wie verschiedene Materialien wie Stoff oder Metall im Licht aussehen. Im Gegensatz dazu beginnen andere 3D-Verarbeitungstechniken mit Formen und fügen dann Texturen und Materialeffekte mithilfe sekundärer Prozesse hinzu.
Frühe Anwendungen. Die ersten NeRFs waren unglaublich langsam und erforderten, dass alle Bilder mit derselben Kamera unter denselben Lichtverhältnissen aufgenommen wurden. Die erste Generation von NeRFs, die von Forschern von Google und der University of California, Berkeley, im Jahr 2020 beschrieben wurde, benötigte zwei bis drei Tage für das Training und mehrere Minuten für die Erstellung jeder Ansicht. Die ersten NeRFs konzentrierten sich auf einzelne Objekte wie ein Schlagzeug, Pflanzen oder Lego-Spielzeug.
Kontinuierliche Innovation. Im Jahr 2022 entwickelte Nvidia eine Variante namens Instant NeRFs, die in etwa 30 Sekunden feine Details in einer Szene erfassen und dann in etwa 15 Millisekunden verschiedene Ansichten rendern konnte. Google-Forscher berichteten auch über neue Techniken für NeRF in the Wild, ein System, das NeRFs aus Fotos erstellen kann, die von verschiedenen Kameras, bei unterschiedlichen Lichtverhältnissen und mit temporären Objekten in der Szene aufgenommen wurden. Dies ebnete den Weg für die Verwendung von NeRFs zur Erzeugung von Inhaltsvariationen auf der Grundlage simulierter Lichtverhältnisse oder unterschiedlicher Tageszeiten.
Neue NeRF-Anwendungen. Heutzutage rendern die meisten NeRF-Anwendungen einzelne Objekte oder Szenen aus verschiedenen Perspektiven, anstatt Objekte oder Szenen zu kombinieren. So verwendete beispielsweise die erste Google Maps-Implementierung die NeRF-Technologie, um einen kurzen Film zu erstellen, der einen Hubschrauber simuliert, der um ein Gebäude fliegt. Dadurch entfielen die Herausforderungen, die NeRF auf verschiedenen Geräten zu berechnen und mehrere Gebäude zu rendern. Forscher suchen jedoch nach Möglichkeiten, NeRFs so zu erweitern, dass auch hochwertige Geodaten generiert werden können. Dies würde das Rendern großer Szenen erleichtern. NeRFs können schließlich auch eine bessere Möglichkeit bieten, andere Arten von Bildmaterial, wie MRT- und Ultraschallaufnahmen, zu speichern und zu rendern.
Wie funktionieren neuronale Strahlungsfelder?
Der Begriff neuronales Strahlungsfeld beschreibt die verschiedenen Elemente der Technik. Neuronal bedeutet in diesem Zusammenhang, dass ein Multilayer-Perzeptron, eine ältere neuronale Netzwerkarchitektur, zur Darstellung des Bildes verwendet wird. Strahlung bezieht sich auf die Tatsache, dass dieses neuronale Netzwerk die Helligkeit und Farbe von Lichtstrahlen aus verschiedenen Perspektiven modelliert. Feld ist ein mathematischer Begriff, der ein Modell zur Umwandlung verschiedener Eingaben in Ausgaben unter Verwendung einer bestimmten Struktur beschreibt.
NeRFs funktionieren anders als andere Deep-Learning-Techniken, da eine Reihe von Bildern verwendet wird, um ein einzelnes vollständig verbundenes neuronales Netz zu trainieren, das nur zur Erzeugung neuer Ansichten dieses einen Objekts verwendet werden kann. Im Vergleich dazu beginnt Deep Learning mit der Verwendung von gekennzeichneten Daten, um das neuronale Netz zu trainieren, das geeignete Antworten für ähnliche Datentypen liefern kann.
Der eigentliche Betrieb des neuronalen Netzwerks verwendet die physische 3D-Position und die 2D-Richtung (links-rechts und oben-unten), auf die die simulierte Kamera zeigt, als Eingabe und generiert dann eine Antwort als Farbe und Dichte für jedes Pixel im Bild. Dies spiegelt wider, wie Lichtstrahlen von Objekten aus dieser Ansicht im Raum abprallen.

Training neuronaler Strahlungsfelder
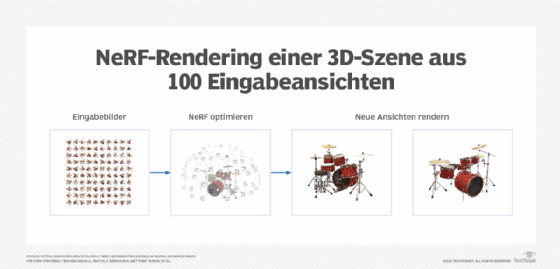
NeRFs werden anhand von Bildern eines Objekts oder einer Szene trainiert, die aus verschiedenen Blickwinkeln aufgenommen wurden. Der Trainingsalgorithmus berechnet dann die relative Position, aus der jedes Bild aufgenommen wurde, und verwendet diese Daten, um die Gewichte auf den Knoten des neuronalen Netzwerks anzupassen, bis ihre Ausgabe mit diesen Bildern übereinstimmt.
Hier ist der Prozess im Detail:
- Der Trainingsprozess beginnt mit einer Sammlung von Bildern eines einzelnen Objekts oder einer Szene, die aus verschiedenen Perspektiven aufgenommen wurden, idealerweise von derselben Kamera. Im allerersten Schritt berechnet ein Algorithmus für die Computerfotografie die Position und Richtung der Kamera für jedes Foto in der Fotosammlung.
- Die Informationen aus den Bildern und dem Standort werden dann zum Training des neuronalen Netzwerks verwendet. Der Unterschied zwischen den Pixeln in diesen Bildern und den erwarteten Ergebnissen wird zur Abstimmung der Gewichte des neuronalen Netzwerks verwendet. Der Vorgang wird etwa 200.000-mal wiederholt, und das Netzwerk konvergiert zu einem brauchbaren NeRF. Die ersten Versionen dauerten Tage – aber wie bereits erwähnt, ermöglichen die jüngsten Nvidia-Optimierungen, dass das Ganze in Sekunden parallel abläuft.
- Es gibt noch einen weiteren Schritt, den die NeRF-Entwickler noch zu verstehen versuchen. Als die Forscher zum ersten Mal mit NeRFs experimentierten, sahen die Bilder aus wie glatte, verschwommene Kleckse, denen die reiche Textur natürlicher Objekte fehlte. Also fügten sie den Strahlen ein wenig digitales Rauschen hinzu, um die Fähigkeit des NeRF zu verbessern, feinere Texturen zu erfassen. Dieses frühe Rauschen bestand aus relativ einfachen Kosinus- und Sinuswellen, während spätere Versionen auf Fourier-Transformationen umstellten, um bessere Ergebnisse zu erzielen. Durch die Anpassung dieses Rauschpegels lässt sich die gewünschte Auflösung einstellen. Ist der Pegel zu niedrig, wirkt die Szene glatt und verwaschen, ist er zu hoch, wirkt sie pixelig. Während die meisten Forscher bei der Fourier-Transformation blieben, ging Nvidia mit einer neuen Kodierungstechnik namens Multi-Resolution-Hash-Kodierung noch einen Schritt weiter, die als entscheidender Faktor für die Erzielung überlegener Ergebnisse gilt.
Erstellen Sie Ihr eigenes NeRF
Laden Sie hier den NeRF-Code herunter, um ihn auf Ihrem Windows- oder Linux-System auszuführen.
Mit der Luma AI-App können Sie ein NeRF auf einem iPhone erstellen.
Was sind die Grenzen neuronaler Strahlungsfelder?
In den Anfangstagen benötigten NeRFs viel Rechenleistung, viele Bilder und waren nicht einfach zu trainieren. Heute sind die Rechenleistung und das Training weniger problematisch, aber es werden immer noch viele Bilder benötigt. Weitere Herausforderungen bei NeRFs sind Geschwindigkeit, Bearbeitbarkeit und Kombinierbarkeit:
- Zeitintensiv, aber immer weniger. Was die Geschwindigkeit betrifft, so erfordert das Training eines NeRF Hunderttausende von Trainingsrunden. Frühe Versionen dauerten mehrere Tage auf einer einzigen GPU. Nvidia hat jedoch einen Weg aufgezeigt, diese Herausforderung durch effizientere Parallelisierung und Optimierung zu bewältigen, wodurch ein neues NeRF in Dutzenden von Sekunden generiert und neue Ansichten in Dutzenden von Millisekunden gerendert werden können.
- Die Bearbeitung ist eine Herausforderung, wird aber einfacher. Die Herausforderung der Bearbeitbarkeit ist etwas kniffliger. Ein NeRF erfasst und sammelt verschiedene Ansichten von Objekten in einem neuronalen Netzwerk. Dies ist viel weniger intuitiv zu bearbeiten als andere Arten von 3D-Formaten, wie zum Beispiel 3D-Netze, die die Oberfläche von Objekten darstellen, oder Voxel – 3D-Pixel –, die ihre 3D-Struktur darstellen. Googles Arbeit an NeRF in the Wild hat Möglichkeiten aufgezeigt, wie Farbe und Beleuchtung verändert und sogar unerwünschte Objekte, die in einigen Bildern erscheinen, entfernt werden können. So kann die Technik beispielsweise Busse und Touristen aus Bildern des Brandenburger Tors in Berlin entfernen, die von mehreren Personen aufgenommen wurden.
- Die Kombinierbarkeit bleibt eine Hürde. Die Herausforderung der Kombinierbarkeit besteht darin, dass Forscher bisher keine einfache Möglichkeit gefunden haben, mehrere NeRFs zu größeren Szenen zusammenzufügen. Dies kann in bestimmten Anwendungsfällen schwierig sein, zum Beispiel beim Rendern simulierter Fabriklayouts, die aus NeRFs einzelner Ausrüstungsgegenstände bestehen, oder beim Erstellen virtueller Welten, die NeRFs verschiedener Gebäude kombinieren.
Erfahren Sie mehr über Künstliche Intelligenz (KI) und Machine Learning (ML)
-
![]()
Generative Modelle: VAE, GAN, Diffusion, Transformer, NeRF
Von: Chris Tozzi
-
![]()
Convolutional versus Recurrent Neural Networks: ein Vergleich
Von: David Petersson
-
![]()
Spatial Computing (Räumliche Datenverarbeitung)
Von: Alexander Gillis
-
![]()
Was generative KI und Large Language Models unterscheidet
Von: Olivia Wisbey



