
Alexander - stock.adobe.com
GAN versus Transformer: wie unterscheiden sich die Modelle?
Was sind die Unterschiede zwischen Generative Adversarial Networks (GAN) und Transformer-Modellen? Erfahren Sie, was beide Techniken auszeichnet und wofür sie sich einsetzen lassen.

Generative Adversarial Networks (GAN) sind vielversprechende Werkzeuge zur Erzeugung von Medien. Sie können beispielsweise realistische Bilder und Stimmen, Videos und 3D-Formen sowie Arzneimittelmoleküle generieren. Sie können aber auch dazu verwendet werden, Bilder auf eine höhere Auflösung zu skalieren, einem vorhandenen Bild einen neuen Stil zu verleihen und das Layout in der Architektur zu optimeren. Sie waren zudem eine der beliebtesten generativen KI-Techniken, bis vor einigen Jahren Transformer eingeführt wurden.
Transformer sind eine grundlegende Technologie, die vielen Fortschritten bei Large Language Models (LLM) zugrunde liegt, wie zum Beispiel Generative Pre-Trained Transformer (GPT). Sie werden nun auch in multimodalen KI-Anwendungen eingesetzt, wie zum Beispiel in großen Bildverarbeitungsmodellen, die in der Lage sind, so unterschiedliche Inhalte wie Text, Bilder, Audio und Roboteranweisungen über zahlreiche Medientypen hinweg effizienter zu korrelieren als Techniken wie GANs.
GANs und Transformer können auch auf verschiedene Weise kombiniert werden, um Inhalte aus einer Eingabe zu generieren, Zielanpassungen an vorhandene Inhalte vorzunehmen oder Inhalte zu interpretieren.
Lassen Sie uns die Anfänge der einzelnen Techniken, ihre Anwendungsfälle und die Art und Weise, wie Forscher die beiden Techniken in verschiedenen Transformer-GAN-Kombinationen kombinieren, untersuchen.
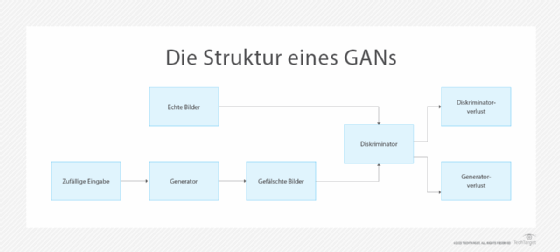
Wie sieht eine GAN-Architektur aus?
GANs wurden 2014 von Ian Goodfellow und Mitarbeitern eingeführt, um realistisch aussehende Zahlen und Gesichter zu generieren. Sie kombinieren die folgenden beiden neuronalen Netze:
- Ein Generator, der in der Regel ein Convolutional Neural Network (CNN) ist, welches Inhalte auf der Grundlage einer Text- oder Bildanweisung erstellt.
- Ein Diskriminator, in der Regel ein Deconvolutional Neural Network (DNN), das authentische von gefälschten Bildern unterscheidet.
„Vor GANs wurde die Bildverarbeitung hauptsächlich mit CNNs durchgeführt, die Merkmale auf niedrigerer Ebene eines Bildes, wie Kanten und Farbe, und Merkmale auf höherer Ebene, die ganze Objekte darstellen, erfassten“, erläutert Adrian Zidaritz, Gründer der gemeinnützigen Organisation Stronger Democracy through Artificial Intelligence. Die Neuartigkeit der GAN-Architektur ergab sich aus ihrem gegensätzlichen Ansatz, bei dem ein neuronales Netzwerk generierte Bilder vorschlägt, während das andere sie ablehnt, wenn sie den authentischen Bildern aus einem bestimmten Datensatz nicht nahe kommen.
Heute erforschen Wissenschaftler Möglichkeiten, andere neuronale Netzwerkmodelle zu verwenden, darunter auch Transformer.
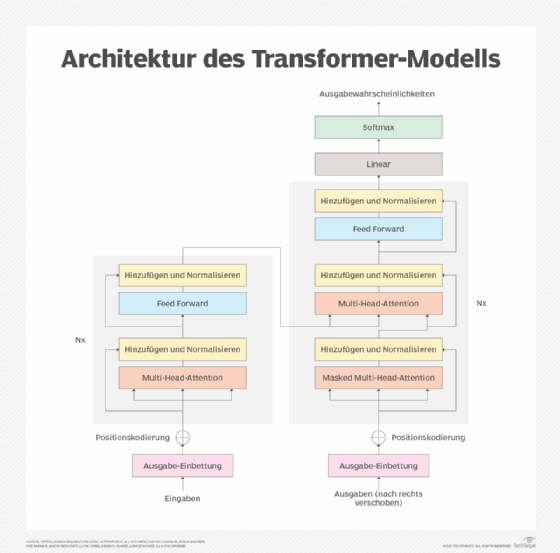
Wie sieht eine Transformer-Architektur aus?
Transformer wurden 2017 von einem Team von Google-Forschern vorgestellt, die einen effizienteren Übersetzer entwickeln wollten. In einem Artikel mit dem Titel Attention Is All You Need stellten die Forscher eine neue Technik vor, mit der die Bedeutung von Wörtern anhand der Art und Weise, wie sie andere Wörter in Phrasen, Sätzen und Aufsätzen charakterisieren, erkannt werden kann.
Frühere Tools zur Textinterpretation verwendeten häufig ein neuronales Netz, um Wörter mithilfe eines zuvor erstellten Wörterbuchs in Vektoren zu übersetzen, und ein anderes neuronales Netz, um eine Textsequenz zu verarbeiten, wie zum Beispiel ein rekurrentes neuronales Netz (RNN). Im Gegensatz dazu lernen Transformer im Wesentlichen, die Bedeutung von Wörtern direkt aus der Verarbeitung großer Mengen ungelabelter Texte zu interpretieren.
Der gleiche Ansatz kann verwendet werden, um Muster in anderen Arten von Daten zu identifizieren, wie zum Beispiel Proteinsequenzen, chemische Strukturen, Computercode und IoT-Datenströme. Auf diese Weise können Forscher die LLMs skalieren, die die jüngsten Fortschritte – und die Bekanntheit – in diesem Bereich vorantreiben. Transformer können auch Beziehungen zwischen Wörtern finden, die weit voneinander entfernt sind, was mit RNNs nicht möglich war.
„Kleine Bildausschnitte können auch durch den Kontext des gesamten Bildes definiert werden, in dem sie erscheinen“, sagt Zidaritz. Die Idee der Selbstaufmerksamkeit in der Verarbeitung natürlicher Sprache wird zur Selbstähnlichkeit in der Computer Vision.
Transformer spielen auch eine wesentliche Rolle bei der Entwicklung multimodaler KI, die mehrere Datenmodalitäten, darunter Text-, Audio-, Video- und Sensordaten, kombiniert. In diesen Fällen kann der Aufmerksamkeitsmechanismus Beziehungen und Verbindungen über mehrere Datenmodalitäten hinweg finden.
GAN versus Transformer: Die besten Anwendungsfälle für jedes Modell
GANs sind laut Richard Searle, Chief AI Officer bei Fortanix, flexibler in ihrem potenziellen Anwendungsbereich. Sie sind auch nützlich, wenn unausgewogene Daten, wie zum Beispiel eine geringe Anzahl positiver Fälle im Vergleich zur Menge negativer Fälle, zu zahlreichen falsch-positiven Klassifizierungen führen können. Daher hat sich das kontradiktorische Lernen in Anwendungsfällen als vielversprechend erwiesen, in denen es nur begrenzte Trainingsdaten für Diskriminierungsaufgaben gibt, oder bei der Betrugserkennung, bei der nur eine geringe Anzahl von Transaktionen im Vergleich zu häufigeren Transaktionen einen Betrug darstellen könnte. In einem Betrugsszenario beispielsweise fügen Hacker ständig neue Eingaben ein, um Betrugserkennungsalgorithmen zu täuschen. GANs sind in der Regel besser in der Lage, sich an diese Art von Techniken anzupassen und sich vor ihnen zu schützen.
„Transformer werden in der Regel dort eingesetzt, wo sequenzielle Input-Output-Beziehungen abgeleitet werden müssen“, sagt Searle, und die Anzahl der möglichen Merkmalskombinationen erfordert eine gezielte Aufmerksamkeit, um einen lokalen Kontext zu schaffen. Aus diesem Grund haben sich Transformer in NLP-Anwendungen durchgesetzt, da sie Inhalte beliebiger Länge verarbeiten können, zum Beispiel Phrasen oder ganze Dokumente. Transformer sind auch gut darin, den nächsten Schritt in Anwendungen wie Spielen vorzuschlagen, bei denen eine Reihe potenzieller Antworten im Hinblick auf die bedingte Abfolge von Eingaben bewertet werden muss.
Eine Einschränkung bei Transformer-Modellen besteht darin, dass sie nicht so rechen-, speicher- oder dateneffizient sind wie GANs. Im Vergleich zu GANs benötigen Transformer-Modelle wesentlich mehr IT-Ressourcen für das Training und den Betrieb, was als Inferenz bezeichnet wird. Daher sind GANs eine bessere Option für die Generierung synthetischer Daten auf der Grundlage vorhandener Datensätze.
Es wird auch aktiv daran geforscht, GANs und Transformer zu sogenannten GANsformern zu kombinieren. Die Idee besteht darin, einen Transformer zu verwenden, um eine Aufmerksamkeitsreferenz bereitzustellen, damit der Generator den Kontext stärker nutzen kann, um den Inhalt zu verbessern.
„Die Intention hinter GANsformern ist, dass die menschliche Aufmerksamkeit auf den spezifischen lokalen Merkmalen eines Objekts von Interesse basiert, zusätzlich zu den latenten globalen Merkmalen“, erklärt Searle. Die daraus resultierenden verbesserten Darstellungen simulieren eher sowohl die globalen als auch die lokalen Merkmale, die ein Mensch in einem authentischen Beispiel wahrnehmen könnte, wie zum Beispiel ein realistisches Gesicht oder computergeneriertes Audio, das mit dem Ton und Rhythmus einer menschlichen Stimme übereinstimmt.
GANsformer können auch dabei unterstützen, sprachliche Konzepte bestimmten Bereichen von Anpassungen oder Arten von Anpassungen an Fotos, Videos oder 3D-Modellen zuzuordnen. Darüber hinaus können sie dazu beitragen, Details in generierten Bildern zu ergänzen oder die Darstellung zu verbessern. So können sie beispielsweise sicherstellen, dass Menschen fünf Finger haben, im Gegensatz zu der unterschiedlichen Anzahl von Fingern, die häufig in vielen Deepfakes zu finden ist. Sie könnten auch lokale Merkmale ausfüllen, um bessere Deepfakes zu erstellen, wie zum Beispiel die subtilen Farbveränderungen der Hauttöne, die mit einer erhöhten Durchblutung einhergehen und von Menschen nicht bemerkt werden, aber zur Erkennung gefälschter Videoinhalte verwendet werden.
Sind Transformer stärker als GANs?
Transformer werden dank ihrer Rolle in beliebten Tools wie ChatGPT und ihrer Unterstützung für multimodale KI immer bekannter. Aber Transformer werden GANs nicht unbedingt für alle Anwendungen ersetzen.
Searle geht davon aus, dass es zu einer stärkeren Integration kommen wird, um Text-, Sprach- und Bilddaten mit mehr Realismus zu erstellen. „Dies kann wünschenswert sein, wenn ein verbesserter kontextbezogener Realismus oder eine flüssigere Mensch-Maschine-Interaktion oder digitale Inhalte das Benutzererlebnis verbessern würden“, sagt er. Beispielsweise könnten GANsformer in der Lage sein, synthetische Daten zu generieren, die den Turing-Test bestehen, wenn sie sowohl einem menschlichen Benutzer als auch einem geschulten maschinellen Prüfer vorgelegt werden. Bei Textantworten, wie sie beispielsweise von einem GPT-System geliefert werden, könnte die Einbeziehung von idiosynkratischen Fehlern oder stilistischen Merkmalen den wahren Ursprung einer von einer KI abgeleiteten Ausgabe verschleiern.
Umgekehrt kann ein höherer Realismus problematisch sein, wenn Deepfakes für Cyberangriffe, zur Schädigung von Unternehmen oder zur Verbreitung von Fake News eingesetzt werden. In diesen Fällen könnten GANsformer bessere Filter zur Erkennung von Deepfakes bereitstellen.
„Durch den Einsatz von kontradiktorischem Training und kontextbezogener Bewertung können KI-Systeme entstehen, die in der Lage sind, die Sicherheit zu erhöhen, Inhalte besser zu filtern und sich gegen Angriffe durch generative Botnets zu verteidigen“, so Searle.
Zidaritz ist jedoch der Ansicht, dass Transformer GANs in vielen Anwendungsfällen möglicherweise verdrängen können, da sie sich einfacher auf Text und Bilder anwenden lassen. „Es werden weiterhin neue GANs entwickelt werden, aber ihre Anwendungsmöglichkeiten werden begrenzter sein als die von GPTs“, sagt er. “Es ist auch wahrscheinlich, dass wir mehr GAN-ähnliche Transformer und Transformer -ähnliche GANs sehen werden, bei denen der Transformer mit seinem Selbstaufmerksamkeits- oder Selbstähnlichkeitsmechanismus im Mittelpunkt stehen wird.“
Es ist wichtig zu beachten, dass es wesentlich mehr Forschung und Entwicklung zu multimodalen LLMs gegeben hat, die manchmal Ergebnisse bei der Inhaltsgenerierung erzielen können, die denen von GANs ähneln. Sie erleichtern auch die Umsetzung menschlicher Absichten in Ergebnisse. Sie sind zwar möglicherweise nicht so recheneffizient wie GANs, aber deutlich höhere Investitionen in die LLM-Forschung schließen diese Lücke.
Andere vielversprechende maschinelle Lerntechniken für generative Modelle beginnen, ausgereift zu werden. Sowohl Variational Autoencoder (VAE) als auch Diffusionsmethoden können auf viele bestehende GAN-Anwendungsfälle angewendet werden. Beispielsweise spielen sowohl VAE als auch Diffusion eine wichtige Rolle in der Cosmos-Plattform von Nvidia für die physische KI-Simulation.





