
kunakorn - stock.adobe.com
SIP und RTP: VoIP-Fehlerbehebung anhand von Praxisbeispielen
Oft liegen die Ursachen für Telefonie-Probleme tiefer im Netz versteckt. Anhand echter Szenarien erfahren Sie, wie Sie bei der Suche vorgehen sollten, um Zeit und Nerven zu sparen.

In diesem letzten Teil unserer Artikelserie stellen wir einige Fehlerszenarien aus der Praxis mit den jeweils angewandten Troubleshooting-Methoden und Lösungen vor. Sie sind exemplarisch und können daher nicht alle möglichen Fehler abdecken. Die Screenshots wurden im Labor und auf Testkomponenten nachgestellt. Zudem stellt das dargestellte Vorgehen lediglich eine von mehreren möglichen Varianten dar. Je nach eingesetzten Komponenten und vorhandenen Werkzeugen können unterschiedliche Herangehensweisen erforderlich sein.
Fallbeispiel 1: Keine ausgehenden Anrufe nach Ersteinrichtung von PBX und SBC
Unser erstes Szenario befasst sich mit einem Fehlerbild, bei dem laut Meldung des Kunden im laufenden Betrieb von einem auf den anderen Tag keine Anrufe nach Extern mehr möglich waren. Eingehende Anrufe konnte der Kunde jedoch empfangen.
Vom Kunden ließen wir zunächst prüfen, ob das genannte Verhalten nur eine Nebenstelle als A-Teilnehmer oder alle internen Nutzer betrifft oder ob sich der Fehler auf bestimmte Endgerätearten, wie einen Hardware-Telefontyp oder Softphones, einschränken lässt. Zudem fragten wir, ob nur eine oder alle B-Teilnehmer betroffen sind und ob das Fehlerbild zeitweise oder permanent auftritt. Außerdem erbaten wir eine aktuelle Netzwerkübersicht gemäß dem OSI-Modell (Sitzungsschicht 5 mit den Komponenten für die SIP-Signalisierung und RTP). Der Kunde meldete, dass der Fehler permanent und unabhängig von der Geräteart bei allen Nutzern auftrete. Er betraf auch unterschiedliche Gegenstellen als B-Teilnehmer. Intern trat der Fehler nicht auf.
Kommen wir nun zur Vorgehensweise und der angewandten Methode. Auf Basis der Netzwerktopologie in Abbildung 1 und aufgrund der Kundenmeldung, dass der Fehler bei internen Gesprächen nicht auftrete und alle internen Teilnehmer sowie alle externen Gegenstellen betroffen seien, entschieden wir uns, am Enterprise Session Border Controller (E-SBC) zu beginnen, da dieser sich am Netzübergang zwischen internem und externem Netz befand.
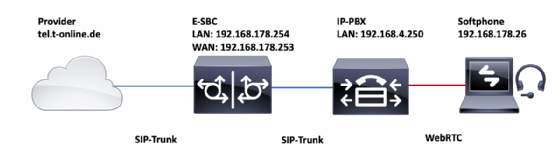
Wir entschieden uns für die Top-down-Methode, da wir aufgrund der Meldung, dass eingehende Gespräche korrekt funktionieren, zunächst einen Fehler auf den oberen drei Schichten beziehungsweise konkret in der SIP-Signalisierung vermuteten.
Da es im Fehlerfall nicht zu einer Sprachübertragung kam, schieden die Schichten 6 und 7 sofort aus. Die Schicht 6 könnte höchstens indirekt einen Einfluss bei der Aushandlung des Audio-Codecs im SDP im SIP-Body gehabt haben. Wir beschlossen, die SIP-Signalisierung auf dem E-SBC zu analysieren. Diese Analyse ergab bei ausgehenden Anrufen, wie in Bild 2 dargestellt, ein 403 Forbidden vom Provider.
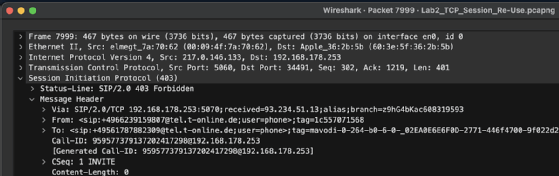
Da die zugehörige SIP-Registrierung korrekt funktionierte, was sowohl an 200-OK-Antworten auf die REGISTER-Anfragen als auch an den korrekt funktionierenden eingehenden Anrufen erkennbar war, konnten wir einen Fehler in den Authentifizierungsdaten ausschließen. Dies war auch daran zu erkennen, dass der Provider nicht mit der Antwort 407 Proxy Authentication Required reagierte, die normalerweise als sogenannte Authentifizierungs-Challenge dient. Er antwortete direkt auf die INVITE-Anfrage mit 403 Forbidden.
Anschließend schauten wir uns den INVITE an und verglichen die Header- und SDP-Informationen mit den Vorgaben aus der Schnittstellenbeschreibung des Providers. Auch hier konnten wir jedoch keinerlei Auffälligkeiten feststellen. Testweise verglichen wir ebenso die Inhalte eines funktionierenden eingehenden Anrufs auf Basis des zugehörigen INVITE mit unserem nicht funktionierenden ausgehenden INVITE. Auch hierbei stellten wir keine Auffälligkeiten in den Inhalten unseres INVITE fest.
Daraufhin entschieden wir, noch eine weitere Schicht im OSI-Modell hinunterzugehen, zur Transportschicht (4). Da wir jedoch auf der Sitzungsschicht eine SIP-403-Antwort erhielten, konnten wir bereits ausschließen, dass es sich um ein Firewall-Problem auf dem Transportweg handelte.
Wir erstellten einen Paketmitschnitt über ein Allegro Network Multimeter an der öffentlichen Schnittstelle des E-SBC in Richtung Provider. Die Auswertungen nahmen wir im grafischen Tool Wireshark vor. Da die SIP-Registrierungen korrekt funktionierten, verglichen wir daraufhin auf Schicht 4 den negativen INVITE mit den positiven REGISTER-Anfragen. Dabei fiel auf, dass der Quellport zwischen REGISTER und INVITE abwich.
Daraufhin konsultierten wir die Schnittstellenbeschreibung des Providers, also in diesem Fall die 1TR118 der deutschen Telekom. Aus ihr ging hervor, dass der Kunde bestehende TCP- und TLS-Verbindungen zwingend für weitere SIP-Nachrichten nutzen muss. Wir hatten also bereits einen bestehenden Socket für die Registrierung. Jedoch versuchte der E-SBC einen zusätzlichen Socket für den neuen Dialog aufzubauen. Der Provider nahm den Socket-Aufbau selbst noch an, blockte jedoch auf Applikationsebene die über den zweiten Socket übertragenen SIP-Requests mit der SIP-403-Antwort.
Der Root Cause des Fehlers lag also darin, dass ein neuer Quellport für die Signalisierung verwendet wurde. Der Provider verlangt jedoch gemäß seiner Schnittstellenbeschreibung, dass das Kundenequipment bestehende TCP-Sockets für den Versand neuer SIP-Nachrichten nutzen muss. Zusätzliche Sockets erlaubte der Provider nicht. Ähnliche Fehlerbilder können auch bei multiplen WAN-Anbindungen vorkommen. In diesem Fall ist es sinnvoll, die SIP- und RTP-Daten an eine WAN-Anbindung zu koppeln und nur im Ausfallszenario komplett darauf zu schwenken.
Im konkreten Fall mussten wir auf dem Anrufabschnitt in Richtung des Providers einen sogenannten Session Re-Use aktivieren. Dies kann je nach eingesetztem E-SBC unterschiedlich implementiert sein.
Nach jedem Troubleshooting-Schritt dokumentierten wir die durchgeführten Tätigkeiten und zugehörigen Ergebnisse, um Dopplungen im Troubleshooting-Prozess zu vermeiden. Zudem dokumentierten wir den Root Cause sowie die initiale Kundenmeldung, um sie für zukünftige Störungsmeldungen und eine eventuelle Hinterlegung in einer Knowledge Base vorzuhalten.
Artikelserie zum SIP- und RTP-Troubleshooting
Der erste Beitrag dieser Artikelserie befasst sich mit dem Aufbau des SIP- und RTP-Protokolls sowie Dialogen und Transaktionen. Der zweite Beitrag konzentriert sich auf die Tools für das VoIP-Troubleshooting. In Teil 3 geht es um konkrete Methoden und die Planung für ein effizientes und effektives Troubleshooting. Dieser vierte Teil veranschaulicht die Fehlerbehebung anhand von Beispielen aus der Praxis.
Fallbeispiel 2: Schlechte Gesprächsqualität
Im zweiten Fallbeispiel meldete der Kunde eine schlechte bidirektionale Gesprächsqualität. Der Gesprächsaufbau und die Beendigung funktionierten hingegen problemfrei.
Wie bereits im vorherigen Beispiel forderten wir eine Netzwerktopologie der Umgebung an. Zudem sollte das Systemhaus einen Paketmitschnitt auf betroffenen Clients erstellen. Da das Personal vor Ort jedoch auf den Clients keine zusätzliche Drittanbieter-Software nachinstallieren durfte und keine direkten administrativen Zugriffe auf die Clients möglich waren, wurde der Mitschnitt über tcpdump auf der PBX erstellt, die auch Media Relay aktiviert hatte. Unter Media Relay auf der PBX versteht man eine Funktion, die den Sprachdatenstrom über eine Anpassung des SDP über die PBX leitet, anstatt darin direkt die Medienendpunkte anzugeben. In Folge kann die PBX auch ein Interworking vornehmen, wie beispielsweise zwischen verschlüsselten Sprachdaten auf einem Anrufabschnitt und unverschlüsselten auf einem anderen.
Anhand der vorliegenden Topologie untersuchten wir in der bereitgestellten pcap-Datei gezielt die RTP-Daten, da wir keinen Fehler in der SIP-Signalisierung erkennen konnten. Hierzu verwendeten wir in Wireshark zunächst den Display-Filter rtp. Im Nachgang ließen wir uns die RTP-Streams mit den Metadaten unter dem Menüpunkt Telefonie/RTP/RTP-Streams anzeigen, wie in Abbildung 3 zu sehen.
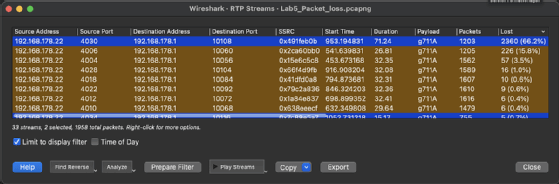
Wir nutzten dabei die Sortierung in der Spalte Lost, um uns die schlechtesten Anrufe gemäß dem höchsten prozentualen Anteil an Paketverlusten zuoberst anzeigen zu lassen und folglich zu erkennen, ob es Anrufe mit Überschreitung der Schwellenwerte von einem Prozent gab. Dabei erkannten wir, dass der RTP-Stream mit dem Synchronization Source Identifier (SSRC) 0x491feb0b die schlechtesten Werte hatte. Um nun den konkreten Anruf dazu zu ermitteln und zu validieren, ob wir damit auch einen problematischen Anruf gefunden hatten, filterten wir anhand des genutzten UDP-Ports im SDP. Der Austausch erfolgt nämlich zuvor über das SDP. Konkret wandten wir den Anzeigefilter sdp.media.port == 10108 or sdp.media.port == 4030 an. Aus den Header-Daten konnten wir in Folge die SIP-Call-ID ermitteln. Diese lautete IIx4P9gBPvGrdOALxOQ7VDHEeHxzFg3m. Um alle Signalisierungspakete zu erhalten, filterten wir anschließend über den Display-Filter sip.Call-ID == "IIx4P9gBPvGrdOALxOQ7VDHEeHxzFg3m". Anhand der ermittelten Rufnummer aus den SIP-Header-Daten fragten wir bei den betroffenen Anwendern ab, ob dies einer der problematischen Anrufe war, was bestätigt wurde.
Da wir eingehend bereits am Router vom Client her Paketverluste erkannten, mussten wir unabhängig vom Client noch einen weiteren Mitschnitt zwischen Endgerät und Switch erstellen. Es stellte sich jedoch heraus, dass die Client-Verbindung im Fehlerfall per WLAN stattfand. Also erstellten wir mittels der Ausleitung an einem TAP einen Mitschnitt zwischen Switch und dem WLAN-Access-Point, mit dem einer der betroffenen Clients verbunden ist. Auch in diesen Mitschnitten erkannten wir, dass wir bereits eingehend vom WLAN-Access-Point Paketverluste erhielten.
Es lag also nahe, dass wir einen Schicht-1-Fehler in der WLAN-Übertragung hatten. Daher warfen wir einen Blick auf den Wireless LAN Controller, der die WLAN-Access-Points verwaltet, um zu erkennen, wie die Verbindungsparameter des betroffenen Clients aussahen. Der betroffene Client hatte konkret einen schlechten Radio Signal Strength Indicator (RSSI), also die eingehende Signalstärke vom Client zum WLAN-Access-Point war zu gering.
Ein daraufhin durchgeführter Post Deployment WLAN Site Survey förderte zutage, dass die WLAN-Access-Points falsch positioniert worden waren und in Folge in Teilbereichen die WLAN-Signalstärke zu gering war. Es wurden im Rahmen des Post Deployment WLAN Site Survey zusätzliche Punkte für WLAN-Access-Points festgelegt und nach Vorbereitung der strukturierten Datenverkabelung/Nachverkabelung entsprechend das WLAN um zusätzliche Access Points ergänzt.
Fallbeispiel 3: Gespräche brechen ab
In unserem Dritten und letzten Beispiel meldete der Kunde, dass alle Gespräche nach 30 Minuten abbrechen. Es erfolgte jeweils ein Besetzt, als ob die Gegenstelle aufgelegt hätte, was sie aber nicht tat. Wie in den vorherigen Beispielen forderten wir wieder eine Netzwerktopologie und Mittschnitte von mehreren Teilen eines fehlerhaften Anrufs an.
Wir fügten die Mitschnitte mit dem in der Wireshark-Installation integrierten CLI-Tool mergecap zusammen und analysierten sie anhand der bereitgestellten Topologie mit Wireshark. Über Telefonie/VoIP Calls in Wireshark ließen wir uns alle Anrufe anzeigen und selektierten die relevanten Call Legs/Anrufabschnitte , indem wir die STRG-Taste gedrückt hielten und auf die Call Legs klickten. Im Nachgang gingen wir über Flow Sequence auf die Anzeige des Call-Flows.
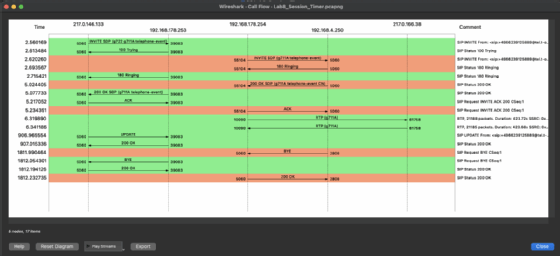
Anhand des Call-Flow-Diagramms erkannten wir, wie in Bild 4 zu sehen, dass die initiale BYE-Nachricht vom E-SBC zur IP-PBX ca. 30 Minuten (1.800 Sekunden) nach erfolgreichem Gesprächsaufbau erfolgte. Die Ursache dieser BYE-Nachricht erfuhren wir bei näherer Betrachtung des Protokollbaums der BYE-Nachricht in Wireshark. In der Begründung im Reason-Header erkannten wir ein Recovery on timer expiry. Dies bedeutet, dass der Session-Expires Timer abgelaufen, aber nicht aufgefrischt worden war und daher der E-SBC die Verbindung beendete.
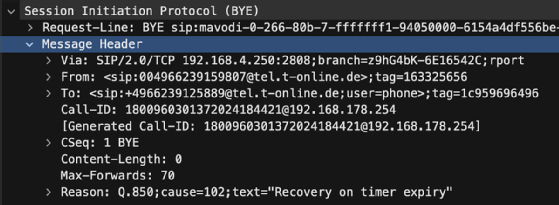
Nun ist jedoch die Frage, wer die sogenannte Refresher-Nachricht hätte senden müssen. Dies verrät jeweils die 200-OK-Nachricht zur Gesprächsannahme. In ihr ist im Wert des Session-Expires-Headers neben der Angabe der Zeit in Sekunden auch der Refresher, also derjenige der die Session auffrischen muss, angegeben. Dieser kann den Wert User Agent Client (UAC) oder User Agent Server (UAS) enthalten. UAC bedeutet, dass der Anrufer (A-Teilnehmer) auf dem jeweiligen Anrufabschnitt auffrischen muss. Bei UAS muss hingegen der Angerufene (B-Teilnehmer) auf dem Anrufabschnitt auffrischen.
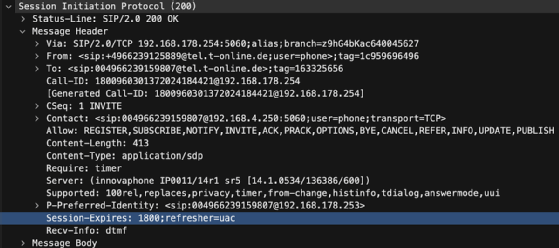
Auf dem externen Call Leg zwischen Provider und E-SBC erkannten wir nach der Hälfte des Session-Timers eine UPDATE-Nachricht, zwischen E-SBC und IP-PBX jedoch nicht. Bei beiden stellten wir den UAC als definierten Refresher fest. Folglich hätte der E-SBC eine Refresher-Nachricht, wie beispielsweise einen INVITE oder ein UPDATE, senden müssen, was er nicht tat. In Folge beendete die IP-PBX die Verbindung.
Die Ursache lag darin, dass UPDATE- und RE-INVITE-Nachrichten auf dem E-SBC in Richtung PBX nicht erlaubt gewesen waren. Folglich konnte kein Session Refresh erfolgen. In den IP-Profilen des E-SBC musste der Systemintegrator zur Lösung in Richtung IP-PBX UPDATE- und Re-INVITE-Nachrichten freigeben.
Fazit
Die Praxisbeispiele zum SIP- und RTP-Troubleshooting zeigen, wie wichtig eine strukturierte und methodische Herangehensweise bei der Fehlerbehebung in VoIP-Umgebungen ist. Die vorgestellten Fallstudien verdeutlichen, dass Störungen oft nicht auf den ersten Blick erkennbar sind und eine systematische Analyse erfordern.
Ein zentraler Erfolgsfaktor ist der Einsatz geeigneter Werkzeuge wie Wireshark, mit dem sich Paketmitschnitte auswerten und SIP-Signalisierung, als auch RTP-Streams analysieren lassen. Diese Tools helfen nicht nur, technische Probleme zu identifizieren, sondern auch, die Ursachen für schlechte Gesprächsqualität oder abgebrochene Verbindungen nachzuvollziehen. Die Beispiele zeigen zudem, wie wichtig es ist, die Schnittstellenbeschreibungen der Provider genau zu kennen, da Abweichungen zu unerwarteten Fehlern führen können.
Ein weiterer entscheidender Aspekt ist die zugrunde liegende Infrastruktur: Oft liegen die Ursachen für Störungen nicht in der SIP-Signalisierung selbst, sondern in der Netzwerkinfrastruktur, wie etwa einer unzureichenden WLAN-Signalstärke oder falsch konfigurierten Firewall-Regeln. Daher ist es ratsam, bei der Fehleranalyse auch die physische und logische Netzwerkumgebung zu berücksichtigen.
Zusammenfassend lässt sich sagen, dass SIP- und RTP-Probleme oft von multiplen Faktoren abhängen. Eine Kombination aus technischem Know-how, methodischem Vorgehen und praktischer Erfahrung ist daher unerlässlich, um Störungen effektiv und effizient zu beheben und die Kommunikation stabil zu halten. Die vorgestellten Vorgehensweisen bieten dabei wertvolle Ansätze, die sich auch auf andere Fehlerbilder in VoIP-Umgebungen übertragen lassen.


