
ra2 studio - stock.adobe.com
iproute2 und nftables: Netzwerkverwaltung unter Linux
Unter Linux lassen sich mit iproute2 und nftables Netzwerkschnittstellen, Routingtabellen und Paketfilter direkt steuern. Der Text zeigt Beispiele und Möglichkeiten.
Mit iproute2 und nftables lassen sich Netzwerkverbindungen konfigurieren und Filter setzen. Beide Werkzeuge ersetzen ältere Befehle wie ifconfig, route sowie iptables und ermöglichen eine konsistente, skriptfähige Steuerung aller Netzwerkfunktionen im Kernel. Unter Ubuntu gehören sie zur Standardinstallation, bei einigen anderen Distributionen auch. In Ubuntu greifen zentrale Netzwerkdienste wie systemd-networkd, Netplan und firewalld direkt auf die Funktionen von iproute2 und nftables zu, um Schnittstellen und Filter zu steuern.
Netzwerkkonfiguration mit iproute2
In Ubuntu nutzen systemd-networkd, Netplan und firewalld die Funktionen von iproute2 und nftables zur Steuerung von Schnittstellen und Filtern. Bestandteil des Pakets sind auch ss für die Analyse von Socket-Verbindungen und tc zur Verwaltung von Bandbreiten und Warteschlangen. Beide Werkzeuge ergänzen die Netzwerksteuerung um Diagnose- und Traffic-Control-Funktionen.
Die Übersicht über alle Netzwerkschnittstellen liefert der Befehl
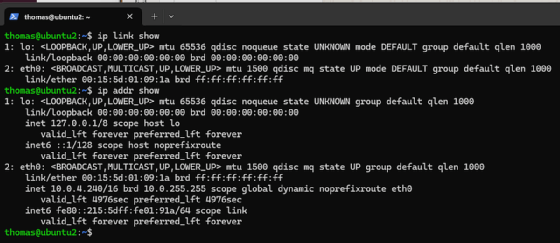
ip link show
Jede Zeile der Ausgabe steht für ein physisches oder virtuelles Interface, beginnend mit der Loopback-Schnittstelle lo. Für die Aktivierung oder Deaktivierung einer Schnittstelle genügt
ip link set dev eth0 up
oder
ip link set dev eth0 down
Mit
ip addr show
werden die zugewiesenen IP-Adressen angezeigt. Eine neue Adresse wird mit
ip addr add 10.0.1.10/24 dev eth0
gesetzt. Sie bleibt bis zum nächsten Neustart bestehen. Soll die Konfiguration dauerhaft bleiben, erfolgt die Integration in die systemd-networkd- oder Netplan-Definitionen.
In produktiven Umgebungen empfiehlt sich eine konsistente Benennung von Schnittstellen. Das Kommando
ip link set dev eth0 name lan0
ändert den Gerätenamen, wenn das Interface inaktiv ist. Die aktuelle MAC-Adresse kann mit
ip link set dev lan0 address 00:1a:2b:3c:4d:5e
festgelegt werden. Damit lassen sich Testumgebungen mit stabilen Adressbezügen aufbauen.
Routing und Netzstruktur
Mit den Tools in iproute2 lassen sich auch Routingstrukturen aufbauen. Der befehl ip route show zeigt die aktuelle Routing-Tabelle. Die Standardroute wird mit
ip route add default via 10.0.0.254 dev eth0
gesetzt. Um den Verkehr zu bestimmten Netzen gezielt zu steuern, lassen sich mehrere Routen anlegen, zum Beispiel
ip route add 10.0.2.0/24 via 10.0.1.1 dev eth1
Für dynamische Tests bietet iproute2 auch temporäre Routen. Nach einem Neustart ist der ursprüngliche Zustand wiederhergestellt. Policy-basiertes Routing erweitert die klassische Steuerung. Es ermöglicht, Netzwerkpakete abhängig von Quelle, Ziel oder Markierungen in unterschiedlichen Routing-Tabellen zu verarbeiten. Neue Tabellen werden in /etc/iproute2/rt_tables eingetragen, zum Beispiel mit der Zeile
200 clients
Anschließend kann ein Eintrag mit
ip route add default via 10.0.2.254 dev eth1 table clients
ergänzt werden. Die Zuweisung erfolgt per Regel:
ip rule add from 10.0.1.0/24 table clients
So können unterschiedliche Netzsegmente getrennt über eigene Gateways arbeiten.
VLANs, Bonding und virtuelle Interfaces
Mit
ip link add link eth0 name vlan100 type vlan id 100
entsteht ein VLAN-Interface. Es ist sofort verfügbar und kann wie ein physisches Interface konfiguriert werden. VLANs trennen logische Netzwerke auf derselben physischen Infrastruktur. So lassen sich interne Bereiche, Managementnetz und externe Verbindungen voneinander abgrenzen, ohne zusätzliche Hardware zu verwenden. Jedes VLAN erhält eine eigene ID und kann unabhängig adressiert oder gefiltert werden.
Die Verbindung mehrerer physischer Ports zu einem logischen Kanal erfolgt über Bonding. Der Befehl
ip link add name bond0 type bond
legt die Struktur an. Anschließend lassen sich die beteiligten Schnittstellen mit
ip link set dev eth1 master bond0
zuordnen. Durch Bonding entsteht ein Verbund, der die verfügbare Bandbreite verteilt und bei Ausfall einer Leitung die Verbindung aufrechterhält. In Serverumgebungen kombiniert ein Bond oft mehrere Gigabit- oder 10-Gigabit-Ports zu einer stabilen, gemeinsamen Schnittstelle, die wiederum VLANs führen kann. So entsteht eine flexible Netzstruktur mit Lastverteilung und Redundanz auf derselben Hardwarebasis.
Zur Verbindung von Containern oder Namespaces wird oft das veth-Paar genutzt.
ip link add veth-a type veth peer name veth-b
erzeugt zwei Endpunkte einer virtuellen Leitung. Jeder Endpunkt kann in einen anderen Namespace verschoben werden, wodurch getrennte Netzwerkstacks miteinander kommunizieren können. In diesem Zusammenhang arbeiten veth-Interfaces wie physische Kabel zwischen logischen Instanzen. Der Datenverkehr, der an einem Ende eintrifft, erscheint am anderen Ende. Diese Struktur ist zentral für Containerumgebungen, da sie Netzwerke isoliert, aber gleichzeitig gezielt verbindet. Ein veth-Paar kann auch in Bridges oder VLANs eingebunden werden und bildet so die Basis vieler Virtualisierungs- und Testnetzwerke unter Linux.
Dummy-Interfaces dienen in Tests als lokale Netzpunkte.
ip link add name dummy0 type dummy
erstellt eine logische Schnittstelle ohne physische Anbindung, nützlich für Managementadressen oder Monitoringzwecke.
Netzwerküberwachung mit ss und tc
Das Programm ss aus dem iproute2-Paket ersetzt netstat. Es zeigt offene Verbindungen, Ports, Protokolle und Sockets in Echtzeit. Der Aufruf
ss -tlnp
listet alle TCP-Ports mit Prozesszuordnung. Für UDP-Verbindungen genügt
ss -ulpn
Traffic Control (tc) steuert die Bandbreite und Priorisierung. Eine Grundbegrenzung auf 10 MBit/s erfolgt mit
tc qdisc add dev eth0 root tbf rate 10mbit burst 32kbit latency 400ms
Für differenzierte Qualitätssicherung kann HTB (Hierarchical Token Bucket) genutzt werden:
tc qdisc add dev eth0 root handle 1: htb default 12
Dazu werden Klassen definiert, die Prioritäten und Raten festlegen, zum Beispiel
tc class add dev eth0 parent 1:1 classid 1:10 htb rate 5mbit prio 1
So lässt sich bestimmter Verkehr, wie SSH oder Datenbankzugriffe, bevorzugt behandeln.
nftables als moderner Paketfilter
Mit nftables lässt sich iptables vollständig ersetzen sowie IPv4- und IPv6-Regeln in einem einheitlichen Syntaxsystem integrieren. Unter Ubuntu ist nftables seit 22.04 das Standard-Backend. Bestehende iptables-Regeln lassen sich über iptables-translate in nftables-Syntax konvertieren.
Die erste eigene Tabelle entsteht mit
sudo nft add table inet firewall
Innerhalb der Tabelle folgt eine Kette:
sudo nft "add chain inet firewall input { type filter hook input priority 0; policy drop; }"
Damit blockiert das System alle eingehenden Pakete, die keine Ausnahmeregel erfüllen.
Neue Regeln werden mit klarer Syntax ergänzt:
sudo nft add rule inet firewall input iifname lo accept
erlaubt lokalen Verkehr.
sudo nft add rule inet firewall input tcp dport 22 ct state new,established accept
erlaubt SSH.
sudo nft add rule inet firewall input ct state established,related accept
sorgt dafür, dass bestehende Verbindungen nicht erneut geprüft werden.
Zur Kontrolle dient
sudo nft list ruleset
Änderungen erfolgen im laufenden Betrieb, ohne Unterbrechung der bestehenden Verbindungen.
NAT und Forwarding
Für die Verbindung zwischen internen und externen Netzen konfiguriert nftables Network Address Translation (NAT). Eine einfache Masquerade-Regel entsteht mit:
sudo nft add table ip nat
sudo nft "add chain ip nat postrouting { type nat hook postrouting priority srcnat; }"
sudo nft add rule ip nat postrouting oif eth1 masquerade
Damit ersetzt nftables die früheren iptables-Zeilen vollständig. Alle ausgehenden Pakete, die das Interface eth1 verlassen, erhalten die externe Adresse dieses Geräts.
Das Forwarding zwischen Interfaces wird mit einer eigenen Kette umgesetzt:
sudo nft "add chain inet firewall forward { type filter hook forward priority 0; policy drop; }"
Freigaben erfolgen gezielt, etwa für HTTP-Verkehr zwischen zwei internen Netzen:
sudo nft add rule inet firewall forward ip saddr 10.0.1.0/24 ip daddr 10.0.2.10 tcp dport 80 accept
Die Kombination aus iproute2 und nftables ermöglicht damit Routing und Paketfilterung in einer vollständig kontrollierten Umgebung.
Logging und Diagnose
Für die Analyse von Netzwerkaktivität bietet nftables integriertes Logging. Eine Regel wie
sudo nft add rule inet firewall input log prefix "DROP: " level warning drop
zeichnet alle verworfenen Pakete mit Kennzeichnung auf. Die Einträge erscheinen in /var/log/kern.log oder über
journalctl -k | grep DROP
Ein gezieltes Logging einzelner Dienste kann über Ports erfolgen, zum Beispiel
sudo nft add rule inet firewall input tcp dport 22 ct state new log prefix "SSH-ATTEMPT: " level notice
Mit Rate-Limits wird eine Überlastung des Logsystems verhindert:
sudo nft add rule inet firewall input limit rate 10/minute log prefix "LIMITED-LOG: " level info drop
Zusammenspiel von iproute2 und nftables
Beide Werkzeuge greifen direkt auf die Netfilter- und Routing-Funktionen des Kernels zu. iproute2 verwaltet die logischen Pfade, nftables kontrolliert die Durchlässigkeit und Priorität der Pakete. In komplexen Szenarien, zum Beispiel bei mehreren Gateways oder VLAN-Strukturen, können beide Systeme parallel konfiguriert werden. Ein typisches Beispiel ist ein Router mit zwei Netzen:
eth0: internes LAN 10.0.1.0/24
eth1: Internetanbindung
Die Konfiguration:
ip addr add 10.0.1.1/24 dev eth0
ip addr add 192.168.0.10/24 dev eth1
ip route add default via 192.168.0.1 dev eth1
sysctl -w net.ipv4.ip_forward=1
Nftables übernimmt den Schutz:
sudo nft add table inet router
sudo nft "add chain inet router input { type filter hook input priority 0; policy drop; }"
sudo nft add rule inet router input iifname lo accept
sudo nft add rule inet router input ct state established,related accept
sudo nft add rule inet router input tcp dport 22 accept
sudo nft "add chain inet router forward { type filter hook forward priority 0; policy drop; }"
sudo nft add rule inet router forward ip saddr 10.0.1.0/24 oif eth1 accept
sudo nft add rule inet router forward ip daddr 10.0.1.0/24 iif eth1 ct state established,related accept
sudo nft add table ip nat
sudo nft "add chain ip nat postrouting { type nat hook postrouting priority srcnat; }"
sudo nft add rule ip nat postrouting oif eth1 masquerade
Damit entsteht ein vollständiges NAT-Gateway mit kontrolliertem Zugriff und klarer Paketlogik.
Namespaces und Virtualisierung
Network Namespaces trennen den Netzwerkstack eines Linux-Systems in eigenständige Instanzen. Jede dieser Instanzen hat eigene Interfaces, Routing-Tabellen, Nachbarschaftseinträge und Firewall-Regeln. Prozesse innerhalb eines Namespaces nutzen ausschließlich die dort verfügbaren Netzressourcen und sind vollständig von anderen Namespaces isoliert. So lassen sich auf einem Host eine Vielzahl unabhängiger Netzumgebungen betreiben, die sich gegenseitig nicht beeinflussen.
Der Befehl
ip netns add ns1
legt einen neuen Namespace an. Dieser verhält sich wie ein eigenes System mit separatem Netzwerkstack. Mit
ip netns exec ns1 bash
kann eine Shell innerhalb des Namespaces geöffnet werden, um dort Netzwerkeinstellungen vorzunehmen. Virtuelle Schnittstellen wie veth-Paare verbinden verschiedene Namespaces miteinander oder binden sie an das Host-System an. Durch diese Architektur lassen sich Container, Testnetzwerke oder Multi-Tenant-Umgebungen aufbauen, die strukturell voneinander getrennt, aber über definierte Verbindungen erreichbar sind. Über virtuelle Schnittstellen lassen sich diese Namespaces verbinden:
ip link add veth1 type veth peer name veth2
ip link set veth1 netns ns1
ip netns exec ns1 ip addr add 10.0.10.1/24 dev veth1
ip addr add 10.0.10.2/24 dev veth2
ip link set dev veth2 up
ip netns exec ns1 ip link set dev veth1 up
Damit können getrennte Netze innerhalb eines Hosts simuliert werden. Zusätzlich lässt sich nftables in jedem Namespace separat betreiben, wodurch unterschiedliche Firewall-Logiken parallel laufen.
Fazit
Die Werkzeuge aus iproute2 und nftables ergänzen sich in der praktischen Netzverwaltung. iproute2 legt die Struktur fest, verwaltet Interfaces, VLANs, Routen und Namespaces. nftables filtert und kontrolliert den Verkehr auf diesen Pfaden. Beide Tools nutzen dieselben Kernelmechanismen und arbeiten direkt mit Netfilter und Networkstack. Dadurch lassen sich Routing, Paketfilterung und Überwachung ohne zusätzliche Frameworks umsetzen. In virtualisierten Umgebungen oder Containern steuert iproute2 die logische Verbindung der Instanzen, nftables setzt gezielte Regeln in jedem Namespace oder an den Übergängen zwischen ihnen setzt. So bleibt die Netzarchitektur kontrollierbar, reproduzierbar und klar getrennt, auch bei komplexen Topologien.





