
Laurent - stock.adobe.com
Generative KI verursacht neue juristische Herausforderungen
Vor 20 Jahren wurde Napster aus urheberrechtlichen Gründen verboten. Mehrere Gerichtsverfahren werfen die Frage auf, ob einige KI-Anbieter vor einem ähnlichen Problem stehen.

Die Existenz von generativer künstlicher Intelligenz (KI) ist nicht mehr übersehen. Von ChatGPT bis hin zu Bildergeneratoren wie Stable Diffusion hat sich die Branche aus dem Nichts heraus zu einer globalen Industrie gemausert. Aber nicht alle sind glücklich. Im Januar 2023 leitete das Bildlizenzierungsunternehmen Getty Images ein Gerichtsverfahren gegen die Eigentümer von Stable Diffusion ein, da diese aus ihrer Sicht gegen das Urheberrecht verstoßen haben.
Dies ist nur einer von immer mehr Fällen, die über die Zukunft der Technologie entscheiden können, darunter auch Klagen gegen die Bild-KI Midjourney und das von Microsoft unterstützte Flaggschiff OpenAI.
Diese juristischen Auseinandersetzungen betreffen jedoch nicht nur die Zukunft der generativen KI, sondern können sich auf die gesamte Zukunft der KI, die Erstellung von Inhalten und die Möglichkeit der Kontrolle persönlicher Daten auswirken.
Die Gründe für das Gerichtsverfahren von Getty Images sind auf den ersten Blick einfach. Getty Images erhebt als Bildlizenzierungsplattform eine Gebühr für den Zugang zu Bildern und deren Nutzung. Dieses System stellt ein großes Problem für generative KI-Systeme wie ChatGPT oder Stable Diffusion dar, die auf massenhaftes Datensammeln angewiesen sind, um ihre Systeme für die Beantwortung von Anfragen zu trainieren.
„Das Training dieser generativen KI-Modelle erfordert riesige Datenmengen“, sagt Laura Houston, Expertin für Urheberrecht und Partnerin bei der Anwaltskanzlei Slaughter and May. „Bei Text-Bild-Modellen müssen beispielsweise Hunderte von Millionen von Datenpunkten eingespeist werden, um dem Modell beizubringen, statistische Beziehungen zwischen den Wörtern und Bildern zu finden.“
Einfach ausgedrückt: Wenn eine künstliche Intelligenz herausfinden will, wie man ein Bild von zum Beispiel einem Huhn mit Zylinder erstellt, muss sie so viele Bilder von Hühnern und Zylindern studieren, wie sie kann. Die schiere Menge der Daten, die es braucht, um diese Fähigkeit zu erlernen, macht es unmöglich, die urheberrechtlich geschützten von den nicht urheberrechtlich geschützten Bildern sinnvoll zu trennen.
„Es besteht das Risiko der Verletzung geistigen Eigentums, das sich aus der Verwendung dieser Daten zum Erlernen des KI-Modells ergibt“, sagt sie. „Aber es stellt sich auch die Frage, was das KI-Modell als Ergebnis generiert und ob aufgrund der Daten, mit denen es trainiert wurde, die Ausgabe des Modells das geistige Eigentum der Eingabedaten verletzt.“
Das alles ist nicht nur eine intellektuelle Übung. Das Urheberrecht ist die Grundlage dafür, dass Künstler und Urheber von Inhalten ihre Werke schützen und kontrollieren können und somit Geld mit ihnen verdienen. Wenn die generative KI in der Lage ist, dieses Recht zu durchbrechen und ihre Arbeit zu nutzen, um ihre Systeme zu trainieren, kann sie davon profitieren und der Kulturindustrie weltweit schaden.
Aber die rechtlichen und moralischen Fragen hören nicht bei den Urheberrechtsgesetzen auf. Generative KI und große Sprachmodelle geraten zunehmend auch in die Schusslinie der Datenschutzbehörden. Die italienische Datenaufsichtsbehörde hat dem auf OpenAI basierenden Chatbot Replika bereits das Sammeln von Daten im Land untersagt.
„Öffentlich zugängliche Daten sind nach der EU-DSGVO und anderen Datenschutzgesetzen immer noch personenbezogene Daten, für deren Verarbeitung man also eine Rechtsgrundlage braucht“, sagt Datenschutzexperte Robert Bateman. „Das Problem ist, dass ich nicht weiß, inwieweit diese Unternehmen darüber nachgedacht haben... Ich denke, das ist eine Art rechtliche Zeitbombe.“
Die Verstöße gegen den Schutz personenbezogener Daten sind oft seltsam. Letzten Monat fand der Financial-Times-Journalist Dave Lee heraus, dass ChatGPT seine Nummer des Messenger-Dienstes Signal (die er auf seinem Twitter-Konto gepostet hatte) als eigene Nummer des Chatbots herausgab, und wurde daraufhin mit zufälligen Nachrichten überschwemmt. Laut Bateman fallen selbst solche öffentlich geposteten Daten unter die Datenschutzgesetze.
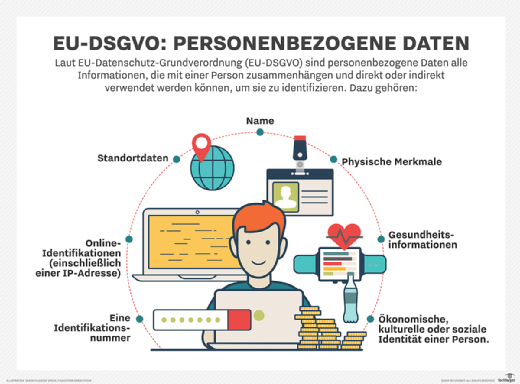
„Es gibt so etwas wie eine kontextbezogene Privatsphäre“, sagt er. „Man kann seine Telefonnummer auf Twitter veröffentlichen und nicht erwarten, dass sie in einer Datenbank in China auftaucht. Dasselbe gilt für Sie, wenn Sie nicht unbedingt erwarten, dass sie von Chatbots ausgegeben wird. Die Datengenauigkeit ist einer der Grundsätze der EU-Datenschutz-Grundverordnung. Sie sind verpflichtet, dafür zu sorgen, dass personenbezogene Daten in Ihren Prozessen korrekt und aktuell sind. Doch große Sprachmodelle funktionieren anscheinend in 20 Prozent der Fälle nicht richtig. Auf dieser Grundlage werden viele ungenaue Informationen über Personen verbreitet.“
Verstöße feststellen
Für den Datenschutz und den Schutz des geistigen Eigentums ist es ein großes Problem, genau zu ermitteln, ob eine generative KI tatsächlich gegen das Gesetz verstoßen hat. Die schiere Menge an Daten, die in diese Systeme eingespeist werden, macht es zu einem Problem, herauszufinden, was problematisch ist und was nicht. Gleichzeitig ist die Ausgabe nie eine absolute Kopie dessen, was eingespeist wurde, was es in den meisten Fällen von Urheberrechtsverletzungen, bei denen es in der Regel um direktes Kopieren geht, etwas schwieriger macht, eine Verletzung nachzuweisen.
An diesem Punkt klaffen große Sprachmodelle wie ChatGPT und generative Bild-KI wie Stable Diffusion auseinander. Verzerrte, von KI generierte Bilder enthalten oft eindeutigere Hinweise auf die Daten, die zu ihrer Erstellung beigetragen haben, als Texte. Im Fall von Getty Images beispielsweise lassen sich viele der Beweisprobleme in diesem Bereich einfach dadurch lösen, dass das eigene Wasserzeichen angeblich auf vielen Bildern von Stable Diffusion auftaucht.
„Ich denke, es ist wahrscheinlich kein Zufall, dass viele dieser ersten rechtlichen Anfechtungen in der Welt der Text-Bild-KI-Modelle auftauchen“, sagt Houston. Es ist auch kein Zufall, dass der Fall im Vereinigten Königreich eingereicht wurde. Im Gegensatz zum Vereinigten Königreich gibt es in den USA eine sogenannte Fair-Use-Verteidigung für Urheberrechtsverletzungen, die den großen KI-Entwicklern entgegenkommt.
Im Vereinigten Königreich gibt es eine spezielle Ausnahmeregelung für Text und Data Mining im Rahmen des Urheberrechts, die jedoch nicht auf die kommerzielle Nutzung dieser Verstöße ausgedehnt ist, wie es bei den derzeitigen generativen KI-Systemen bereits der Fall ist.

Nominell bedeutet das, dass persönliche Daten und Inhalte, die im Vereinigten Königreich erstellt wurden, sicherer sind. Das britische Parlament und das Amt für geistiges Eigentum der Regierung diskutieren bereits darüber, ob dieses Gesetz ausgeweitet werden soll, um den Schutz für die kommerzielle Verwertung von Inhalten anderer Leute aufzuheben.
Letzten Endes müssen Gerichte und politische Entscheidungsträger gleichermaßen entscheiden, ob sie den Urheberrechtsschutz für die Schöpfer von Inhalten (und den Schutz der Privatsphäre für alle) wirtschaftlichen Interessen opfern, die der generative KI-Sektor wahrscheinlich liefern wird.
Personenbezogene Daten
Houston verweist auf den Fall Spotify, bei dem „Rechteinhaber und Technologieunternehmen schließlich eine Einigung erzielen konnten“, aber es gibt einige Komplikationen bei der Ausarbeitung eines ähnlichen Kompromisses. Auch die Zurechnung – eine übliche Lösung in anderen Fällen des geistigen Eigentums – ist ein Problem.
„Ich glaube, das große Problem sind die großen Datenmengen von Bildern oder Texten, die sie verwenden müssen, und ich weiß nicht, wie die ursprünglichen Künstler irgendwo genannt werden können", sagt Chen Zhu, außerordentlicher Professor an der juristischen Fakultät der Universität Birmingham, der sich auf das Recht des geistigen Eigentums spezialisiert hat.
Diejenigen, mit denen Computer Weekly gesprochen hat, bezweifeln außerdem, dass es möglich ist, wenn man nicht einmal sicher ist, dass seine persönlichen Daten gesammelt werden, darum zu bitten, dass sie nur korrekt veröffentlicht werden, geschweige denn sicherzustellen, dass sie nicht verwendet werden, oder dass die Unternehmen manuell mit den Künstlern über die Aufnahme ihrer Werke in die Systeme beraten.
Die meisten Rechtsexperten sind sich einig, dass es mindestens zwei Jahre dauern wird, bis wir in den von Getty Images angestrengten Gerichtsverfahren Fortschritte sehen werden, und bis dahin kann generative KI bereits, wie Bateman es ausdrückte, „zu groß zum Scheitern“ geworden sein.
In der Tat wird der Sektor bereits von einigen großen Finanzunternehmen unterstützt. OpenAI wird beispielsweise von Microsoft gefördert, während Stable Diffusion bereits über 101 Millionen Dollar an Risikokapital aufgebracht hat und nun eine Bewertung von vier Milliarden Dollar anstrebt.
Wie Zhu anmerkt, war Napster ein „Underdog“ der Branche ohne institutionelle Unterstützung oder große Summen an Risikokapital. Er verweist auf Fälle wie den, als Google Millionen von Büchern ohne Genehmigung für eine Online-Bibliothek digital kopierte. Am Ende des langwierigen und kostspieligen Rechtsstreits mit den geschädigten Autoren ging der Tech-Riese als Sieger hervor. „Meiner Beobachtung nach waren Unternehmen wie Google in der Vergangenheit unbesiegbar, wenn es um Urheberrechtsstreitigkeiten ging. Sie haben bisher noch nie verloren“, sagt Zhu.
Der größte Unterschied zwischen dem Napster-Fall und den neuen Fällen, die wahrscheinlich das Ergebnis bestimmen werden, besteht darin, dass die Unternehmen, die diesmal angegriffen werden, Geld haben.






