Warum NVMe und KI-Anwendungen optimal zusammenpassen
NVMe wird wegen seiner Geschwindigkeit und der Zahl der unterstützten Warteschlangen zum Standard-Storage-Medium innerhalb von Umgebungen, in denen KI-Algorithmen ablaufen.
Für KI (künstliche Intelligenz) und ML (Machine Learning, maschinelles Lernen) wurden lange traditionelle Rechnerarchitekturen und Storage-Technologien verwendet. Aber das ändert sich gerade. Heutige AI- und ML-Systeme verarbeiten Daten sehr viel schneller als ihrer Vorgänger. Dafür setzen sie GPUs (Graphical Processing Units), FPGAs (feldprogrammierbare Logikbausteine) und ASICs (anwendungsspezifische Schaltkreise) ein.
Inzwischen verwendet man immer größere Datensätze, um solche intelligenten Systeme zu trainieren. Das steigert die Ansprüche an die Hardware, weshalb Anwender sich hinsichtlich des verwendeten SpeichersNVMe zuwenden, um AI-Algorithmen zu verarbeiten.
NVMe bietet als Schnittstelle mehr Bandbreite und weniger Latenz als SAS und SATA. Das bedeutet Maximalleistung für anspruchsvolle Workloads. ML-Algorithmen zum Beispiel werden mit Millionen Beispieldaten angelernt, damit sie später richtige Entscheidungen bezüglich bislang unbekannter Daten treffen können.
„NVMe ist heute keine avantgardistische Technologie mehr wie am Anfang dieser Dekade, sondern im Jahr 2019 die wichtigste Storage-Option für KI“, sagt Jason Echols, Senior Technical Marketing Manager bei Micron Technology, einem Hersteller von NVMe-SSDs.
Flash ist bereits heute eine Schlüssel-Komponente von KI-Plattformen, die Hochleistung und Scale-out-Storage mit GPU-beschleunigtem Rechnen kombinieren.
„Traditionelle rotierende Festplatten haben Zugriffszeiten, die dreimal so lang sind wie die aktueller NVMe-Technologie“, sagt Scott Schweitzer, Direktor und Technologiepromotor bei Solarflare Communications. Das Unternehmen bietet Technologien für die Beschleunigung von Cloud-Datacenter-Applikationen und elektronischen Handelsplattformen an.
Traditionelles Storage wurde für Leseköpfe entwickelt, die seriell von einer rotierenden Platte lesen, erklärt er. „Deren Controller haben nur eine Handvoll Warteschlangen, oft nur so viele, wie die Disk Leseköpfe hat“, erläutert er. NVMe-Geräte dagegen bewältigen 64.000 Warteschlangen. Also können sie 64.000 parallele Datenanfragen bearbeiten.
Schneller ist besser.
Flash ist bereits heute eine Schlüsselkomponente von KI-Plattformen, die Hochleistung und Scale-out-Storage mit GPU-beschleunigtem Rechnen kombinieren. Das soll I/O-Engpässe beseitigen und mehr neue Erkenntnisse durch KI-Algorithmen befördern, sagt Matthew Hausmann, Produktmanager AI und Analytics bei Dell EMC. „Schneller ist immer besser. Deshalb ist NVMe der natürliche nächste Schritt für diese Lösungen. Denn die Technologie bringt zusätzliche Leistung und kommt näher an Echtzeit heran.“
Schweitzer erwartet, dass NVMe traditionelles Storage in KI-Umgebungen ersetzen wird. KI-Anwendungen brauchen häufig enorme Datensätze. Da Anwendungen immer mehr Leistung brauchen, wird das Warten auf die Disk-Subsysteme unweigerlich zum verzögernden Faktor der gesamten Computing-Umgebung.
„Noch vor wenigen Jahren hat die Netzwerkleistung die Gesamtleistung der Systeme begrenzt“, beobachtet er. „Mit dem Übergang auf 10 und dann 25 GbE, schon bald 100 und in Zukunft 400 GbE, kommt das Netz in riesigen Schritten der Zugriffszeit des lokalen Speichers nahe.“
KI-Applikationen, die auf GPU-basierten Systemen laufen, können mit NVMe-Storage nahezu beliebig dimensionierte GPU-Farmen schneller mit Daten versorgen als traditionelle Storage-Technologien“, sagt Kirill Shoikhet, Chefarchitekt bei Excelero, einem Anbieter von verteiltem Block-Storage. „Moderne GPUs, die für KI- und ML-Applikationen verwendet werden, haben einen erstaunlichen Appetit auf Daten. Sie fressen bis zu 16 Gbps pro GPU“, stellt er fest. „Dagegen mit langsamer Storage anzutreten oder zeitkonsumierend Daten hin und her zu kopieren, verschwendet die teuerste vorhandene Ressource.“
Einsatzszenario: NVMe-gestützte KI
NVMe funktioniert in bestimmten KI-Einsatzszenarien besonders gut. Beispiele sind das Training eines ML-Modells und die Prüfpunkte, an denen vom laufenden Trainingsdurchgängen Backup-Snapshots gezogen werden. ML besteht aus zwei Phasen: In der ersten wird das Modell auf Basis der aus einem Datensatz generierten Erkenntnisse trainiert. In der zweiten wird das Modell auf neue Daten angewandt. „Ein Modell zu trainieren ist extrem ressourcenintensiv“, erklärt Shoikhet. „Die Hardware, die in dieser Phase eingesetzt wird – normalerweise Hochleistungs-GPUs oder spezielle SoCs (System on a Chip) sind teuer im Einkauf und in der Nutzung. Deshalb sollten sie ständig laufen.“
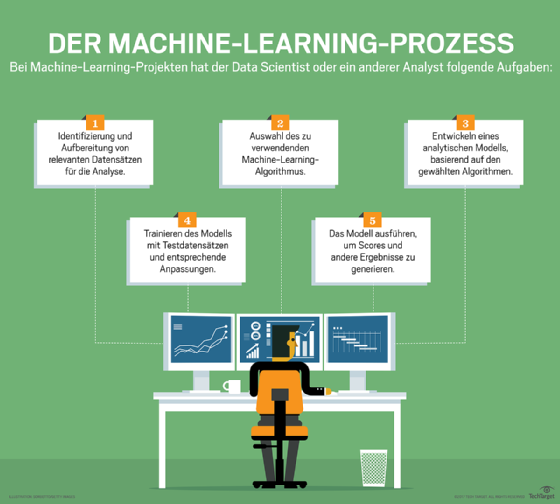
Abbildung 1: Der Machine-Learning-Prozess im Überblick
Moderne Datensätze, die für das Training von ML-Modellen verwendet werden, können sehr voluminös sein. MRI-Scans beispielsweise umfassen pro Stück leicht mehrere Terabytes, und für das Anlernen eines Modells braucht man unter Umständen Hunderte oder Tausende Bilder.
„Auch wenn das Training selbst auf dem RAM läuft, sollte der Speicher aus nichtflüchtigem Storage bestehen“, betont Shoikhet. Alte Trainingsdaten sollten so schnell wie möglich aus dem RAM verschwinden und neuen Daten Platz machen, damit die GPUs ununterbrochen zu tun haben. Das heißt laut Shoikhet, dass die Latenz ebenfalls gering sein muss. Für diesen Applikationstyp ist NVMe das einzige Protokoll, das sowohl hohe Bandbreite als auch niedrige Latenz bietet.
Auch für die Definition von Prüfpunkten ist NVMe-Technologie nützlich. „Wenn ein Trainingsprozess lange dauert, kann das System einen Snaphsot des Memory in nichtflüchtiges Storage ziehen, um einen Neustart von diesem Snapshot zu ermöglichen, falls das System abstürzt“, erklärt Shoikhet. „NVMe-Storage eignet sich für solche Aufgaben sehr gut.“
Schwachstellen und wie man sie vermeidet
Anwender sollten das Storage-I/O-Profil einer KI-Applikation vollständig verstanden haben, bevor sie die jeweils passende NVMe-SSD für den spezifischen Bedarf auswählen. „Manche AI-Umgebungen, insbesondere fürs Training, sind sehr lesezentriert. Das bedeutet, dass man Kosten senken und die Leistung erhöhen kann, ohne zu viel auszugeben“, erklärt Echols.
Hausmann empfiehlt, grundsätzlich keine proprietären NVMe-Storage-Technologien für die Verarbeitung von KI-Algorithmen einzusetzen. Besser seien NVMe-Produkte, die in bekannten und bewährten Enterprise-Produkten stecken. „Auf dem Papier mag das einige Nanosekunden kosten. Doch es bedeutet Lichtjahre Vorsprung, wenn das System einfach läuft und auch noch in sechs Monaten unterstützt wird.“