
arthead - stock.adobe.com
Hadoop und Spark: wie unterscheiden oder ergänzen sie sich?
Hadoop und Spark unterscheiden sich in Bezug auf Architektur, Leistung, Skalierbarkeit, Kosten und Bereitstellung. Sie bieten unterschiedliche Stärken für moderne Datenpipelines.
Für Laien mag es so aussehen, als sei Hadoop für Spark das, was Pepsi für Coca-Cola ist: ähnliche, weitgehend austauschbare Marken mit einigen subtilen, aber wichtigen Unterschieden.
Hadoop und Spark sind zwei der am häufigsten verwendeten Frameworks für die Verarbeitung großer Datenmengen. Sie können viele der gleichen Anwendungsfälle und Herausforderungen bewältigen, unterscheiden sich jedoch in ihren Designprioritäten.
Wenn man sich die Details genauer ansieht, wird deutlich, dass es zwischen Hadoop und Spark wesentliche Unterschiede in der Art und Weise gibt, wie sie Daten verarbeiten. Hadoop ist für die Stapelverarbeitung (Batch-Verarbeitung) und persistente Speicherung optimiert und unterstützt daher eine skalierbare, kostengünstige Datenverwaltung. Spark legt den Schwerpunkt auf In-Memory-Verarbeitung und Echtzeitanalysen und eignet sich daher besser für Workloads mit geringer Latenz.
Manchmal funktionieren Hadoop und Spark am besten, wenn sie zusammen eingesetzt werden. Um das richtige Tool auszuwählen oder zu entscheiden, wann beide zusammen eingesetzt werden sollten, ist es wichtig zu verstehen, wie sich diese Frameworks in Bezug auf Leistung, Skalierbarkeit, Bereitstellung und Kosten unterscheiden.
Batch- versus Stream-Verarbeitung
Bevor wir uns näher mit dem Vergleich von Hadoop und Spark befassen, ist es hilfreich, zwei Kernkonzepte hinter ihrem Design zu definieren.
Batch-Verarbeitung und Stream-Verarbeitung
Ein Team kann Daten entweder in Batches oder in Streams verarbeiten. Bei der Batch-Verarbeitung werden Daten gruppiert und gemeinsam verarbeitet, während bei der Stream-Verarbeitung jedes Datenobjekt sofort nach seinem Eintreffen verarbeitet wird, ohne dass auf die Gruppierung gewartet werden muss. Die Batch-Verarbeitung kann bei großen Datenmengen ressourceneffizienter sein, aber die Stream-Verarbeitung unterstützt die Echtzeitverwaltung, bei der nicht auf die Batch-Verarbeitung gewartet werden muss.
Persistentes Storage und In-Memory
Persistentes Storage, wie zum Beispiel Festplatten, speichert Daten über einen längeren Zeitraum und ist relativ kostengünstig, aber langsam beim Lesen/Schreiben von Daten. In-Memory-Speicher verwendet Hardware wie RAM, um Informationen vorübergehend zu speichern. Dies ermöglicht viel schnellere Zugriffsgeschwindigkeiten, was zu einer besseren Leistung führt. Der Nachteil ist, dass In-Memory-Speichermedien teuer sind und alle im Speicher gespeicherten Daten dauerhaft verloren gehen, wenn der Rechner, auf dem sie gespeichert sind, heruntergefahren wird.
Was ist Apache Hadoop?
Hadoop ist ein Open-Source-Framework für die Verarbeitung großer Datensätze. Unternehmen verwenden es in der Regel für Batch-Workloads und persistentes Storage, obwohl es mit Add-on-Tools auch die Stream-Verarbeitung unterstützen kann. Hadoop arbeitet in erster Linie mit Daten, die auf Festplatten gespeichert sind, kann aber unter bestimmten Umständen auch mit Daten arbeiten, die in flüchtigem Speicher gespeichert sind.
Apache Hadoop entstand 2006 als Open-Source-Alternative zu MapReduce, einem von Google intern verwendeten Framework für verteiltes Rechnen. Hadoop hatte zum Ziel, die Verarbeitung von Big Data zu demokratisieren, indem es jedem Unternehmen ermöglichte, mit sehr großen Datensätzen zu arbeiten, die über Servercluster verteilt sind.
Der Begriff groß ist relativ, wenn es um die Größe eines Datensatzes geht. Es gibt keine Datenverarbeitungsschwelle für die Verwendung von Hadoop. Im Allgemeinen eignet sich Hadoop am besten für Anwendungsfälle, bei denen so viele Daten anfallen, dass sie nicht auf einem einzigen Server gespeichert werden können, sondern auf mehrere Maschinen verteilt werden müssen. Hadoop zeichnet sich in solchen Fällen aus, da es Daten aus einem Servercluster abrufen und parallel verarbeiten kann.

Was ist Apache Spark?
Apache Spark ist ein Open-Source-Framework für die Verarbeitung von Big Data. Es konzentriert sich in erster Linie auf Stream-Verarbeitung und In-Memory-Speicherung. Spark begann 2009 als akademisches Forschungsprojekt an der University of California, Berkeley, und wurde 2010 als Open Source veröffentlicht. Während Hadoop bereits existierte, adressierte Spark Anwendungsfälle für die Verarbeitung großer Datenmengen, in denen Hadoop nicht glänzte, insbesondere solche, die eine sehr schnelle und/oder Echtzeit-Verarbeitung der Daten erforderten.
Wie Hadoop verarbeitet Spark Daten, die über einen Servercluster verteilt sind, und zwar parallel. Es funktioniert mit Daten praktisch jeder Größenordnung.
Ähnlichkeiten zwischen Hadoop und Spark
Sowohl Hadoop als auch Spark beziehen Daten aus einem Servercluster und verarbeiten diese schnell und effizient. Das bedeutet, dass beide Frameworks verschiedene Anwendungsfälle unterstützen können:
- Datenanalyse, bei der Datensätze analysiert werden, um Trends oder Anomalien zu identifizieren.
- Datentransformation, also der Prozess der Konvertierung von Daten von einem Format in ein anderes.
Mittlerweile überschneiden sich die Funktionen von Hadoop und Spark vielfach, da beide so konfiguriert werden können, dass sie Batch- oder Stream-Verarbeitung unterstützen und mit dauerhaft oder im Speicher abgelegten Daten arbeiten. In der Vergangenheit war dies nicht der Fall. Heute haben sich die beiden Frameworks jedoch so weiterentwickelt, dass sie flexibler geworden sind und Unternehmen beide Tools an eine Vielzahl von Workload-Anforderungen anpassen können. Diese sich überschneidenden Funktionen haben die Unterschiede zwischen Hadoop und Spark verwischt.
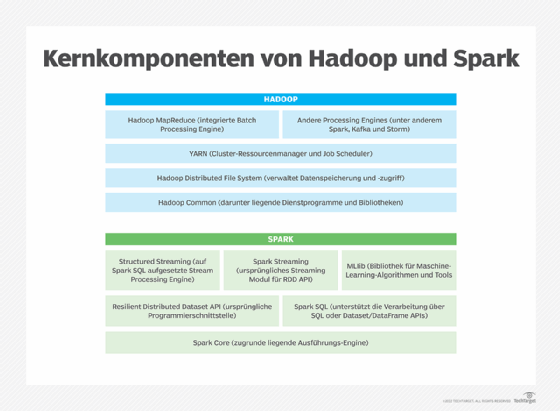
Die wichtigsten Unterschiede zwischen Hadoop und Spark
Obwohl es technisch möglich ist, Hadoop und Spark so zu konfigurieren, dass sie unter vielen Umständen auf die gleiche Weise funktionieren, bleiben sie doch unterschiedlich und eignen sich nach wie vor für unterschiedliche Anwendungsfälle.
Batch- versus Stream-Verarbeitung
Der Schwerpunkt von Hadoop liegt auf der Verarbeitung von Daten in Batches, während Spark für die Stream-Verarbeitung konzipiert ist. Hadoop ist jedoch einfacher zu implementieren als Spark und effizienter bei der Verwendung für Batch-Workloads, während Spark intuitiver für Stream-Anwendungen zu verwenden ist.
Daher entscheiden sich Teams für Hadoop, wenn Daten gesammelt werden, bevor sie analysiert oder transformiert werden können, zum Beispiel bei der Log-Analyse oder der Generierung von Produktempfehlungen auf einer Einzelhandelswebsite, und sie entscheiden sich für Spark, wenn Daten in Echtzeit verarbeitet werden müssen, zum Beispiel für die Erkennung von Anomalien im Bereich Cybersicherheit oder die Betrugserkennung bei der Zahlungsabwicklung.
Persistentes Storage und In-Memory
Hadoop ist für das Lesen/Schreiben von Daten aus persistenten Speichern konzipiert, kann jedoch für den Zugriff auf Daten im Arbeitsspeicher angepasst werden. Die In-Memory-Verarbeitung mit Hadoop erfordert in der Regel die Ausführung von Spark auf einem Hadoop-Cluster oder die Verwendung von Abstraktionen, die das System mit In-Memory-Speicher-Arrays verbinden und es Hadoop als persistenten Speicher präsentieren.
Spark verarbeitet Daten standardmäßig im Arbeitsspeicher, kann aber auch Persistenz- oder Caching-Funktionen nutzen, um Daten abzurufen, die auf der Festplatte gespeichert sind.
Obwohl beide Frameworks mit beiden Datentypen arbeiten können, bedeutet dies nicht, dass sie unter allen Umständen gleich einfach zu implementieren sind. Sie können diese jeweiligen Anwendungsfälle ohne Add-ons oder Abstraktionen unterstützen. Das bedeutet, dass sie einfacher zu konfigurieren sind, aber auch zu einer besseren Leistung führen, da übermäßige Erweiterungen die für die Ausführung von Hadoop oder Spark erforderlichen Ressourcen erhöhen können, was zu weniger verfügbaren Ressourcen für die eigentliche Datenverarbeitung führt.
Performance
Spark übertrifft Hadoop in der Regel, insbesondere bei Prozessen, die von Streaming und In-Memory-Datenverarbeitung profitieren. Selbst wenn Hadoop für die Verwendung derselben Verarbeitungstechniken konfiguriert ist, kann Spark Informationen in der Regel schneller lesen/schreiben und transformieren.
Daher ist Spark in der Regel die bessere Wahl, wenn Performance Priorität hat.
Skalierbarkeit
Hadoop ist skalierbarer als Spark, da es auf kostengünstigen Servern effizient läuft. Hadoop-Cluster lassen sich in der Regel leichter erweitern, da sie keine umfangreichen Speicherressourcen benötigen, was bedeutet, dass Unternehmen Hadoop in der Regel durch Hinzufügen kostengünstiger Server skalieren können.
Spark ist ebenfalls skalierbar, aber die Skalierung eines Spark-Clusters erfordert das Hinzufügen weiterer speicherintensiver Server, was kostspieliger ist.
Daher lassen sich Leistungssteigerungen in Hadoop einfach durch Hinzufügen weiterer Server erzielen. Bei Spark erschweren praktische Einschränkungen hinsichtlich der Speicherkosten die Vergrößerung des Clusters zur Steigerung der Leistung.
Bereitstellungsoptionen
Hadoop und Spark unterstützen eine flexible Bereitstellung auf den meisten Infrastrukturtypen – einschließlich lokaler Server und Cloud-Server –, sowohl wenn ein Unternehmen Hadoop oder Spark selbst einrichtet und verwaltet als auch bei vollständig verwalteten Cloud-Diensten, die gehostete Versionen von Hadoop und Spark anbieten. Beide Frameworks können auch direkt auf Servern ausgeführt oder über Plattformen wie Kubernetes orchestriert werden.
Die Art und Weise, wie ein Unternehmen Hadoop oder Spark einsetzt, wirkt sich jedoch auf die Leistung aus. Wenn Spark beispielsweise auf Kubernetes ausgeführt wird, können die Stream-Verarbeitungsfunktionen aufgrund der Zeit, die Kubernetes zum Starten einer Spark-Instanz benötigt, unteroptimal funktionieren. Dies ist zwar nur eine Frage von Sekunden, aber dennoch eine Verzögerung. Die Kubernetes-basierte Bereitstellung stellt für Hadoop weniger ein Problem dar, da das Batch-Verarbeitungsmodell von Hadoop keinen Echtzeitstart erfordert.
Kosten
Als Open-Source-Technologien sind Hadoop und Spark kostenlos nutzbar, obwohl für kommerzielle Distributionen möglicherweise Lizenzgebühren anfallen. Ihre Betriebsmodelle können jedoch zusätzliche Kosten verursachen.
Spark ist in der Regel teurer, da es auf In-Memory-Speicher basiert, der kostspieliger ist als festplattenbasierte Alternativen. Aufgrund der höheren Kosten für die Host-Infrastruktur müssen Unternehmen in der Regel mehr für den Betrieb eines Spark-Clusters bezahlen, unabhängig davon, ob sie ihre Server selbst einrichten oder für einen verwalteten, Cloud-basierten Spark-Dienst bezahlen.
Allerdings können die Architektur und die Konfiguration einen großen Einfluss auf die Kosten haben. Ein schlecht abgestimmter Hadoop-Cluster mit unnötigen Knoten oder ineffizienten Datentransformationen kann im Betrieb teurer sein als ein kostenoptimierter Spark-Cluster. Unternehmen sollten ihre Entscheidung auf der Grundlage der Details der jeweiligen Umgebung treffen, anstatt davon auszugehen, dass Hadoop generell kostengünstiger ist als Spark.
Hadoop oder Spark oder Hadoop und Spark?
Welches Framework eignet sich am besten für einen bestimmten Anwendungsfall? Hadoop eignet sich gut für Workloads, bei denen Skalierbarkeit und Kosteneffizienz im Vordergrund stehen. Es funktioniert auch am besten, wenn Daten nicht gestreamt werden müssen, obwohl einige Erweiterungen Hadoop für die Stream-Verarbeitung geeignet machen.
Spark eignet sich hingegen besser, wenn Leistung und geringe Latenz oberste Priorität haben. Spark-Cluster sind in der Regel teurer als Hadoop-Cluster, aber die Fähigkeit von Spark, mit im Arbeitsspeicher abgelegten Daten zu arbeiten, ermöglicht eine schnellere Datenverarbeitung.
Man muss jedoch bedenken, dass sich Hadoop und Spark nicht gegenseitig ausschließen. Viele Unternehmen setzen beide in einer hybriden Konfiguration ein, wobei jedes Framework eine bestimmte Rolle erfüllt:
- Der Basis-Cluster läuft auf Hadoop für die Datenspeicherung und die erste Verarbeitung.
- Spark läuft auf Hadoop und wird bei Bedarf über dessen Ressourcenmanager integriert.
- Hadoop ist für die Datenaufnahme und die erste Verarbeitung zuständig.
- Datenaufgaben oder Pipelines, die eine zusätzliche Verarbeitung erfordern und für die eine hohe Leistung entscheidend ist, können an Spark übergeben werden.
- Die Ergebnisse der von Spark verarbeiteten Jobs können bei Bedarf zur weiteren Verarbeitung an Hadoop zurückgegeben werden.
Mit dieser Konfiguration profitieren Benutzer von der Skalierbarkeit und Kosteneffizienz von Hadoop und haben dennoch Zugriff auf Spark für eine schnellere Verarbeitung.
Ein Beispiel für eine effektive Hybridarchitektur sind Zahlungsabwicklungsvorgänge. In den meisten Fällen können Zahlungsdaten in Stapeln verarbeitet werden, da eine gewisse Verzögerung zwischen der Erfassung der Daten und dem Abschluss der Verarbeitung akzeptabel ist. Im Rahmen der Zahlungsabwicklung möchte ein Unternehmen jedoch möglicherweise betrügerische Zahlungen erkennen, um sie in Echtzeit zu blockieren.
Spark ist für diesen Teil des Zahlungsabwicklungs-Workflows nützlich, da es anomale Zahlungsdaten schneller als Hadoop identifizieren kann. Das Unternehmen kann Hadoop für die meisten Aspekte der Zahlungsabwicklung verwenden, aber Spark zur Betrugserkennung integrieren. Wenn die Workloads eindeutig in die Kategorien fallen, die entweder am besten zu Hadoop oder zu Spark passen, gibt es keinen Grund, beide Lösungen zusammen einzusetzen, da dies unnötige Kosten und Komplexität mit sich bringt.





