Getty Images Plus
Wie man ein interaktives DevOps-Runbook entwickelt
Ein Runbook enthält standardisierte Verfahren zur Automatisierung sich wiederholender IT-Prozesse. Dieser umfassende Leitfaden zeigt Best Practices.

Was man nicht messen kann, kann man nicht verbessern – oder optimieren. Übertragen auf die Softwareentwicklung und auf DevOps bedeutet der Spruch: Was man nicht dokumentieren kann, lässt sich auch nicht automatisieren.
Ein DevOps-Experte muss die Schritte – und ihre Reihenfolge – verstehen und beschreiben, die zur Ausführung einer Aufgabe erforderlich sind. Dies ist notwendig, bevor er sie automatisieren kann. Ohne ein umfassendes Verständnis der einzelnen Schritte und des erwarteten Ergebnisses ist es unmöglich, einen wiederholbaren Prozess zu erstellen. Diese Leitlinien sind gute Gründe für DevOps-Unternehmen, ein Runbook zu erstellen.
Was ist ein Runbook?
In einem weiteren Sinn ist ein Runbook eine Zusammenstellung von Routineverfahren und -vorgängen, die der Systemadministrator oder -betreiber ausführt, und die als Referenz verwendet werden. Beispielsweise enthält ein Runbook Verfahren zum Starten, Stoppen, Überwachen und Debuggen des Systems oder Verfahren für die Behandlung von Sonderwünschen und Unvorhergesehenem. Ein Runbook ermöglicht es anderen Anwendern, die über das erforderliche Fachwissen verfügen, ein System effektiv zu verwalten und Fehler zu beheben.
In einem engeren (DevOps-) Sinn ist ein Runbook ein schriftlich verfasstes standardisiertes Verfahren zur Automatisierung sich wiederholender IT-Prozesse, die unter ITIL-Protokolle fallen. Obwohl die Begriffe Runbook und Playbook auf den ersten Blick synonym erscheinen, gibt es im Kontext von DevOps einen klaren Unterschied:
Ein Runbook konzentriert sich auf den Workflow für einen einzelnen Prozess. Ein Playbook hingegen beschreibt alle Reaktionen auf ein viel breiteres Problem. Beispielsweise könnte eine DevOps-Organisation über ein Runbook zum Bereitstellen einer aktualisierten Version einer Anwendung oder eines Service-Containers in einem AWS Kubernetes Pod verfügen.
Im Gegensatz dazu verwenden DevOps-Teams und Site Reliability Engineers (SREs) ein Playbook, um ein System nach einem Ausfall in einer Cloud-Region wiederherzustellen – wie bei dem Ausfall, der AWS US-East Anfang Dezember 2021 für mehr als 8 Stunden außer Betrieb nahm, und bei dem viele Produktionsanwendungen ausgeführt wurden.
Runbooks haben viele Einsatzmöglichkeiten, zum Beispiel:
- Dokumentieren von Prozessen für das IT-Incident-Management und die Fehlerbehebung.
- Verbesserung der Systemzuverlässigkeit und -sicherheit, um Ausfallzeiten zu reduzieren.
- Optimierung von IT- und DevOps-Betriebsaufgaben.
- Bereitstellen von Vorlagen für Automatisierungsroutinen, die manuelle Prozessschritte eliminieren.
In dem Maße, in dem IT-Organisationen manuelle Prozesse durch ausführbaren Code ersetzen, entwickeln sich Runbooks zu einer Mischung aus manuellen und automatisierten Schritten.

Elemente eines DevOps-Runbooks
DevOps-Runbooks kapseln und systematisieren Schritte zur Lösung häufig auftretender Probleme. Sie sollen folgende Merkmale aufweisen:
- Actionable (durchführbar). Runbooks sollen zielgerichtete Schritte formulieren, die zur konkreten Lösung eines Problems erforderlich sind – und nicht hypothetische Gründe dafür.
- Accurate (präzise). Runbooks sollen Verfahren testen und sie auf Genauigkeit und Vollständigkeit überprüfen.
- Authoritative und Unambiguous (maßgeblich und eindeutig). Jedes Runbook soll nur einen Prozess abdecken; es soll außerdem klare Anweisungen für DevOps-Teams enthalten und als Single Source of Truth
- Accessible (zugänglich). Runbooks sollen in direkter Sprache kommunizieren. Anwender greifen oft zu Runbooks, da ein Problem aufgetreten ist. Die Sprache muss einfach zu verstehen, leicht verfügbar und von der Zielgruppe leicht zu finden sein.
- Adaptable (anpassungsfähig). Runbooks sind eine einzige Quelle der Wahrheit, die die Schritte eines Prozesses definiert. Sie müssen aber auch flexibel sein, um sich mit den Erfahrungen aus dem Kontext selbst zu verbessern. Sie sollen in der Lage sein, neue Situationen und Technologien zu berücksichtigen.
Die Erstellung eines DevOps-Runbooks, welches diese Eigenschaften erfüllt, erfordert einen disziplinierten Prozess. Dazu gehören Planung, Recherche, das Schreiben von Code (für automatisierte Routinen), Tests, Feedback, Optimierung und Aktualisierung.
Ein Runbook hat viele Ähnlichkeiten mit einem Kochbuch. Analog wie ein Kochrezept aus mehreren Elementen besteht – einer Liste von Zutaten und deren Mengen, einer Abfolge von Schritten zum Mischen der Zutaten und Anweisungen zum Kochen des Endprodukts – hat auch ein DevOps-Runbook mehrere Komponenten. So wie ein gründlicher Nachrichtenartikel die fünf W des Journalismus ansprechen soll, soll ein Runbook eine ähnliche Reihe von Objekten ansprechen:
Was und wann
Dieser Abschnitt identifiziert und bestätigt das Problem. Er enthält Zeitstempel für eine Aktion oder einen Vorfall und die anschließende Aktivität für eine Lösung. Darüber hinaus beinhaltet er die Tools und Informationsquellen, wie zum Beispiel Überwachungsseiten und Dashboards, sowie Hinweise auf den Ort der Anweisungen zu ihrer Verwendung.
Zu den nützlichen Informationen in diesem Abschnitt gehören:
- Zeitstempel des Vorfalls;
- Nutzungszeiten (zum Beispiel 24/7 oder 10/5)
- Verfügbarkeit des Support-Teams (zum Beispiel 24/7 oder 12/70)
- Zeitfenster für Wartungs- oder Ausfallzeiten
- Verweise auf Tool-Repositories
- Ziele für die Wiederherstellungszeit.
Wer
Dieser Abschnitt enthält eine Liste der Personen, die für die Behebung des Problems zuständig sind. Er enthält Personen auf dem Eskalationspfad, zum Beispiel Second- und Third-Level-Support-Teams. Außerdem sind Kontaktinformationen für die wichtigsten Interessensgruppen gelistet, die von dem Problem betroffen sind, zum Beispiel Geschäftsbereichsleiter oder Anwendungsentwickler.
In diesem Abschnitt werden Informationen gesammelt wie:
- System-, Anwendungs- und Geschäftseigentümer oder -beteiligte
- Eskalationskontakte, sowohl innerhalb des Unternehmens als auch für die Support-Organisationen von Drittanbietern (zum Beispiel Anbieter)
- Geben Sie die bevorzugte Kontaktmethode für alle aufgeführten Parteien an. Beispielsweise Sprachanrufe, Textnachrichten, E-Mail-Listen, Ticket-Systeme oder Webformulare.
- Informationen zur Zugriffsberechtigung und Verfahren für das/die betroffene(n) System(e).
Wo
In diesem Abschnitt listen Sie die Kommunikationskanäle und Informationsquellen für jedes Ereignis oder jeden Vorfall auf. Dies ist häufig ein Ticketsystem oder eine Collaboration-Plattform. Katalogisieren Sie Informationen zum Problem, versuchte Abhilfemaßnahmen, die verwendeten Tools und den Status des Vorfalls sowie einen Bereich zum Posten von Fragen. Weitere wertvolle Daten, die gesammelt werden sollten, sind:
- Links zu Verzeichnissen von relevanten Wissensdatenbanken und zugehörigen Prozessdokumenten, beispielsweise Dokumentationen zum Incident- oder Change-Management.
- Eine detaillierte Beschreibung der System- oder Anwendungsarchitektur, der Schnittstellen und Abhängigkeiten. Wenn Sie zum Beispiel die Schritte zum Debuggen von Problemen mit der Datenbankkonnektivität beschreiben, fügen Sie Details hinzu, zum Beispiel, ob die Datenbank repliziert ist. Wenn ja, klären Sie, wie und wo das Replikat zu finden ist; ob die Datenbank durch Caching-Knoten mit Lastausgleich vorgelagert ist; und die Netzwerkkonfiguration für die Verbindungen zwischen dem Lastausgleich, den Caching-Knoten und der Datenbank.
- Der Speicherort der Protokollaufzeichnungen, zum Beispiel ein Splunk- oder Elastic-Stack-System (früher ELK Stack, was für Elasticsearch, Logstash und Kibana steht), das zur Zusammenfassung relevanter Ereignisprotokolle und Metriken verwendet wird. Fügen Sie hier eine Beschreibung der Überwachungskonfiguration ein und einen Verlauf von Daten, Metriken und Visualisierungen. Oder entsprechende Links.
- Informationen zur Lizenzierung von Software oder Services, Lizenzschlüssel und Authentifizierungsinformationen.
Warum
Führen Sie im Falle eines Ausfalls oder Sicherheitsvorfalls eine nachträgliche Dokumentation und forensische Analyse der ergriffenen Maßnahmen durch. Beschreibungen dieser Maßnahmen müssen bestimmte Schlüsseldaten enthalten. Dies sind:
- Ergebnisse und Wirksamkeit
- Vorschläge zur Verbesserung von Prozessen, Systemen, Sicherheit oder Anwendungen, zum Beispiel für routinemäßige Verwaltungsverfahren
- wie künftige Vorkommnisse verhindert oder abgemildert werden können
Beschreiben Sie zusammenfassend die Folgen – entweder die erwünschten Folgen, im Falle eines administrativen Runbook oder mit Ergebnissen für ein Runbook für Support-Prozesse.
Einige dieser Abschnitte sind für Runbooks, die den Code für die Aufgabenautomatisierung beschreiben, weniger wichtig oder fehlen weitgehend. Für IT-Teams oder Organisationen, die literarische Programmierung verwenden, ist der Code selbstdokumentierend. Er kann durch ein Textverarbeitungsprogramm, normalerweise Markdown oder LaTeX, laufen, um eine lesbare Dokumentation als HTML- oder PDF-Datei zu erstellen.
Arten von Runbooks und ihre Verwendung
Zurück zu unserer Rezeptanalogie: Ein Kochbuch enthält verschiedene Arten von Rezepten. Daraus folgt, dass es viele verschiedene Arten von DevOps-Runbooks gibt. Runbooks decken Aufgaben ab wie:
- Systemmanagement, Konfigurations- und Bereitstellungsprozesse
- Infrastruktur- und Anwendungsüberwachung, Leistungsmessung und Alarmierung
- Sicherheitsprozesse sowie Autorisierungs- und Zugriffskontrollen
- Wiederherstellung bei System-, Anwendungs- und Infrastrukturausfällen
Der letzte Punkt veranschaulicht die Schnittstelle zwischen Runbooks und Playbooks. So fällt beispielsweise die Wiederherstellung nach einem Hardwareausfall oder einem Anwendungsabsturz genau in den Bereich eines Runbooks. Ein Disaster-Recovery-Prozess, der den Massenausfall vieler Systeme – oder einer ganzen Einrichtung – umfasst, wird jedoch besser von einem Playbook abgedeckt. Dieses kann sowohl DevOps-Runbooks als auch andere Elemente wie Kommunikations-, Personal- oder HR-Pläne enthalten.
Runbooks lassen sich in zwei große Kategorien einteilen: präskriptiv und reaktiv. Während beide Kategorien Prozesse für eine bestimmte Situation bereitstellen, beschreiben erstere eine administrative Aufgabe. Diese Aufgabe ist in einer definierten Reihe von Schritten in einer präzisen Reihenfolge auszuführen, wodurch sie sich für die programmgesteuerte Automatisierung eignen.
Die Struktur wird häufig als Entscheidungsbaum dargestellt. Dabei sind einige der Schritte als logische Entscheidungen konstruiert – wenn X wahr ist, folge Zweig A, sonst folge Zweig B –, die den Prozessablauf steuern. Ein Runbook für die Erstellung einer AWS Virtual Private Cloud könnte zum Beispiel in Terraform HCL kodifiziert werden, um die Aufgabe der AWS-Netzwerkerstellung zu standardisieren und zu automatisieren.
Im Gegensatz dazu werden reaktive Runbooks üblicherweise für Support-Prozesse verwendet. Sie steuern das Verständnis, die Eingrenzung des Problems, die Lösung und die Post-Mortem-Analyse von Problemen. Solche Runbooks lassen sich weniger gut automatisieren und ähneln eher einer Bedienungsanleitung als prozeduralem Code. Ein Runbook für die täglichen Aufgaben eines Systemadministrators ähnelt beispielsweise der Checkliste eines Piloten vor dem Flug und können folgende Kategorien enthalten:
- Überprüfen Sie kritische Warnmeldungen
- Überprüfen Sie, ob Prozesse oder Automatisierungsskripte hängen
- Überprüfen Sie die Protokolldateien
- Systemprotokolle
- Anwendungsprotokolle
- Sicherheitsprotokolle
- Login-Aktivitäten
- Überprüfen Sie die Systemmetriken und Dashboards
- Ressourcennutzung und Ausnahmen
- Verfügbarer Speicherplatz
- Hardwarealarme oder Fehlerbedingungen
- Überprüfen Sie den Status der täglichen Systemsicherungen
Beschreibende, prozedurale Runbooks sind eine Voraussetzung für programmgesteuerte Automatisierung und vereinfachen die Umwandlung manueller Aufgaben in automatisierte Prozesse.
Vom Runbook zum Automatisierungsskript
Workflow-Runbooks eignen sich am besten für die Automatisierung, weil sie eine Reihe von Eingaben durch einen expliziten Prozess laufen lassen, um ein bestimmtes Ergebnis zu erzielen. Daher lassen sich solche Runbooks leicht durch prozedurale Sprachen beschreiben. Wenn das Ziel ein automatisiertes Skript ist, kann es sich um nichts anderes als Programmcode handeln. Programmatische Runbooks werden oft über eine CI/CD-Toolchain zusammengefügt, die es IT-Administratoren ermöglicht, einen gesamten Workflow zu automatisieren. Dies kann zum Beispiel das Kompilieren, Integrieren und Bereitstellen einer Anwendung vom Code-Repository in die Cloud-Umgebung sein.
Automatisierte Runbooks sind so weit verbreitet, dass sie eine Reihe von Cloud-Services hervorgebracht haben. Dazu gehören beispielsweise AWS System Manager oder Microsoft Endpoint Configuration Manager sowie Tools wie Document Builder.
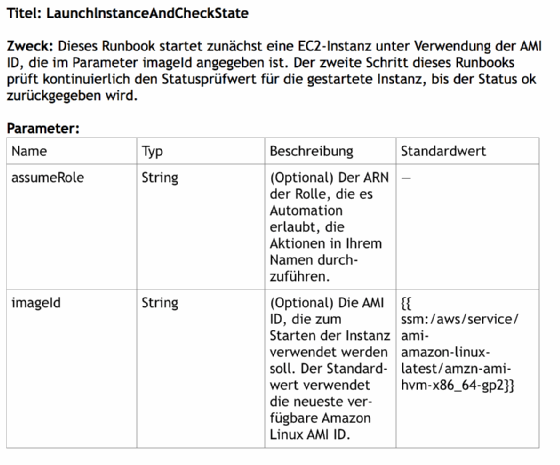
DevOps-Teams können Python-, JSON- oder YAML-Code mit Markdown-Beschreibungen verwenden, um in Document Builder selbstdokumentierende Automatisierungsskripte zu erstellen. Der folgende Markdown- und Python-Code startet zum Beispiel eine Amazon EC2-Instanz und wartet darauf, dass der Status der Instanz auf ok wechselt.
## Titel: LaunchInstanceAndCheckState
**Zweck**: Dieses Runbook startet zunächst eine EC2-Instanz unter Verwendung der im Parameter ```imageId`` angegebenen AMI ID. Der zweite Schritt dieses Runbook kontrolliert kontinuierlich den Statusprüfwert für die gestartete Instanz, bis der Status ```ok`` zurückgegeben wird.
## Parameter:
Name | Type | Description | Default Value
------------- | ------------- | ------------- | -------------
assumeRole | String | (Optional) Der ARN der Rolle, die es Automation erlaubt, die Aktionen in Ihrem Namen durchzuführen. | -
imageId | String | (Optional) Die AMI ID, die zum Starten der Instanz verwendet werden soll. Der Standardwert verwendet die neueste verfügbare Amazon Linux AMI ID. | {{ ssm:/aws/service/ami-amazon-linux-latest/amzn-ami-hvm-x86_64-gp2 }}
def launch_instance(events, context):
import boto3
ec2 = boto3.client('ec2')
image_id = events['image_id']
tag_value = events['tag_value']
instance_type = events['instance_type']
tag_config = {'ResourceType': 'instance', 'Tags': [{'Key':'Name', 'Value':tag_value}]}
res = ec2.run_instances(ImageId=image_id, InstanceType=instance_type, MaxCount=1, MinCount=1, TagSpecifications=[tag_config])
instance_id = res['Instances'][0]['InstanceId']
print('[INFO] 1 EC2-Instanz wurde erfolgreich gestartet', instance_id)
return { 'InstanceId' : instance_id }
Die Markdown-Beschreibung wird in formatierten Text umgewandelt, wie in Abbildung 2 zu sehen.