Computational Storage vereinfacht Speicheraufgaben am Edge
Edge Computing bringt IT-Ressourcen an den Standort, wo Daten erzeugt werden. Die Entfernung zum Rechenzentrum kann problematisch sein, aber Computational Storage kann hier helfen.
Unglücklicherweise weist das Edge-Modell mehrere Beschränkungen auf. IT-Teams müssen einige Hürden aus dem Weg räumen, um die nötigen Compute- und Storage-Ressourcen für ihre Workloads zur Verfügung zu stellen. Einen der am vielversprechendsten Auswege bietet Computational Storage, bei dem Rechenkapazitäten direkt in Speichersysteme eingebaut werden, um so I/O-Engpässe zu entfernen und Latenzzeiten bei den Anwendungen zu reduzieren. Damit wird es möglich, größere Datenmengen in einer Edge-Umgebung zu verarbeiten.
Computing in Edge-Umgebungen
Computing am Netzwerkrand (Edge) basiert auf einer verteilten Architektur, die Ressourcen für Datenverarbeitung und Speicher vom Rechenzentrum zur Peripherie des Netzwerks verschiebt. In vielen Fällen bedeutet das, dass diese Ressourcen sich dann in einer Zweigstelle oder einem einzelnen Büro befinden. Indem Daten und Anwendungen näher zusammenrücken, kann Edge Computing den Netzwerkverkehr reduzieren, Verarbeitungsprozesse verschlanken und die Performance von geschäftskritischen Workloads verbessern. Dies eliminiert viele der Bandbreiten- und Durchsatzprobleme, die bei einem zentralisierten Rechenzentrum auftreten.
Computational Storage könnte ein Gewinn fūr alle datenintensiven und latenz-empfindlichen Workloads sein, die in einer Edge-Umgebung laufen.
Trotz dieser Vorteile verbinden sich mit Edge Computing auch eine Reihe von Problemen – wie zum Beispiel das Security-Management, die Orchestrierung verteilter Systeme und das Mapping zwischen dem Rechenzentrum und den Edge-Umgebungen. Eines der größten Probleme besteht darin, die Begrenzungen der Compute- und Speicherressourcen wie zum Beispiel Platz- und Ressourcenanforderungen in den Griff zu bekommen. Diese Grenzen können die Maximierung der Performance von datenintensiven Workloads schwierig gestalten, besonders wenn die Datenmengen weiterhin wachsen und komplexer werden.
Aufgrund ihrer besonderen Natur leidet eine Edge-Umgebung oft an verfügbarem Platz, was es schwierig macht, die für heutige moderne Workloads benötigte Ausrüstung unterzubringen. Der verfügbare Platz war eventuell auf einen Schrank, ein Regal oder eine Ecke in einem Büro beschränkt – mit Konsequenzen für Größe, Leistung und Kühlung. Alles in allem wenig im Vergleich zu einem voll ausgebauten Rechenzentrum.
Es kommt außerdem selten vor, dass Edge-Umgebungen mit voll leistungsfähigen Rechenkapazitäten ausgestattet sind, wie man sie in Rechenzentren findet. Obwohl es möglich ist, supermoderne Server am Edge hinzustellen, werden es die IT-Budgets nur selten zulassen – besonders dann, wenn Unternehmen weiter geschäftskritische Workloads in ihren Rechenzentren unterstützen müssen.
Wegen dieser Einschränkungen durchlaufen IT-Teams schwierige Zeiten, die Workload-Performance zu bekommen, die sie in ihren Edge-Umgebungen benötigen. Aber dies hat sie in der Regel nicht daran gehindert, es wenigstens zu versuchen. Einige Teams haben All Flash Storage Arrays, NVMe, GPU-Beschleuniger und andere leistungsfähige Technologien installiert. Obwohl diese etwas geholfen haben, reichen sie nicht für den Grad an Performance aus, den man für die wirksame Unterstützung heutiger anspruchsvoller Workloads braucht.
Ein wichtiger Grund dafür besteht darin, dass konventionelle Compute/Storage-Architekturen von Natur aus bei der Bandbreite der I/O-Ports beschränkt sind, die sich zwischen Speichergeräten und Compute-Ressourcen befinden. Wenn Daten verarbeitet werden, müssen sie diese Verbindungen durchqueren, die nur so schnell sind wie die sie unterstützenden Technologien. Und je mehr Daten sich zwischen Storage und Memory bewegen, desto größer sind die daraus resultierenden Engpässe.
An diesem Punkt betritt Computational Storage die Szene. Es entfernt den Engpass, indem es Compute- und Storage-Ressourcen enger zusammenbringt, um die Datenbewegungen zu verringern. Das Resultat sind niedrigere Latenzzeiten und schnellere Anwendungen.
Computational Storage als Rettung
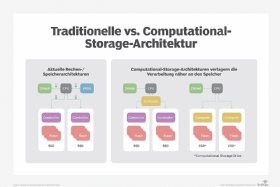
Herkömmliche Compute-Storage-Architekturen erfordern Zeit und Ressourcen, um Daten überhaupt von einem System zu einem anderen zu bewegen, was sich in höherer Latenz und geringer Anwendungs-Performance niederschlägt. Im Gegensatz dazu steht Computational Storage für einen Insight-Ansatz von Datenverarbeitung: Mindestens ein Teil der Betriebsabläufe wird von den Compute-Ressourcen in das Innere des Speichersystems verlegt. Dort können Daten schneller und effizienter verarbeitet werden – nicht nur wegen der geringeren Datenbewegungen, sondern auch wegen des intensiven Gebrauchs von paralleler Datenverarbeitung.
Abbildung 1: Traditionelle und Computational-Storage-Architektur im direkten Vergleich.
Das Speichersystem sorgt für eine Vorabverarbeitung der Daten anstelle des Compute-Systems, so dass schließlich nur eine Teilmenge der Daten zum Memory gesandt wird. Durch die geringeren Datenbewegungen erreicht man niedrigere Anwendungslatenz und reduziert die Belastung der Compute-Ressourcen, wodurch sie für andere Prozesse zur Verfügung stehen.
Computational Storage bietet enorme Vorteile bei den datenintensiven Workloads, die am Edge laufen – besonders für solche, die sich nicht die durch vermehrte Latenzzeiten verursachten Verzögerungen leisten können. Dies gilt zum Beispiel für ein Unternehmen, das eine KI-Anwendung installieren will, die kontinuierlich den Datenfluss analysiert, der in seine Speichersysteme gestreamt wird. Zeitweise können das mehrere Terabytes an Daten pro Stunde sein.
Auf der Anwendungsseite war es die Absicht, die Unternehmen mit automatisch erzeugten Reports einschließlich Überblick in Echtzeit über die laufenden Prozesse zu versorgen. Es überrascht jedoch nicht, dass die Daten in den Reports nur einen Bruchteil der Gesamtmenge an Rohdaten widerspiegeln.
In einem traditionellen Compute-Storage-Modell müssen die Daten ständig vom Speicher zum Memory bewegt werden, sobald neue Daten verfügbar sind. Dies führt zu einer kontinuierlichen Belastung der I/O-Ports und der Rechenkapazitäten. Unter diesen Umständen konnten die Reports leicht zu spät kommen oder nicht benutzte Daten umfassen. Wenn die Analysen jedoch an Ort und Stelle durchgeführt werden, brauchen die Compute-Ressourcen nur die kumulierten Gesamtsummen, um Reports zu erstellen, was wiederum zu schnelleren und effizienteren Betriebsabläufen führt. Dies verringert auch die Auswirkungen auf Netzwerkbandbreite und Compute-Ressourcen und gibt sie für andere Aufgaben frei.
Die neue Welt des Computational Storage
Einige Hersteller bieten nun Systeme für Computational Storage an, darunter Samsung, NGD Systems, ScaleFlux und Eideticom. Es handelt sich noch um einen jungen Industriezweig, und es bleibt dem jeweiligen Hersteller überlassen, wie man am besten Computational Storage einrichtet – was der Systemintegration eine eher chaotische Perspektive verleihen könnte.
Um der Akzeptanz von Computational Storage mehr Gewicht zu verschaffen, sorgt die Storage Networking Industry Association (SNIA) für Standards bei der Interoperabilität solcher Geräte und definiert Schnittstellen für Aufstellung, Versorgung, Management und Sicherheit.
Computational Storage könnte ein Gewinn für alle datenintensiven und latenzempfindlichen Workloads sein, die in einer Edge-Umgebung laufen. Bei Edge Computing wird oft auf IoT-Daten Wert gelegt, die Herkunft der Daten ist jedoch bei Computational Storage nicht das hauptsächliche Problem. Wichtig sind dagegen, die Menge an Daten, wie oft sie ein Update erfahren und was man mit ihnen anfangen möchte. Wenn Unternehmen den Wert von Computational Storage abschätzen, müssen sie es auf der Basis einzelner Fälle tun und entscheiden, ob die Performance-Gewinne die Kosten eines neuen Speicher-Tools wert sind.