
bluebay2014 - stock.adobe.com
NoSQL-Datenbanken in der Cloud – ein Vergleich
Mit der Ablösung von Legacy-Anwendungen ist die Überlegung über NoSQL-Datenbanken ungebrochen von Bedeutung. Eine Reminiszenz an einen langjährigen Autor von TechTarget.

Das Aufkommen global skalierbarer Online-Dienste für soziale Netzwerke, Streaming-Inhalte, die Verbreitung von Nachrichten, den Einzelhandel und andere geschäftliche Anwendungen hat die Anforderungen an die Anwendungsinfrastruktur und Softwarearchitekturen erheblich verändert. Eine der wichtigsten Veränderungen betraf die Art und Weise, wie IT-Systeme Daten speichern, organisieren und den Zugriff darauf ermöglichen.
Herkömmliche relationale Datenbank-Managementsysteme (RDBMS, Relational Database Management Systems) wie Oracle Database und SQL Server eignen sich schlecht für Webanwendungen, die eine verteilte, skalierbare Cluster-Infrastruktur erfordern. NoSQL- (Not only SQL-) Datenbanken eignen sich besser für lose gekoppelte Systeme, bei denen Anwendungsdaten und ausführbarer Code über mehrere Rechner und möglicherweise Rechenzentren verteilt sind. Sie können auch Datensätze verarbeiten, die nicht in das starre Schema von SQL-basierten relationalen Datenbanken passen, die am besten mit strukturierten Daten arbeiten.
NoSQL-Anbieter, deren Ursprünge oft in der Open-Source-Gemeinschaft liegen, haben verschiedene Arten von Datenbanken entwickelt, die auf unterschiedliche Daten und Anwendungsfälle ausgerichtet sind. Oracle, Microsoft und andere RDBMS-Anbieter haben schließlich auch NoSQL-Datenbanken entwickelt. Jetzt, da sich der Markt insgesamt in Richtung Cloud-Datenbanken verlagert, hat die Cloud-native Entwicklung Einzug gehalten: NoSQL-Datenbanken sind in der Cloud sowohl für selbst verwaltete IaaS-Bereitstellungen als auch für vom Anbieter verwaltete DBaaS-Bereitstellungen (Database as a Service) weithin verfügbar.
Vor- und Nachteile von NoSQL-Datenbanken
Die Entwicklung von NoSQL-Datenbanken wurde in erster Linie durch Webanwendungen und -dienste vorangetrieben. Daher haben die verschiedenen Arten von NoSQL-Datenbanken einige Vorteile gegenüber RDBMS. Dazu gehören die folgenden:
- die Fähigkeit, eine Vielzahl von Datentypen zu verarbeiten
- höhere Leistung und geringere Latenzzeit bei bestimmten Anwendungen
- Ideal für unstrukturierte und semistrukturierte Daten wie Text, Bilder, Audio und Video
- horizontale Skalierungsmöglichkeiten für große Arbeitslasten und Datenmengen
- gut geeignet für Zeitreihen oder andere Streaming-Daten, wie Ereignisprotokolle und IoT-Daten
- Zugang zu einer Vielzahl von Open-Source- oder Low-Cost-Implementierungen, die in der Anschaffung und im Betrieb kostengünstiger sind als ein komplexes RDBMS
Diese Vorteile sind jedoch in anderer Hinsicht mit Kosten verbunden. So gewährleisten relationale Datenbanksysteme durch das ACID-Modell eine unmittelbarere Datenkonsistenz und -zuverlässigkeit: Atomizität (Granularität), Konsistenz, Isolation und Dauerhaftigkeit. NoSQL-Datenbanken folgen in der Regel dem BASE-Modell: Basisverfügbarkeit, Soft State und eventuell Konsistenz – obwohl einige Lösungen auch das ACID-Modell unterstützen.
Außerdem verfügen die nicht-relationalen Datenbanken nicht immer über integrierte Mechanismen zur Überprüfung der Datenintegrität. In solchen Fällen muss dies in externem Code erfolgen.
Schließlich bieten viele NoSQL-Datenbanken zwar einige SQL-Funktionen, unterstützen aber in der Regel keine komplexen SQL-Operationen, wie zusammengesetzte Select-Anweisungen oder Tabellen-Joins.
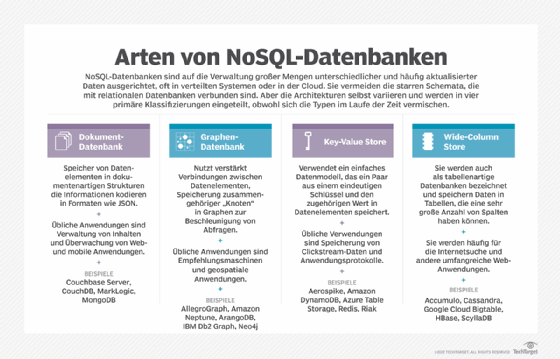
NoSQL-Datenbank-Kategorien
Der richtige Weg, über NoSQL nachzudenken, ist nicht die Auswahl eines bestimmten Datenbanktyps, sondern eher das Nachdenken über eine übergeordnete Kategorie mit mehreren Varianten. Die können sein:
- Schlüssel-Wert-Speicher (Key-Value-Stores). Solch eine Datenbank organisiert Datensätze als eine Folge von Datensätzen, die einen eindeutigen Schlüssel in Verbindung mit einem Datenwert enthalten. Sie verwendet Hash-Tabellen, um die Schlüssel mit Zeigern auf die zugehörigen Werte zu speichern, die ein einzelner Eintrag oder ein komplexes Datenobjekt mit mehreren Elementen sein können. Ein Key-Value-Store ist wie ein Wörterbuch, bei dem jeder Schlüssel einem Wort entspricht und der Wert dessen Bedeutung darstellt.
- In-Memory-Cache. In-Memory-Datenbanken sind eine Variante von Key-Value-Store. Dieser ist so konzipiert, dass er vollständig in den Systemspeicher (Memory) passt. Dadurch wird die Leistung beschleunigt, und Kosten können gesenkt werden. Es entfällt die Notwendigkeit, eine ganze Datenbank zu bearbeiten, nur um eine bestimmte Anwendungsfunktion oder ein bestimmtes Szenario zu bewältigen.
- Dokument-Datenbank. Sie speichert Datenobjekte in Schlüssel-Wert-Paaren und legt sie in dokumentenähnlichen Strukturen ab. Diese können auch Metadaten über den Inhalt enthalten. Manchmal auch als Dokumentenspeicher (Document Store) bezeichnet, kodiert die Datenbank Dokumente typischerweise in JSON, XML, YAML und anderen Textformaten oder binären Varianten wie BSON.
- Suchdatenbank. Eine Suchdatenbank (Search Database) ist eine Dokument-Datenbank, mit der die Dokumentenindizes auf mehrere Knoten verteilt werden können, um eine hohe Skalierbarkeit zu erreichen und die Suche nach bestimmten Einträgen zu beschleunigen.
- Spaltenorientierte Datenbank (Wide-column Store). Bei dieser Technologie werden die Daten nicht nach Zeilen, sondern nach Spalten organisiert. Wie der Name schon sagt, kann eine solche Datenbank Tabellen mit vielen Spalten enthalten. Dadurch kann diese Datenbank sehr große Datensätze verarbeiten. Die Spalten werden in Familien verwandter Daten gruppiert, auf die gemeinsam zugegriffen wird.
- Graphendatenbank. Dieser Datenbanktyp verzichtet auf die übliche Zeilen-Spalten-Struktur und verwendet stattdessen eine graphenähnliche Struktur. Datensätze werden als eine Sammlung von Knoten zu speichern und ihre Beziehungen zueinander hervorgehoben.
- Zeitreihen-Datenbank (Time Series Database, TSDB). Eine TSDB sammelt fortlaufend generierte Daten und speichert sie sukzessive mit Zeitstempeln. Beispiele hierfür sind Börsendaten, Sensordaten und Daten aus IT-Netzwerken. Eine Zeitreihen-Datenbank kann dazu verwendet werden, solche Datensätze zu verfolgen und zu analysieren, die sich im Laufe der Zeit ändern.
Key-Value-Stores, Dokument-Datenbanken, spaltenorientierte Datenbanken und Graphen-Datenbanken sind die vier Hauptkategorien von NoSQL-Datenbanken. Darüber hinaus überarbeiten die Anbieter ihre Produkte zunehmend in die Richtung von Multimodell-Datenbanken. Diese unterstützen dann mit ihren Modulen mehr als eine dieser Kategorien.
Vergleich von NoSQL-Datenbanken
Da die Public-Cloud-Infrastruktur zu einer beliebten Option für die Ausführung von Web-Apps, mobiler Apps und anderer IT-Workloads geworden ist, haben die Hyperscaler – AWS, Microsoft und Google Cloud – eine Vielzahl von NoSQL-Datenbankprodukten und -diensten entwickelt. Diese sind für unterschiedliche Datentypen und Anwendungsfälle geeignet. Während die Details ihrer Produktangebote variieren, sind die verfügbaren Technologien für jeden Typ von NoSQL-Datenbank in der folgenden Tabelle aufgeführt.

Wie die Tabelle zeigt, sind in der Cloud zahlreiche Open-Source- und kommerzielle Produkte für jeden Typ von NoSQL-Datenbanken verfügbar sind. Für DBaaS- (Datenbank-as-a-Service-) Umgebungen können Benutzer zwischen den führenden Cloud-Plattformanbietern – das sind die Hyperscaler und Oracle – und anderen NoSQL-Datenbankanbietern wählen, die ihre Software auf einer oder mehreren dieser Plattformen hosten. Jede Option eines Drittanbieters hat ihre Funktionen und Stärken, die sie für den jeweiligen Benutzer zur besten NoSQL-Option in der Cloud machen können.
Eine weitere wichtige Entscheidung beim Betrieb einer NoSQL-Datenbank in der Cloud ist die Provisionierung, also das Bereitstellungsmodell: Zur Auswahl stehen hier eine private gemanagte Infrastruktur als Service (Private Managed IaaS) oder ein vollständig verwalteter Datenbankdienst. Die Entscheidung hängt davon ab, ob ein Unternehmen ein selbst verwaltetes und hochgradig konfigurierbares und kontrolliertes Datenbanksystem oder eine vom Provider gemanagte DBaaS-Plattform bevorzugt, bei der die Investitionskosten und der laufende Verwaltungsaufwand für die Infrastruktur entfallen.





